词向量模型Word2vec原理
目录
-
- 1、词向量简介
- 2、Word2vec简介
- 3、Word2vec详细实现
- 4、CBOW模型
- 5、Skip-gram模型
- 6、 CBOW与skip-gram对比
- 7、参考
1、词向量简介
用词向量来表示词并不是word2vec的首创,在很久之前就出现了。最早的词向量是很冗长的,它使用的词向量维度大小为整个词汇表的大小,对于每个具体的词汇表中的词,将对应的位置置为1。比如我们有下面的5个词组成的词汇表,词"Queen"的序号为2, 那么它的词向量就是(0,1,0,0,0)。同样的道理,词"Woman"的词向量就是(0,0,0,1,0),这种词向量的编码方式我们一般叫做1-of-N representation或者one hot representation。
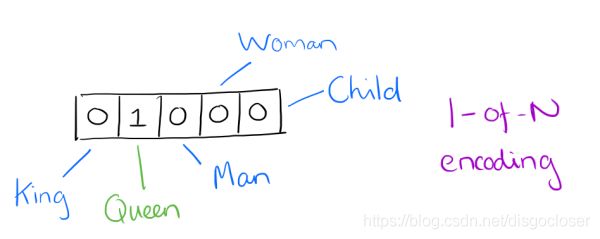
One hot representation用来表示词向量非常简单,但是却有很多问题。最大的问题是我们的词汇表一般都非常大,比如达到百万级别,这样每个词都用百万维的向量来表示简直是内存的灾难。这样的向量其实除了一个位置是1,其余的位置全部都是0,表达的效率不高,能不能把词向量的维度变小呢?
Distributed representation可以解决One hot representation的问题,它的思路是通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。
2、Word2vec简介
词向量将自然语言转换成了计算机能够理解的向量。相对于词袋模型、TF-IDF等模型,词向量能抓住词的上下文、语义,衡量词与词的相似性,在文本分类、情感分析等许多自然语言处理领域有重要作用。
3、Word2vec详细实现
word2vec的详细实现,简而言之,就是一个三层的神经网络,如下图所示:
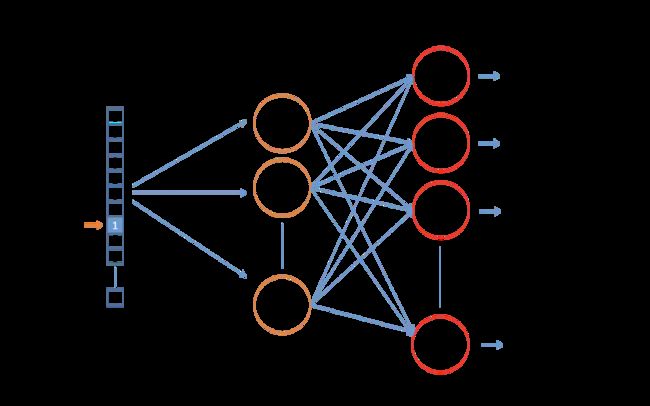
假设,词库里的词数为10000,词向量的长度为300。
输入层:输入为一个词的one-hot向量表示。这个向量长度为10000。假设这个词为ants,ants在词库中的ID为i,则输入向量的第i个分量为1,其余为0。
隐藏层:隐藏层的神经元个数就是词向量的长度,隐藏层的参数是一个[10000 ,300]的矩阵。经过隐藏层,实际上就是把10000维的one-hot向量映射成了最终想要得到的300维的词向量。

输出层:输出层的神经元个数为总词数10000,参数矩阵尺寸为[300,10000]。词向量经过矩阵计算后再加上softmax归一化,重新变为10000维的向量,每一维对应词库中的一个词与输入的词(在这里是ants)共同出现在上下文中的概率。
上述步骤是一个词作为输入和一个上下文中的词作为输出的情况,但实际情况显然更复杂,什么是上下文呢?用一个词去预测周围的其他词,还是用周围的好多词来预测一个词?这里就要引入实际训练时的两个模型skip-gram和CBOW。
4、CBOW模型
如果是拿一个词语的上下文作为输入,来预测这个词语本身,则是 『CBOW 模型』。
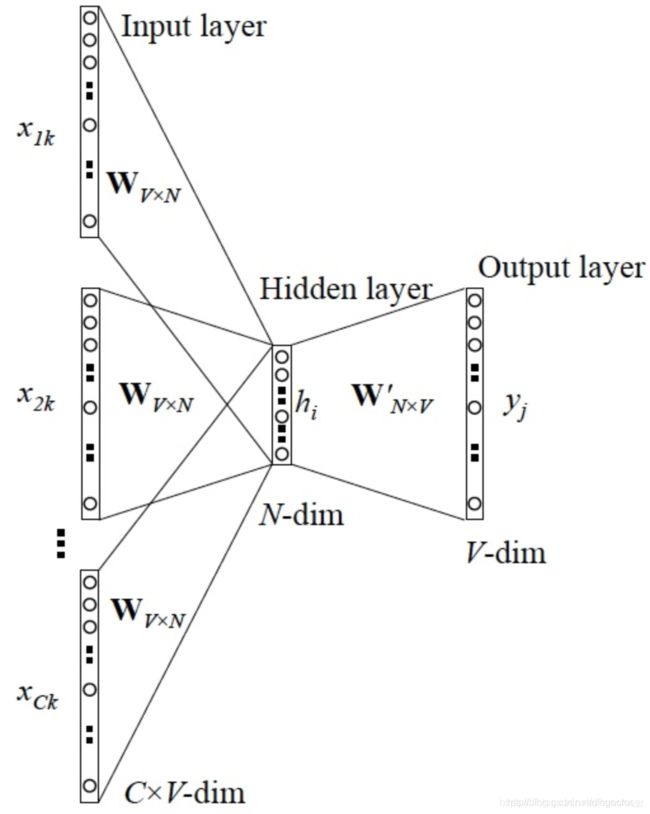
上图中,输入就是有x1k、x2k、…、xck这些上下文词语共C个,每一个的长度是V,输出就是 y 这个中心词1个,长度也是V。在这个网络中我们的目的不是跟一般的神经网络一样去预测标签,而是想要得到完美的参数:权重,X和这个权重相乘能够唯一的表示这个词语。这个词向量的维度(与隐含层节点数一致)一般情况下要远远小于词语总数 V 的大小,所以 Word2vec 本质上是一种降维操作。
训练样本构建:
每一次中心词的移动,只能产生一个训练样本。如果还是用上面图2的例子,则CBOW模型会产生下列4个训练样本:
([quick, brown], the)
([the, brown, fox], quick)
([the, quick, fox, jumps], brown)
([quick, brown, jumps, over], fox)
注:input很可能是4个词,label只是一个词,怎么办呢?只要求平均就行了。经过隐藏层后,输入的4个词被映射成了4个300维的向量,对这4个向量求平均,然后就可以作为下一层的输入了。
CBOW使用的是词袋模型:
将所有词语装进一个袋子里,不考虑其词法和语序的问题,即每个词语都是独立的。例如【Jane wants to go to Shenzhen】与【Bob wants to go to Shanghai】,就可以构成一个词袋,袋子里包括Jane、wants、to、go、Shenzhen、Bob、Shanghai。假设建立一个数组(或词典)用于映射匹配
[Jane, wants, to, go, Shenzhen, Bob, Shanghai]
那么上面两个例句就可以用以下两个向量表示,对应的下标与映射数组的下标相匹配,其值为该词语出现的次数
[1,1,2,1,1,0,0]
[0,1,2,1,0,1,1]
训练过程:
输入是N个词向量,输出是所有词的softmax概率,训练的目标是期望训练样本特定词对应的softmax概率最大。
5、Skip-gram模型
如果是用一个词语作为输入,来预测它周围的上下文,那这个模型叫做『Skip-gram 模型』。
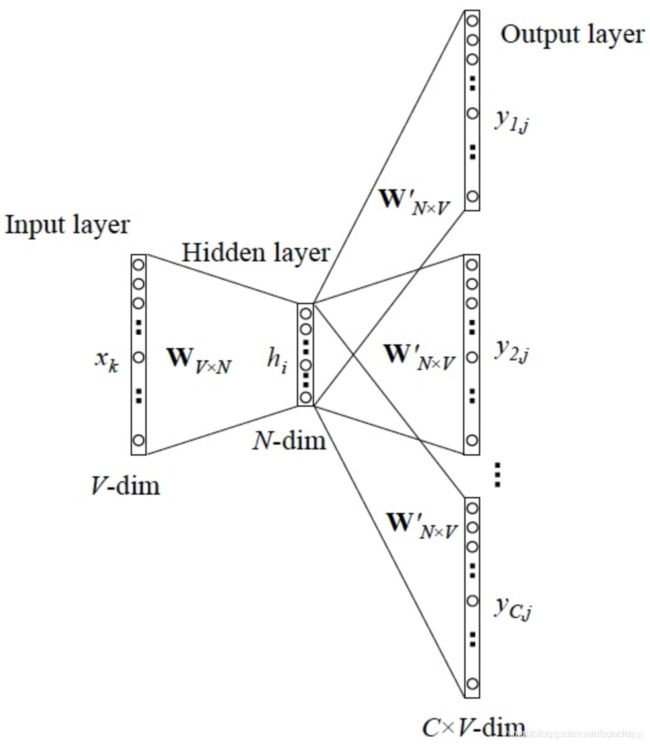
训练样本构建:假设中心词是cat,窗口长度为2,则根据cat预测左边两个词和右边两个词。这时,cat作为神经网络的input,预测的词作为label。下图2为一个例子:

注:在这里窗口长度为2,中心词一个一个移动,遍历所有文本。每一次中心词的移动,最多会产生4对训练样本(input,label)。
训练过程:
输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。可以通过一次DNN前向传播算法得到概率大小排前N的softmax概率对应的神经元所对应的词即可。
6、 CBOW与skip-gram对比
两个模型相比,skip-gram模型能产生更多训练样本,抓住更多词与词之间语义上的细节,在语料足够多足够好的理想条件下,skip-gram模型是优于CBOW模型的。在语料较少的情况下,难以抓住足够多词与词之间的细节,CBOW模型求平均的特性,反而效果可能更好。
7、参考
https://www.jianshu.com/p/b779f8219f74
https://blog.csdn.net/huacha__/article/details/84068653
https://www.cnblogs.com/pinard/p/7160330.html