浅谈张量分解(一):如何简单地进行张量分解?
在介绍张量分解(tensor decomposition)之前,我们可能需要先简单地了解一下张量是什么,然后再考虑张量分解有什么用途,并如何像稀疏矩阵分解(matrix decomposition/factorization)一样来对稀疏张量进行分解。
从初中到大学,我们接触最多的可能只是标量(scalar)、向量(vector)和矩阵(matrix),而张量则不那么常见,但实际上,标量是第0阶张量,向量是第1阶张量,矩阵是第2阶张量,第3阶或阶数更高的张量被称为高阶张量(higher-order tensor),一般提到的张量都是特指高阶张量,这在接下来的叙述中也不例外。
我们也知道,在一个矩阵中,某一元素的位置可以说成“第行第列”的形式,要表达某一元素的位置需要两个索引构成的组合,类似地,在一个第3阶张量里面,表达某一元素的位置需要三个索引构成的组合。在处理稀疏矩阵和稀疏张量时,用索引来标记元素的位置会带来很多便利。
另外,阶数的张量可以理解为矩阵的维泛化,在这里,阶数其实就是空间维度(spatial dimension),张量可以被视为多维数组。
张量分解从本质上来说是矩阵分解的高阶泛化。对矩阵分解有所了解的读者可能知道,矩阵分解有三个很明显的用途,即降维处理、缺失数据填补(或者说成“稀疏数据填补”)和隐性关系挖掘,其实张量分解也能够很好地满足这些用途。因此,在介绍张量分解之前,我们先来看看相对简单的矩阵分解,并掌握稀疏矩阵的分解过程。
1 推荐系统中常用的矩阵分解
在我们常见的推荐系统(如商品推荐系统、电影推荐系统等)中,给定一个大小为的评分矩阵,元素表示用户(user)对项(item,如电影、商品等)的评分值,如1~5分不等。
当矩阵的秩为,并且能够写成如下形式
其中,是大小为的矩阵(用户因子矩阵,user-factor matrix),是大小为的矩阵(项因子矩阵,item-factor matrix)。这一过程就是矩阵分解。
当时,我们可以将矩阵分解的过程看作是一个低秩逼近问题(low-rank approximation problem),原来的分解过程则变成
和前面相同,是大小为的矩阵(用户因子矩阵,user-factor matrix),是大小为的矩阵(项因子矩阵,item-factor matrix)。在这个低秩逼近问题中,可以很明显得看出整体误差为残差矩阵中所有元素的平方和,即(这种写法含义是矩阵F-范数的平方,等价于矩阵中所有元素的平方和)。
如果简单地使总的误差最小,那么,可以将矩阵分解的逼近问题转化为一个无约束的优化问题,即
在实际应用中,这里的评分矩阵往往是一个稀疏矩阵,即很多位置上的元素是空缺的,或者说根本不存在。试想一下,如果有10000个用户,同时存在10000部电影,如果我们需要构造一个评分矩阵,难道每个用户都要把每部电影都看一遍才知道用户的偏好吗?其实不是,我们只需要知道每个用户仅有的一些评分就可以利用矩阵分解来估计用户的偏好,并最终推荐用户可能喜欢的电影。
在这里,我们将矩阵中存在评分的位置记为,所有观测到的位置索引记作集合,其中,用户的索引为,项的索引为,需要注意的是,推荐系统中的矩阵分解对原矩阵有一定的要求,即矩阵的每行和每列至少有一个元素。此时,任意位置所对应的评分估计值为。
则原来的优化问题等价于
对目标函数中的和求偏导数,得
;
.
这里,可以将两个偏导数分别简写为和,其中,,,。
根据梯度下降(gradient descent)方法,和在每次迭代过程中的更新公式为
;.
这里的表示梯度下降的步长,又称为学习率(learning rate),另外,更新公式中的求和项下标和分别表示向量和上所有非零元素的位置索引构成的集合。
2 隐性因子模型
上面已经简单地介绍了矩阵分解的原理,对推荐系统有了解的读者可能对上面这一过程并不陌生,上面的矩阵分解在推荐系统中常常被称为隐性因子模型(latent factor model, LFM),其实张量分解与上述过程非常相似,为了便于读者初步地理解张量分解,这里将会沿用矩阵分解类似的推导过程。
定义一个关于用户(user)在环境(context,如时间,注意:这里将context翻译成“环境”不一定准确,在隐性语义分析中常常理解为“语境”或“上下文”)下对项(item)的评分为,评分张量的大小为,所有观测到位置索引仍然记作集合,其中,用户的索引为,项的索引为,环境的索引为。
Charu C. Aggarwal在其著作《Recommender systems》中给出了一个特殊的张量分解结构,即大小为的评分张量分解后会得到三个矩阵,这三个矩阵分别是:大小为的用户因子矩阵(user-factor matrix)、大小为的项因子矩阵(item-factor matrix)和大小为的环境因子矩阵(context-factor matrix),这种分解结构是隐性因子模型的一种高阶泛化。
此时,第3阶张量上任意位置所对应的评分估计值为
即
与矩阵分解中的低秩逼近问题相似,评分张量分解的逼近问题为
对目标函数中的、和求偏导数,得
;
;
.
根据梯度下降方法,、和在每次迭代过程中的更新公式为
;
;
.
需要注意的是,更新公式中的求和项下标、和分别表示矩阵、和上所有非零元素的位置索引构成的集合。
介绍到这里,可能部分读者会疑问,这里介绍的张量分解过程为何与我们常在大量文献中见到的Tucker张量分解和CP张量分解(可认为是Tucker张量分解的特例)不一样呢?接下来我们来看看采用Tucker分解的情况是怎样的。
3 稀疏张量的Tucker分解
一般来说,张量分解有各种各样的分解结构,而且对于每种结构其求解的算法也不唯一(常见的做法是采用ALS(alternating least squares)框架),并且在实际应用中,我们需要用到的张量分解通常是用来解决稀疏张量的填补问题。由于Tucker分解为张量分解提供了一个优美的分解结构,下面我们来介绍如何用梯度下降方法实现稀疏张量的Tucker分解,为了便于理解,同时,保证大家能够很轻松地编写出张量分解的算法,这里将不会提到不必要且繁琐的数学表达式。
以第3阶张量为例,假设是大小为的张量,进行Tucker分解后的表达式可以写成
其中,张量的大小为,也称为核心张量(core tensor),矩阵的大小为,矩阵的大小为,矩阵的大小为。这条数学表达式可能对很多只熟悉矩阵分解但却没有接触过张量分解的读者来说有点摸不着头脑,但完全不用担心,实际上,这条数学表达式等价于如下这个简洁的表达式,即
与上面逼近问题的目标函数类似,我们在这里可以很轻松地写出逼近问题的优化模型:
对目标函数中的、、和求偏导数,得
;
;
;
.
再根据梯度下降方法,、、和在每次迭代过程中的更新公式为
;
;
;
.
其中,更新公式中的求和项下标、和分别表示矩阵、和上所有非零元素的位置索引构成的集合。至此,我们已经完成了用梯度下降来进行Tucker张量分解的大部分工作,有了这些更新公式,我们就可以很轻松地编写程序来对稀疏张量进行分解,并最终达到对稀疏张量中缺失数据的填补。
不过,在本文中,为了简化目标函数求偏导和变量更新公式的推导过程,逼近问题的优化模型中并没有加入正则项(regularization term),有兴趣的读者可以在目标函数上添加正则项,并按照上述推导过程即可得到梯度下降的更新公式。除此之外,也可以考虑采用随机梯度下降(stochastic gradient descent)来进行张量分解,只需要对更新公式稍作修改即可。当然,上述推导过程也适用于更高阶的张量分解。
4 延伸阅读:Tucker分解与CP分解的比较
前面,我们提到了CP分解可认为是Tucker分解的特例,那么,如何理解两者之间的异同呢?我们先写出两种分解的数学表达式。
- Tucker分解:
- CP分解:
其中,张量的大小为,在Tucker分解中,核心张量的大小为,矩阵、、的大小分别是、、;在CP分解中,矩阵、、大小分别为、、,运算符号“”表示外积(outer product),如向量,向量,则。
张量在位置索引上对应的元素为
- Tucker分解:
- CP分解:
从这两个数学表达式不难看出,CP分解中构成的向量替换了Tucker分解中构成的核心张量(如图1所示),即CP分解是Tucker分解的特例,CP分解过程相对于Tucker分解更为简便,但CP分解中的选取会遇到很多复杂的问题,如张量的秩的求解是一个NP-hard问题等,这里不做深入讨论。
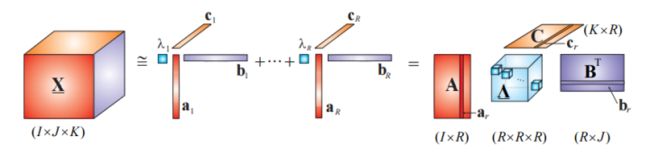
图1 CP分解过程(图片来源:Low-Rank Tensor Networks for Dimensionality ...)
5 相关阅读
本文主要参考了两部著作,第一部是Charu C. Aggarwal于2016年出版的著作《Recommender systems》(链接:Recommender Systems),其中,关于隐性因子模型(latent factor model, LFM)的部分可阅读原著93-104页(介绍了矩阵分解)和269-272页(介绍了张量分解);第二部是Gene H. Golub和Charles F. Van Loan合著的经典著作《Matrix computations (4th edition)》,其中,关于张量分解的部分可参见原著731-739页(主要介绍了高阶奇异值分解、Tucker分解和CP分解)。