大数据计算系统 Blink 在端侧的应用实践

本文主要介绍了端侧通过Blink任务对埋点数据进行实时聚合和清洗,解决端侧日志时效性问题,并基于实时日志搭建线上监控运维体系,从而提升端侧整体的稳定性。

Blink简介
介绍 Blink 前需要先认识下 Flink,其最初是柏林工业大学的一个研究性项目(StratoSphere),早期专注于批计算,于2014年捐赠给 Apache 并进行孵化,后逐渐演变为数据计算框和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 计算框架的核心是Flink Runtime 执行引擎,也是一个分布式系统,可运行在所有常见的集群环境中,它将大型计算任务分成许多小的部分每个机器执行一部分,以内存执行速度和任意规模来执行计算。
而Blink 最初是阿里巴巴内部的 Flink 版本代号,是实时计算部门基于内部应用场景对 Flink 做了大量的优化和稳定性改造后的内部产品,在经过内部大规模应用和历年双11的实践与打磨,最终决定将其捐赠给 Flink 社区,成为 Flink 的一部分。
值得一提的是,在大数据计算领域,批处理与流处理是两种常见的任务类型,常见的大数据处理框架只支持一种类型的任务,而 Flink 认为一切数据都是由流组成的,离线数据是有界限的流,实时数据是没有界限的流。基于其强大灵活的处理引擎,Flink 能够同时支持批处理和流处理两种应用场景:
有界数据:数据在指定的时间段内,是批处理的应用场景,需要对完整数据进行计算。类似的处理框架还有 Hadoop MapReduce、Hive等。
无界数据:数据没有时间的界限,所处理的数据是源源不断输入的,如消息队列、分布式日志这类流式数据源等。程序需要对传输的数据进行持续操作即实时计算。类似的处理框架还有 Storm、Spark Streaming等。

SQL API
Flink 提供了不同级别的编程模型供开发流/批处理程序使用。越往下越灵活,但编程复杂度也越高:

Stateful Stream Process:状态化数据流的抽象接口,也是最底层的开发接口。该接口允许用户自由的处理来自一个或多个流中的事件,通过注册 Event Time 和 Processing Time 回调来实现复杂的计算。最终通过 ProcessFunction 集成到 DataStream API 中。
DataStream(有界或无界数据流) / DataSet(有界数据集) API:为许多通用的流处理操作提供了处理原语,包括各种窗口、转换、连接、聚合、窗口、状态等,因此大部分应用程序从以此接口为基础进行开发。
出于易用性的考虑,Blink 将 SQL / Table 作为其核心API,并对此进行了大量优化和重构工作(实际上 Flink SQL 绝大部分源自阿里巴巴的提交),实现了大部分 SQL 的功能,使其在使用上和标准 SQL 语法基本一致,在逻辑能力上和 DataStrem / DataSet API 相媲美,而表达上却更加简练。

对于传统 SQL 而言,操作对象通常都是一张具体的数据表,Blink 通过引入动态表(Dynamic Table)的概念,实现通过 SQL 处理流数据。通常实际的数据源(DataSource)可以来自于文本、Socket、集合对象等,如果将数据流看做是数据库中一张随着时间不断变化的动态表,数据流的内容即表中的每个字段,那么通过 SQL 的 DDL 语法即可直接定义出数据源的结构。
传统的 DB 表经过 SQL 的查询语句(DQL)搭配函数(Funcation)操作,会产生一个结果集。在动态表中则稍有差异,流上 SQL 操作是一个持续运行的过程,每当数据产生到来都会增量更新结果集中。而这个动态的结果集又可视为一张新的动态表进行新的 SQL 操作。如此串联起来,整个流式计算任务就可以看做是一张张动态表经 SQL 操作组合,数据流不断转换(Transformation)的过程。

即一个 Blink 任务的过程可以看做数据源(源表)经过流式SQL处理流向最终的目标表;

UserTrack & 实时日志
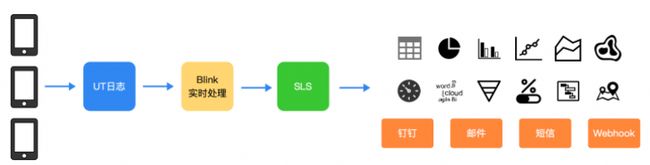
对于移动端应用,由于代码运行在一个个远程终端上,无法像服务端一样通过实时日志分析进行线上监控和问题追踪。端上作为业务的承载平台,线上感知能力却极弱,因此有必要通过技术手段补足这块短板,搭建起端侧的实时日志体系,以此来提升整体系统的稳定性。UserTrack (简称UT)就是阿⾥终端针对⽆线埋点场景结合 Blink 对流数据的处理能力提供的统⼀解决⽅案,通过UT可以很⽅便的实现端上接⼝成功率、⻚⾯曝光点击、性能等数据的准实时处理。

当端上产生一条埋点数据后,UT 提供的端侧 SDK 会先将数据进行信息补全,通过加密压缩后先离线存储到本地,之后再配合一定的调度策略通过独立进程异步上翻到无线埋点网关Adash服务中。Adash在接收到上翻数据后会进行解压、解密、分流等操作,最终将数据作为 Blink 流处理任务的输入。
面对集团整个无线端每秒数以亿计的实时数据输入,UT 中的 Blink 流处理任务会依据埋点的事件类型(如曝光事件、点击事件、自定义事件和性能数据)以及所属App(如淘宝、天猫、饿了么等)两个维度进行数据清洗分流,将对应App的所属事件类型定义在同一张动态表中,作为统一的实时日志公共层,以减少烟囱式开发,规范数据结构。
然后各个业务线可以通过订阅的方式访问到公共层的动态表,此时可将其视为一张源表,通过自定义的 Blink SQL 开启新的实时处理任务,进而实现对端侧实时数据的再加工。
依据上述原理,以笔者服务的天猫优品业务为例,我们通过 Blink 任务对接 UT 实时日志公共层,过滤出天猫优品App的实时日志,经过二次清洗加工后将处理所得的数据转存到阿里云日志服务上(SLS),利用这部分实时数据搭建起端侧的线上实时监控大盘和预警体系。
假设所属UT的动态表名为 "s_ut",那么源表的定义大致如下:
CREATE TABLE s_ut (
filed1 VARCHAR COMMENT '字段1注释',
filed2 VARCHAR COMMENT '字段2注释',
...
) with (
type = 'ut',
topic = 's_ut',
filterList = 'app_bu=''TMYP''', -- 业务标记
nullValues = '\\N|',
maxFetchSize = '100'
);可以看到整个定义语句和标准的 SQL DDL 语法基本类似,数据类型是保持了一致的。with 后面可以跟上各个数据源表所特有的配置字段,如这里的 maxFetchSize 表示一次从数据源中取出的数据条数。
同理目标表的定义大致如下:
CREATE TABLE sls_tmyp (
filed1 VARCHAR COMMENT '字段1注释',
filed2 VARCHAR COMMENT '字段2注释',
...
) WITH (
type = 'sls',
endPoint = '阿里云SLS服务地址',
project = 'SLS空间名',
logStore = 'SLS日志库名'
);需要注意的是,Blink 本身不带有数据存储功能,这里的表创建仅是动态表、外部数据表的引用声明,用来描述所处理的数据的结构(字段)。
在定义好源表和目标表后,接下来就是数据处理过程。如之前介绍,Blink 支持标准的 DQL 语句,同时提供大量函数供数据处理使用:
窗口函数:如需统计每分钟接口调用成功率,可以通过定义一个窗口来收集1分钟内的数据,再对该窗口内的数据进行实时计算。
内置函数:包括字符串函数、数字函数、日期函数、逻辑函数、条件函数、表值函数、类型转换函数、聚合函数等。
自定义函数(UDF):如果上述函数无法满足需求,也可以通过编码方式进行扩展,实现自定义处理逻辑。
和标准 SQL 类似,Blink 也推荐通过创建视图(View)来辅助计算,使逻辑表达更清晰。
CREATE VIEW v_yp_api_rate AS
SELECT
TUMBLE_END(时间字段, INTERVAL '1' MINUTE) as `time` -- 定义时间窗口,接下来的数据都是在该时间窗口内的
-- 支持 + - * / 操作,如计算接口成功率可通过 sum(成功数) / sum(调用总数) 实现。
...
FROM
s_ut
WHERE
os = 'android' -- 如过滤出Android设备的数据经过各种过滤和函数处理后得到的结果集可以通过 INSERT 语句将数据插入到最终的目标表中,大致编码如下:
INSERT
INTO sls_tmyp
SELECT
字段1,
字段2,
...
FROM
v_yp_api_rate;如此我们就得到端上分钟级的接口成功率数据,回顾整个流式处理任务过程和普通 SQL 操作相差无几,基本没有太高的开发门槛。通常端上所涉及的数据包括:
网络侧:接口成功率、耗时、失败原因;WebView 资源下载次数(缓存利用率)等;
容器侧:H5 页面加载时长、曝光次数、加载失败(证书错误、HTTP错误)、页面降级、Hybrid 接口调用等;
性能侧:CPU、内存状况;网络断连;关键场景耗时统计等。
由此基本囊括了端侧所面对的核心应用场景,通过将数据导入到报表系统中,能够可视化的观察各个场景的变化情况。同时还可以针对核心数据指标设置阈值进行环比,能够很明显的察觉到线上的异常波动。配合钉钉、邮件、短信等推送工具,可以及时将发现的问题告知到相关负责人进行排查处理。前后的整体联动,仿佛为我们开启了上帝视角,整个流程体系也成为端侧稳定性保障的基石。
实时日志监控系统只是 Blink 在端侧应用的场景之一,借助于流式SQL对数据流处理的简化,开发门槛已大大降低。我们可以大胆的将其引入到更多业务场景中(如反欺诈检测、智能推断、IOT 设备运维等),去挖掘数据的深层价值,期待大家一起来探索、尝试!

团队介绍
我们是天猫优品数字门店团队,主要服务于县域大家电消费市场,致力于通过我们的技术帮助传统门店进行数字化转型升级,通过线上线下的融合发展,全塑品牌分销、门店经营、消费者运营等新零售场景,为门店和消费者带来好品、好货、好服务。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法