java多线程和线程池
目录
零、java线程理解
0.1 两种线程模型
0.1.1 用户级线程 ULT
0.1.2 内核级线程 KLT——JAVA虚拟机使用的线程模型(KLT)
0.2 java线程与系统内核线程
0.3 线程池的意义
0.4 线程
0.4.1线程池的五种状态
0.4.2 高并发下,线程池如何保证线程安全
0.4.3 多线程的使用场景
0.4.4 多线程的创建方式
0.4.4 多线程的停止
0.4.5 控制多线程的运行顺序——join方法
一、线程池基本概念和使用示例
1.1 基本概念
1.2 基本使用示例
二、java自带线程池工具
2.1 newCachedThreadPool——不推荐使用
2.1.1 源码
2.1.2 特点
2.1.3 问题
2.2 newFixedThreadPool——不推荐使用
2.2.1 特点
2.2.2 问题
2.3 newSingleThreadExecutor——不推荐使用
2.3.1 特点
2.4 newscheduledThreadPool
2.4.1 延时执行
2.4.2 周期性执行任务
三、 线程池核心方法与体系结构
3.1 线程池最基础的框架
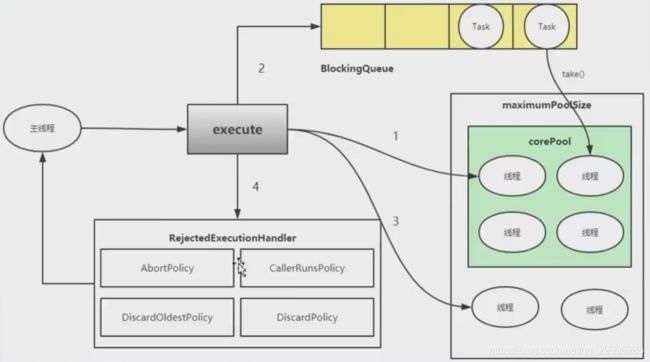
3.2 ThreadPoolExecutor
3.2.1 ThreadPoolExecutor参数说明
3.2.2 线程池任务与线程的创建顺序
3.3 线程池的三种队列
3.3.1 SynchronousQueue
3.3.2 LinkedBlockingQueue
3.3.3 ArrayBlockingQueue
3.4 线程池四种拒绝策略
3.5 关闭线程池
四、线程池工作流程
4.1 线程池的工作流程
4.2 提交优先级和执行优先级
4.2.1 提出问题
4.2.2 线程池的提交优先级和执行优先级
4.2.3 源码验证
4.3 线程池处理流程
五、 JVM内存模型——为什么会出现线程安全问题
六、java并发编程三大特性
6.1 原子性
6.1.1 基本概念
6.1.2 代码示例
6.2 可见性
6.2.1 基本概念
6.2.2 可见性问题示例代码
6.3 有序性
6.4 volatile关键字
6.4.1 volatile关键字——保证变量的可见性
6.4.2 volatile关键字——屏蔽指令重排序
6.5 关键字synchronized
6.5.1 基本概念
6.5.2 synchronized的基本原理:
6.6 lock锁
6.6.1 lock锁用法
6.6.2 lock比synchronized更优的地方
6.6.3 lock和synchronized的区别
七、并发编程之线程间通信
7.1 基本概念
7.1.1 wait、notify
7.1.2 wait和sleep的区别
7.2 实战面试题
7.2.1 两个线程,交替打印1~100
零、java线程理解
线程是调度CPU的最小单元,也叫轻量级进程LWP (Light Weight Process)
0.1 两种线程模型

0.1.1 用户级线程 ULT
- 用户程序实现,不依赖操作系统核心,应用提供创建、同步、调度和管理线程的函数来控制用户线程。
- 不需要用户态/内核态切换,速度快。
- 内核对ULT无感知,线程阻塞则进程(包括它的所有线程)阻塞。
0.1.2 内核级线程 KLT——JAVA虚拟机使用的线程模型(KLT)
- 系统内核管理线程(KLT),内核保存线程的状态和上下文信息,线程阻塞不会引起进程阻塞。
- 在多处理器系统上,多线程在多处理器上并行运行。
- 线程的创建、调度和管理由内核完成,效率比ULT要慢,比进程操作快。

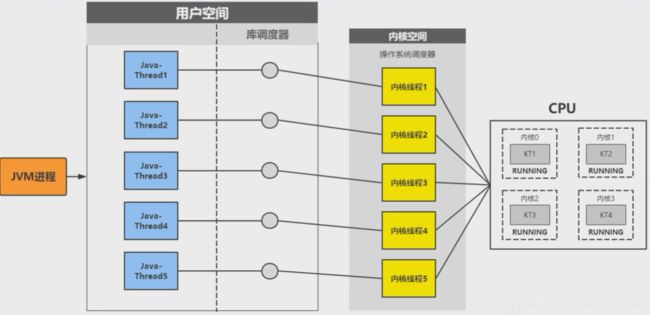
0.2 java线程与系统内核线程
Java线程创建是依赖于系统内核,通过JVM调用系统库创建内核线程,内核线程与Java -Thread是1: 1 的映射关系
0.3 线程池的意义
线程是稀缺资源,它的创建与销毁是个相对偏重且耗资源的操作,而Java线程依赖于内核线程,创建线程需要进行操作系统状态切换,为避免资源过度消耗需要设法重用线程执行多个任务。
线程池就是一个线程缓存,负责对线程进行统一分配、 调优与监控。
什么时候使用线程池?
- 单个任务处理时间比较短
- 需要处理的任务数量很大
线程池优势
- 重用存在的线程,减少线程创建,消亡的开销,提高性能
- 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性,可统分配, 调优和监控。
0.4 线程
0.4.1线程池的五种状态
- Running 能接受新任务以及处理已添加的任务
- Shutdown 不接受新任务,可以处理已经添加的任务
- Stop 不接受新任务,不处理已经添加的任务,并且中断正在处理的任务
- Tidying 所有的任务已经终止,ctl记录的”任务数量”为0, ctl负责记录线程池的运行状态与活动线程数量
- Terminated 线程池彻底终止,则线程池转变为terminated状态


可以使用getState()接口获取线程的状态
0.4.2 高并发下,线程池如何保证线程安全
线程池将线程将线程的生命状态以及工作线程数量都记录在一个整形变量中。防止使用多个变量记录时使用原子同步
private final AtomicInteger ct1 = new AtomicInteger (ct1of(RUNNING, 0));
private static fina1 int COUNT_BITS = Integer.SIZE - 3;
// 高3位记录线程池生命状态
// 低29位记录当前工作线程数
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
// -1 = 1111 1111 1111 1111 1111 1111 1111 1111
// -1 << COUNT_BITS(即29) = 1110 0000 0000 0000 0000 0000 0000 0000
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ct1
private static int runStateof(int c) { return C & ~CAPACITY; }
private static int workerCountof(int C) { return C & CAPACITY; }
private static int ct1of(int rs, int wc) { return rs | wC; }
0.4.3 多线程的使用场景
- 1.后台任务,例如:定时向大量(100w以上) 的用户发送邮件
- 2.异步处理,例如:统计结果,记录日志发送短信等:
- 3.分布式计算分片下载、断点续传
小结:
- 任务量比较大, 通过多线程可以提高效率时
- 需要异步处理时
- 占用系统资源,造成阻塞的工作时
都可以采用多线程提高效率
0.4.4 多线程的创建方式
继承Thread
public static void main(String[] args) {
MyThread myThread = new MyThread();
myThread.start();
}
//继承Thread类实现run方法
static class MyThread extends Thread {
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
System.out.println("输出打印" + i);
}
}
}实现Runnable
public static void main(String[] args) {
Thread thread = new Thread(new MyRunnable());
thread.start();
}
//实现Runnab7e接口I实现run方法
static class MyRunnable implements Runnable {
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
System.out.println("输出:" + i);
}
}
}如果希望线程执行完任务之后,给我们一个返回值。此时我们需要执行Callable接口
public static void main(String[] args) {
FutureTask ft = new FutureTask<>(new MyCallable());
Thread thread = new Thread(ft);
thread.start();
try {
Integer num = ft.get();
System.out.println("得到的结果:" + num);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
static class MyCallable implements Callable {
@Override
public Integer call() throws Exception {
int num = 0;
for (int i = 0; i < 1000; i++) {
System.out.println("输出" + i);
num += i;
}
return num;
}
} 0.4.4 多线程的停止
使用 interrupt() 以及 isInterrupted()
public static void main(String[] args) {
Thread t1 = new Thread(()->{
while (true){
try {
boolean interrupted = Thread.currentThread().isInterrupted();
if(interrupted){
System.out.println("线程已停止");
break;
}else{
System.out.println("线程执行中");
}
} catch (Exception e) {
e.printStackTrace();
}
}
});
t1.start();
try {
Thread.sleep(2000);
t1.interrupt();
}catch (InterruptedException e){
e.printStackTrace();
}
}0.4.5 控制多线程的运行顺序——join方法
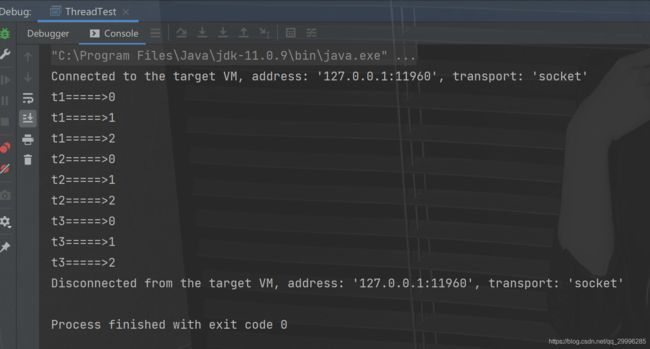
面试题:
现在有T1、T2、T3三个线程,你怎样保证T2在T1执行完后执行,T3在T2执行完后执行
Thread的方法join
线程调用了join方法,那么就要一直运行到该线程运行结束,才会运行其他进程.这样可以控制线程执行顺序。

使用join方法,相当于线程的插队方法
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 3; i++) {
System.out.println("t1=====>" + i);
}
});
Thread t2 = new Thread(() -> {
try {
t1.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int i = 0; i < 3; i++) {
System.out.println("t2=====>" + i);
}
});
Thread t3 = new Thread(() -> {
try {
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int i = 0; i < 3; i++) {
System.out.println("t3=====>" + i);
}
});
t1.start();
t2.start();
t3.start();
}
一、线程池基本概念和使用示例
1.1 基本概念
Java中的线程池是运用场景最多的并发框架,几乎所有需要异步或并发执行任务的程序都可以使用线程池。
在开发过程中,合理地使用线程池能够带来3个好处。
第一:降低资源消耗
通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度
当任务到达时,任务可以不需要等到线程创建就能立即执行。
第三:提高线程的可管理性
线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。但是,要做到合理利用线程池,必须对其实现原理了如指掌。
1.2 基本使用示例
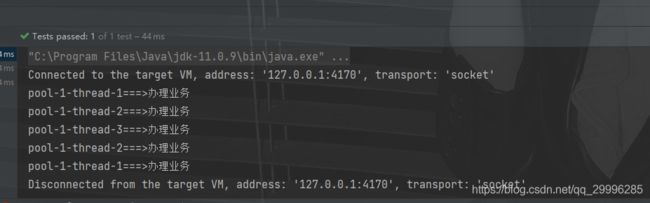
public void testThread() {
//其中线程池工厂参数用于创建线程
ExecutorService executorService = new ThreadPoolExecutor(3, 5, 1L,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(3), Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
for (int i = 0; i < 5; i++) {
executorService.execute(() -> {
System.out.println(Thread.currentThread().getName() + "===>办理业务");
});
}
}
二、java自带线程池工具
2.1 newCachedThreadPool——不推荐使用
2.1.1 源码
底层使用ThreadPoolExector
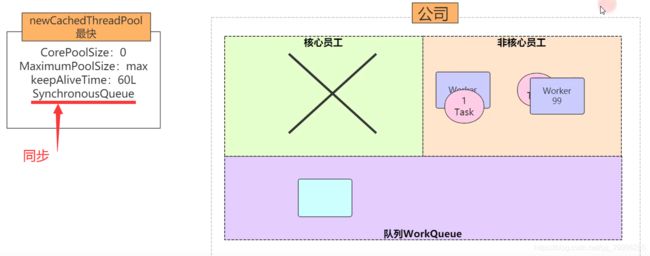
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
} 2.1.2 特点
没有核心线程,等待队列使用同步队列,出现一个任务就创建一个临时线程去执行任务
2.1.3 问题
不会出现内存溢出,但是会浪费CPU资源,导致机器卡死。
2.2 newFixedThreadPool——不推荐使用
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
} 2.2.1 特点
特定核心线程,无临时线程。等待队列使用链表,等待队列无限长度
2.2.2 问题
会导致内存溢出,因为等待队列无限长。

2.3 newSingleThreadExecutor——不推荐使用
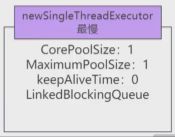
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
} 2.3.1 特点
创建一个单线程化的线程池, 它只会用唯一的工作线程来执行任务, 保证所有任务按照指定顺序(FIFO,LIFO, 优先级)执行。
只有一个核心线程,依次执行任务。
2.4 newscheduledThreadPool
创建一个定长线程池, 支持定时及周期性任务执行。
2.4.1 延时执行
下面例子是4s之后执行run方法
public static void pool4() {
ScheduledExecutorService newScheduledThreadPool =
Executors.newScheduledThreadPool(5);
//延时执行的线程池
//参数:任务 延时时间 时间单位
newScheduledThreadPool.schedule(new Runnable() {
public void run() {
System.out.println("i:" + 1);
}
}, 4, TimeUnit.SECONDS);
}2.4.2 周期性执行任务
下面例子中,设置了一个定时任务,线程开启后,3s后执行任务,每4s执行一次
public static void pool4() {
ScheduledExecutorService newScheduledThreadPool =
Executors.newScheduledThreadPool(5);
//延时执行的线程池
//参数:任务 延时时间 间隔时间 时间单位
newScheduledThreadPool.scheduleAtFixedRate(new Runnable() {
public void run() {
System.out.println("i:" + 1);
}
}, 3, 4, TimeUnit.SECONDS);
}三、 线程池核心方法与体系结构
3.1 线程池最基础的框架

public interface Executor {
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be
* accepted for execution
* @throws NullPointerException if command is null
*/
void execute(Runnable command);
}3.2 ThreadPoolExecutor
3.2.1 ThreadPoolExecutor参数说明
- int corePoolSize 核心线程数
- int maximumPoolSize 最大线程数
- long keepAliveTime, 保持存活的时间——指的是外额线程在没有新任务执行时的存活时间
- TimeUnit unit, 时间单位
- BlockingQueue
workQueue, 任务队列 - RejectedExecutionHandler handler 饱和策略
3.2.2 线程池任务与线程的创建顺序
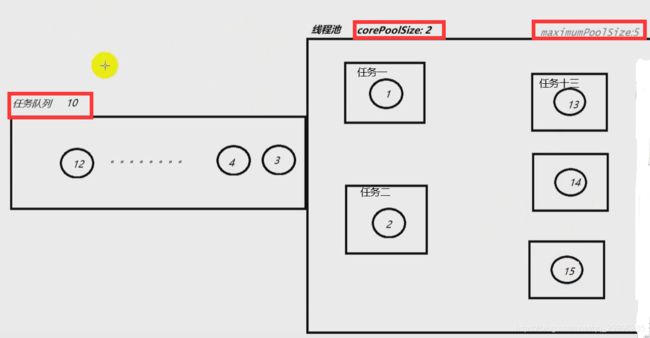
假设ThreadPoolExecutor创建的核心线程数为2,等待队列长度为10,最大线程数为5 .则每个任务来的时候,线程的创建顺序如下:
- 任务一和任务二来的时候,分别会创建一个核心线程并执行该任务
- 任务三到十二来的时候,核心线程已满,需要进入等待队列等待
- 任务十三到十五来的时候,核心线程和等待队列均已满,所以创建额外线程去执行任务
- 任务十六来的时候,由于整个线程池都已沾满,因此根据饱和策略做出反馈
3.3 线程池的三种队列
3.3.1 SynchronousQueue
synchronousQueue没有容量,是无缓冲等待队列,是一个不存储元素的阻塞队列,会直接将任务交给消费者,必须等队列中的添加元素被消费后才能继续添加新的元素。
使用synchronousQueue阻塞队列一般要求maximumRoolsizes为无界,避免线程拒绝执行操作。
- 当队列中没有任务时,获取任务的动作会被阻塞;
- 当队列中有任务时,存入任务的动作会被阻塞
3.3.2 LinkedBlockingQueue
LinkedBlockingQueue是个无界缓存等待队列。
当前执行的线程数量达到corePoolsize的数量时,剩余的元素会在阻塞队列里等待。(所以在使用此阻塞队列时max imumPoolsizes就相当于无效了),每个线程完全独立于其他线程。
生产者和消费者使用独立的锁来控制数据的同步,即在高并发的情况下可以并行操作队列中的数据。
3.3.3 ArrayBlockingQueue
ArrayBlockingQueue是一个有界缓存等待队列,可以指定缓存队列的大小
当正在执行的线程数等于corePoolsize时,多余的元素缓存在ArrayBlockingQueue队列中等待有空闲的线程时继续执行
当ArrayBlockingQueue已满时,加入ArrayBlockingQueue失败, 会开启新的线程去执行
当线程数已经达到最大的maximumPoolsizes时, 再有新的元素尝试加入ArrayBlocki ngQueue时会报错。
3.4 线程池四种拒绝策略

/* Predefined RejectedExecutionHandlers */
/**
* A handler for rejected tasks that runs the rejected task
* directly in the calling thread of the {@code execute} method,
* unless the executor has been shut down, in which case the task
* is discarded.
*/
// 不抛弃任务,请求调用线程池的主线程(比如main),帮忙执行任务
public static class CallerRunsPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code CallerRunsPolicy}.
*/
public CallerRunsPolicy() { }
/**
* Executes task r in the caller's thread, unless the executor
* has been shut down, in which case the task is discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
/**
* A handler for rejected tasks that throws a
* {@link RejectedExecutionException}.
*
* This is the default handler for {@link ThreadPoolExecutor} and
* {@link ScheduledThreadPoolExecutor}.
*/
// 抛出异常,丢弃任务
public static class AbortPolicy implements RejectedExecutionHandler {
/**
* Creates an {@code AbortPolicy}.
*/
public AbortPolicy() { }
/**
* Always throws RejectedExecutionException.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
* @throws RejectedExecutionException always
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
/**
* A handler for rejected tasks that silently discards the
* rejected task.
*/
// 直接丢弃任务,丢弃等待时间最短的任务
public static class DiscardPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardPolicy}.
*/
public DiscardPolicy() { }
/**
* Does nothing, which has the effect of discarding task r.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
/**
* A handler for rejected tasks that discards the oldest unhandled
* request and then retries {@code execute}, unless the executor
* is shut down, in which case the task is discarded.
*/
// 直接丢弃任务,丢弃等待时间最长的任务
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardOldestPolicy} for the given executor.
*/
public DiscardOldestPolicy() { }
/**
* Obtains and ignores the next task that the executor
* would otherwise execute, if one is immediately available,
* and then retries execution of task r, unless the executor
* is shut down, in which case task r is instead discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
3.5 关闭线程池
//等待任务队列所有的任务执行完毕后才关闭
executor.shutdown();
//立刻关闭线程池
executor.shutdownNow();四、线程池工作流程
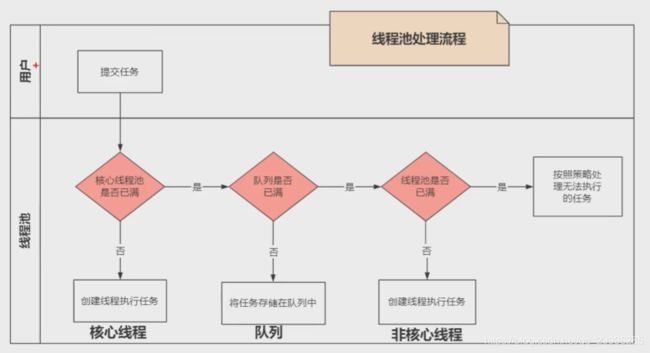
4.1 线程池的工作流程
- 判断核心线程数
- 判断任务能否加入到任务队列
- 判断最大线程数量
- 根据线程池的拒绝策略处理任务
4.2 提交优先级和执行优先级
4.2.1 提出问题
使用线程池,设置核心线程数为10,最大额外线程数为20,执行任务时,输出结果不是按序输出,而是如图,10之后直接跳到21。:
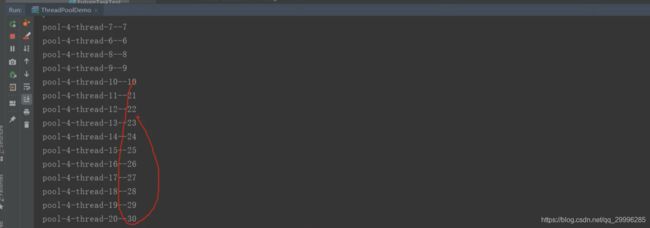
4.2.2 线程池的提交优先级和执行优先级
线程池的提交优先级顺序为 核心线程>等待队列>额外线程
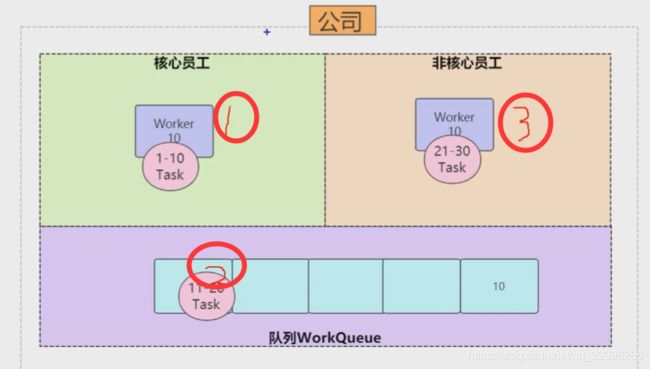
执行优先级为: 核心线程>额外线程>等待队列
因此输出数据顺序是 1-10,21-30,11-19
4.2.3 源码验证
ThreadPoolExector类中的execute方法源码
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}代码分析
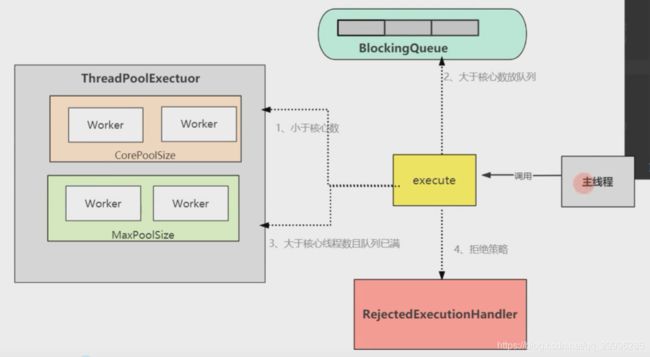
4.3 线程池处理流程
五、 JVM内存模型——为什么会出现线程安全问题
Java内存模型(即Java Memory Mode1, 简称JMM)。
JMM本身是一种抽象的概念,并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。
由于JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存 (有些地方称为栈空间),用于存储线程私有的数据。
Java内存模型中规定:
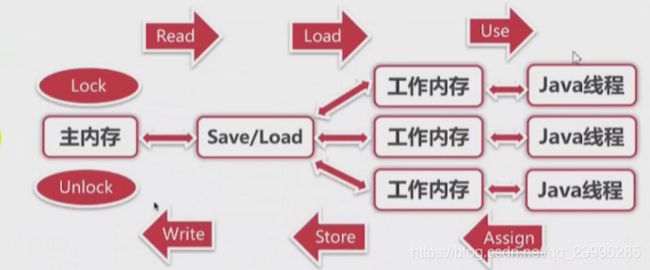
所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问。
线程对变量的操作(读取赋值等)必须在工作内存中进行——首先要将变量从主内存拷贝的自己的工作内存空间,然后对变量进行操作,操作完成后再将变量写回主内存,不能直接操作主内存中的变量,工作内存中存储着主内存中的变量副本拷贝
前面说过,工作内存是每个线程的私有数据区域,因此不同的线程间无法访问对方的工作内存,线程间的通信(传值)必须通过主内存来完成,其简要访问过程如下图:

六、java并发编程三大特性
正因为有了JMM内存模型,以及java语言的设计,所以在并发编程当中我们可能会经常遇到下面几种问题。这几种问题我们称为并发编程的三大特性:
6.1 原子性
6.1.1 基本概念
原子性,即一个操作或多个操作,要么全部执行并且在执行的过程中不被打断,要么全部不执行。(提供了互斥访问, 在同一时刻只有一个线程进行访问)
可以通过锁的方式解决
6.1.2 代码示例
package rudy.study.language.thread;
import org.junit.jupiter.api.Test;
import org.springframework.stereotype.Component;
import java.util.concurrent.*;
/**
* @author rudy
* @date 2021/7/18 18:33
*/
@Component
public class ThreadTest {
static int ticket = 10;
public static void main(String[] args) {
Object o = new Object();
Runnable runnable = () -> {
while (true) {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
//使用synchronized时,需要用一个对象作为锁
synchronized (o) {
if (ticket > 0) {
ticket--;
System.out.println(Thread.currentThread().getName() +
"卖了一张票,剩余:" + ticket);
} else {
break;
}
}
}
};
Thread t1 = new Thread(runnable,"窗口1");
Thread t2 = new Thread(runnable,"窗口2");
Thread t3 = new Thread(runnable,"窗口3");
t1.start();
t2.start();
t3.start();
}
}
6.2 可见性
6.2.1 基本概念
当多个线程访问同一个变量时,-个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
若两个线程在不同的cpu, 那么线程1改变了 i 的值还没刷新到主存,线程2又使用了 i,那么这个 i 值肯定还是之前的,线程1对变量的修改线程没看到。
这就是可见性问题。
6.2.2 可见性问题示例代码
package rudy.study.language.thread;
import org.springframework.stereotype.Component;
/**
* @author rudy
* @date 2021/7/18 18:33
*/
@Component
public class ThreadTest {
private static boolean flag = true;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
System.out.println("1号线程启动,执行while循环");
long num = 0;
while (flag) {
num++;
}
System.out.println("1号线程执行,num=" + num);
}).start();
Thread.sleep(1);
new Thread(() -> {
System.out.println("2号线程启动,更改变量flag值为false");
setStop();
}).start();
}
public static void setStop() {
flag = false;
}
}6.3 有序性
编译器在执行代码时,可能会对代码进行优化,导致代码执行顺序与预期不符。
6.4 volatile关键字
作用是变量在多个线程之间可见。并且能够保证所修饰变量的有序性
6.4.1 volatile关键字——保证变量的可见性
当一个被volatile关键字修饰的变量被一个线程修改的时候,其他线程可以立刻得到修改之后的结果。
当一个线程修改了被volatile关键字修饰的变量后,虚拟机会强制将变更后的结果同步到主内存中。
当一个主内存中被volatile修饰变量的值发生更新后,虚拟机会强制将新值同步到使用该变量的各个线程中。
6.4.2 volatile关键字——屏蔽指令重排序
指令重排序是编译器和处理器为了高效对程序进行优化的手段,它只能保证程序执行的结果是正确的,但是无法保证程序的操作顺序与代码顺序一致。
这在单线程中不会构成问题,但是在多线程中就会出现问题。
非常经典的例子是在单例方法中同时对字段加入volatile, 就是为了防止指令重排序。
6.5 关键字synchronized
6.5.1 基本概念
- 可以保证在同一时刻,只有一个线程可以执行某个方法或某个代码块
- synchronized可以保证一个线程的变化可见(可见性),即可以代替volatile
synchronized必须使用一个对象作为锁
6.5.2 synchronized的基本原理:
锁由jvm帮忙实现。
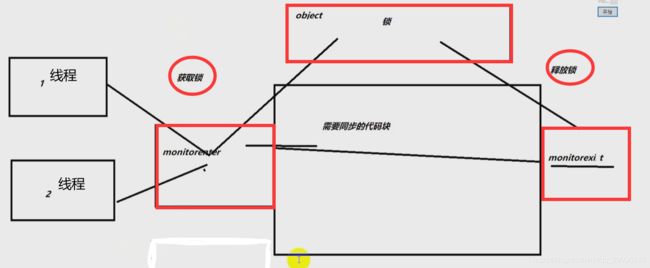
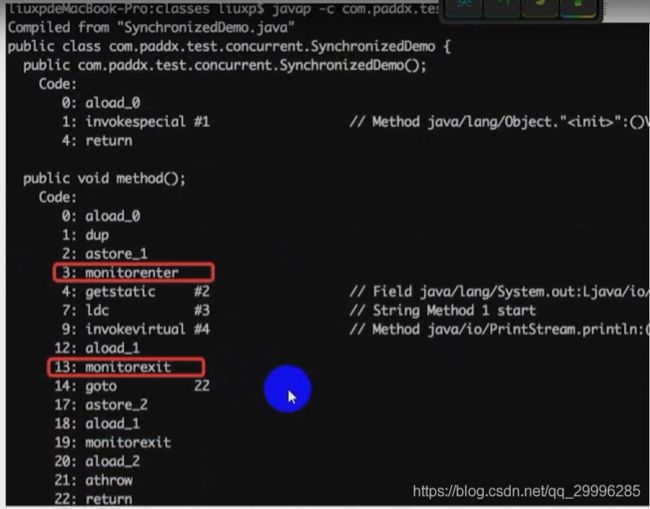
JVM是通过进入、退出对象监视器( Monitor )来实现对方法、同步块的同步的。
具体实现是在编译之后在同步方法调用前加入一个monitor.enter指令,在退出方法和异常处插入monitor.exit的指令。
其本质就是对一个对象监视器( Monitor )进行获取,而这个获取过程具有排他性从而达到了同一时刻只能一个线程访问的目的。而对于没有获取到锁的线程将会阻塞到方法入口处,直到获取锁的线程monitor.exit 之后才能尝试继续获取锁。
6.6 lock锁
在jdk1.5之后,并发包中新增了Lock 接口(以及相关实现类)用来实现锁功能,Lock 接口提供了与synchronized关键字类似的同步功能,但需要在使用时手动获取锁和释放锁。
6.6.1 lock锁用法
Lock lock = new ReentrantLock();
lock.lock();
try {
//可能会出现线程安全的操作
} finally {
//- 定在finally中释放锁
//也不能把获取锁在try中进行,因为有可能在获取锁的时候抛出异常
lock.unlock();
}6.6.2 lock比synchronized更优的地方
1. 支持tryLock尝试获取锁
lock有tryLock接口。当锁被占用时,其他线程在tryLock失败后,无需等待,可以去做别的事情
而synchronized必须等待锁释放
2. 支持读写锁
6.6.3 lock和synchronized的区别
1) Lock是一 个接口,而synchroni zed是Java中的关键字
synchroni zed是内置的语言实现;synchronized关键字可以直接修饰方法,也可以修饰代码块,而lock只能修饰代码块
2) synchronized在发生异常时,会自动释放线程占有的锁
因此不会导致死锁现象发生; 而Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象,因此使用Lock时需要在finally块中释放锁;
3) Lock可以让等待锁的线程响应中断,而synchronized却不行
使用synchronized时,等待的线程会直等待下去,不能够响应中断;
4)通过Lock可以知道有没有成功获取锁,而synchronized却无法办到。(提供tryLock)
5) Lock可以提高多个线程进行读操作的效率。(提供读写锁)
在性能上来说,如果竞争资源不激烈,两者的性能是差不多的,而当竞争资源非常激烈时(即有大量线程同时竞争),此时 lock的性能要远远优于synchronized.
所以说,在具体使用时要根据适当情况选择。
七、并发编程之线程间通信
7.1 基本概念
7.1.1 wait、notify
多个线程在处理同一个资源,并且任务不同时,需要线程通信来帮助解决线程之间对同一个变量的使用或操作。
于是我们引出了等待唤醒机制: (wait()、 notify())
wait()、notify()、 notifyA11()是三个定义在object类里的方法,可以用来控制线程的状态。
这三个方法最终调用的都是jvm级的native方法。随着jvm运行平台的不同可能有些许差异。
- 如果对象调用了wait方法就会使持有该对象的线程把对象的控制权交出,然后处于等待状态。
- 如果对象调用了notify方法就会通知某个正在等待这个对象的控制权的线程可以继续运行。
- 如果对象调用了notifyAll方法就会通知所有等待这个对象控制权的线程继续运行。
注意: wait() 方法的调用必须放在synchronized方法或synchronized块中。——因为wait方法的作用是释放锁,所以必须保证有锁
7.1.2 wait和sleep的区别
sleep()方法属于Thread类, wait()方法,属于object类
在调用sleep()方法的过程中,线程不会释放对象锁。
当调用wait()方法的时候,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用notify()方法后本线程才进入对象锁定池准备获取对象锁进入运行状态。
sleep()方法导致了程序暂停执行指定的时间,让出cpu给其他线程,但是他的监控状态依然保持,当指定的时间到了又会自动恢复运行状态。
7.2 实战面试题
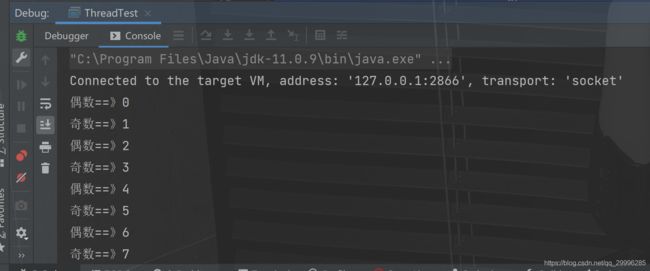
7.2.1 两个线程,交替打印1~100
A线程负责打印奇数B线程负责打印偶数。
package rudy.study.language.thread;
import lombok.AllArgsConstructor;
import org.springframework.stereotype.Component;
/**
* @author rudy
* @date 2021/7/18 18:33
*/
@Component
public class ThreadTest {
public static void main(String[] args) {
Integer lock = 0;
NumObj numObj = new NumObj();
numObj.num = 0;
new Thread(new JiNum(numObj)).start();
new Thread(new OuNum(numObj)).start();
}
@AllArgsConstructor
static class JiNum implements Runnable {
private NumObj numObj;
@Override
public void run() {
while (true) {
synchronized (numObj) {
if (numObj.num < 100) {
if (numObj.num % 2 != 0) {
System.out.println("奇数==》" + numObj.num);
numObj.num++;
numObj.notify();
} else {
try {
numObj.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} else {
break;
}
}
}
}
}
@AllArgsConstructor
static class OuNum implements Runnable {
private NumObj numObj;
@Override
public void run() {
while (true) {
synchronized (numObj) {
if (numObj.num < 100) {
if (numObj.num % 2 == 0) {
System.out.println("偶数==》" + numObj.num);
numObj.num++;
numObj.notify();
} else {
try {
numObj.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} else {
break;
}
}
}
}
}
}