卷积神经网络
文章目录
- 一、卷积神经网路定义
- 二、卷积神经网络结构及运行原理
-
- 2.1 网络结构
- 2.2 运行原理
- 三、卷积神经网络分类
-
- 3.1 单位卷积(1x1)
- 3.2 2D卷积
- 3.3 3D卷积
- 3.4 空间可分离卷积(separable convolution)
- 3.5 深度可分离卷积(depthwise separable convolution)
- 3.6 分组卷积(Group convolution)
- 3.7 空洞卷积(Dilated convolution)
- 3.8 转置卷积(Transposed convolution)
- 总结
一、卷积神经网路定义
卷积神经网络,是一种前馈神经网络。通过模拟人体类的神经元细胞进行信号处理,人工神经元可以响应周围单元,最终完成信号反射。卷积的目的是提取特征,在图像处理领域,用户可选择各种过滤器(filter)来对象提取特征。卷积包括一维卷积神经网络、二维卷积神经网络以及三维卷积神经网络。一维卷积神经网络常应用于序列类的数据处理;二维卷积神经网络常应用于图像类文本的识别;三维卷积神经网络主要应用于医学图像以及视频类数据识别。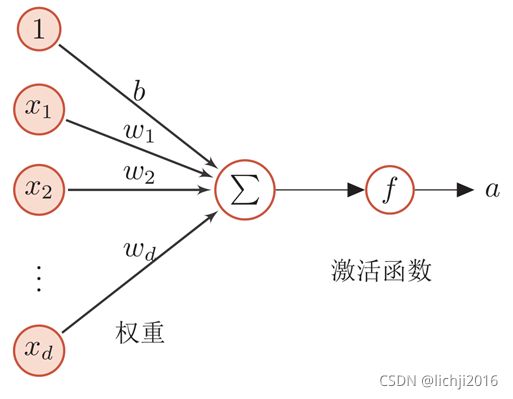
二、卷积神经网络结构及运行原理
2.1 网络结构
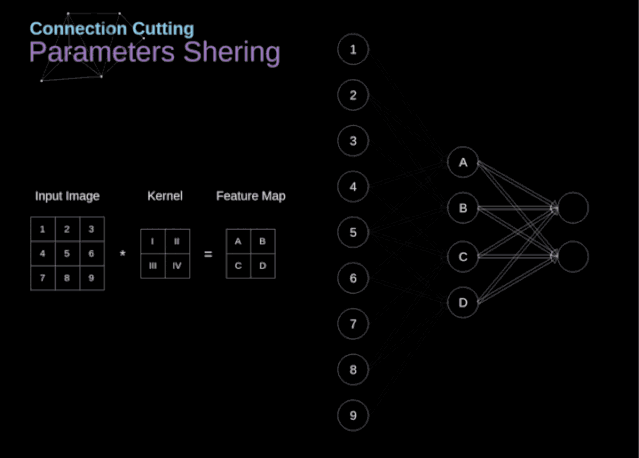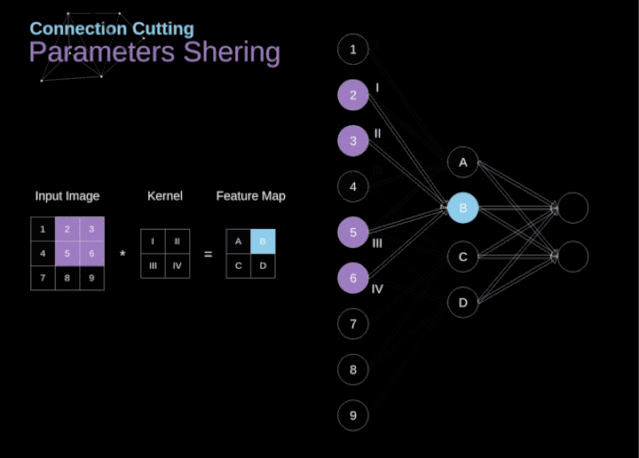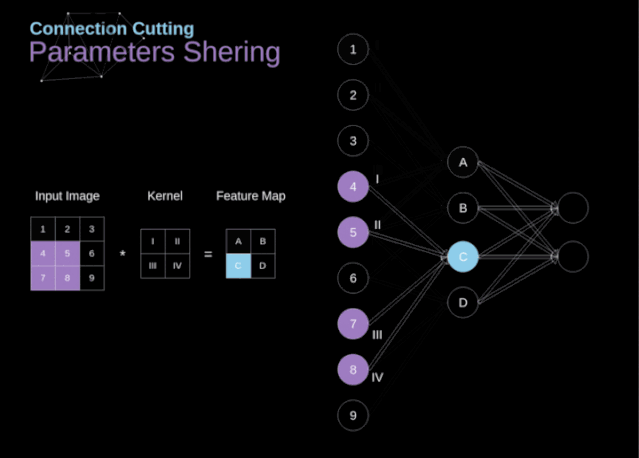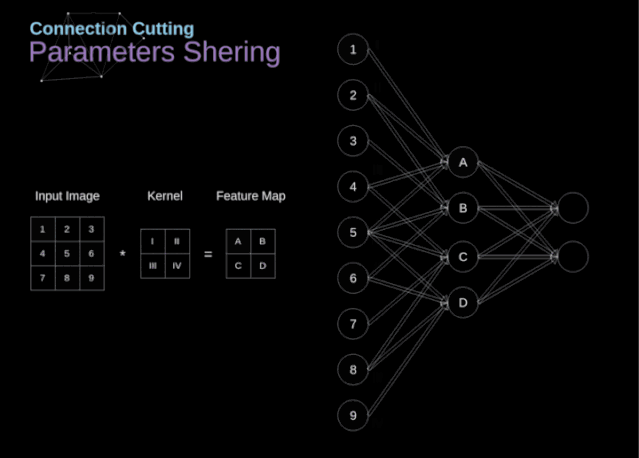
卷积神经网络是前馈神经网络(全连接神经网络、多层感知器)中的一种,它与传统的网络区别在于可以传入二维和三维,传统的模型一般仅仅可以传输一个维度模型,其特点如下:
各神经元分别属于不同的层,层内无连接。
相邻两层之间的神经元全部两两连接。
整个网络中无反馈,信号从输入层向输出层单向传播,可用一个有向无环图表示。
神经网络,用下面的记号来描述这样网络:

前馈神经网络通过下面公式进行信息传播。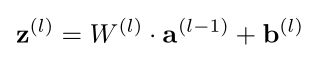
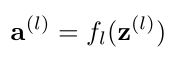
前馈计算## 1.引入库
![]()
模型演变如下图:
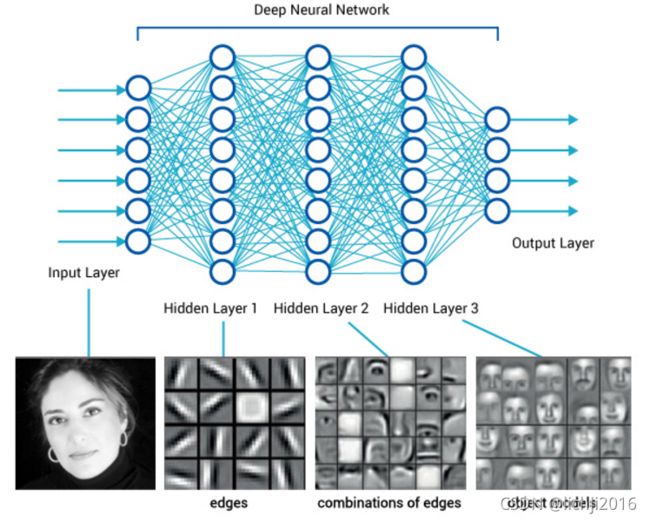
神经网路模型的整个流程如下如所示:
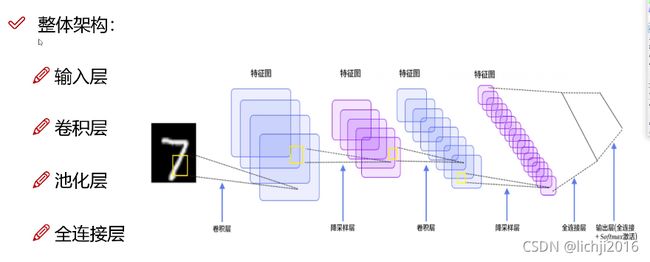
2.2 运行原理
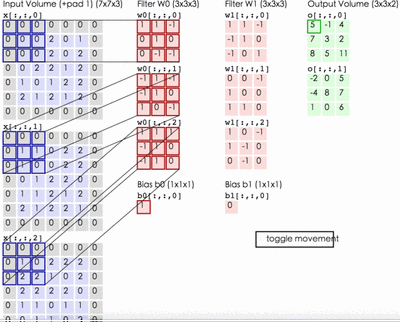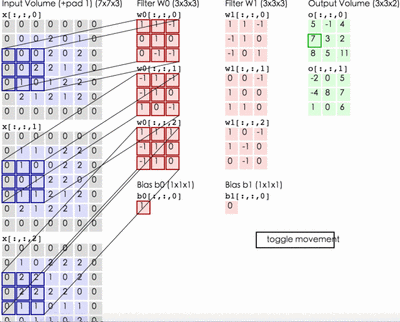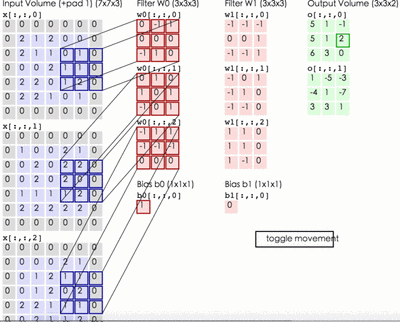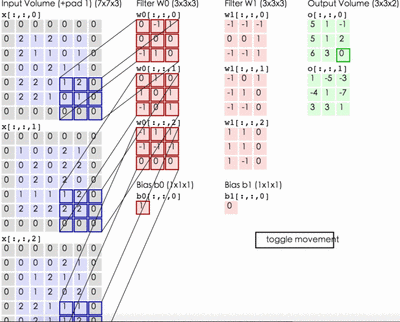
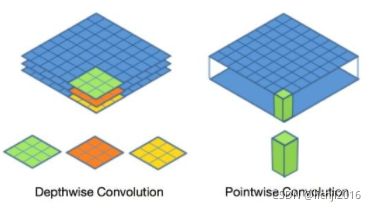
卷积神经网络实际上一个特征提取器,一般用于图像处理,将原有图像进行特征扫描,转化为矩阵,经过一系列变换和算法,最终还原成图像。图像一般表现形式为hwc(其中h*w表示图像的长和宽,w表示图像的通道,一般为RGB三个通道,如下图所示),在卷积神经网络特征提取过程中,如果是彩色图片,需要对R/G/B三个通道分别进行特征提取,然后将对应的位置特征值进行相加。卷积的优点在于权值共享和平移不变性。
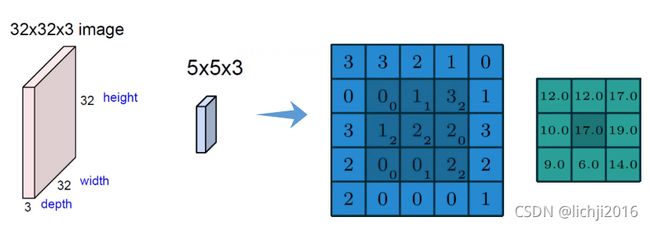

特征提取过程中下图左侧第一列可以认为是R/G/B三个通道,因此过滤器1需要分别进行特征提取,前后特征提取通道数必须一致。(7x7x3->3x3x3 最后3表示通道,前后必须一致)
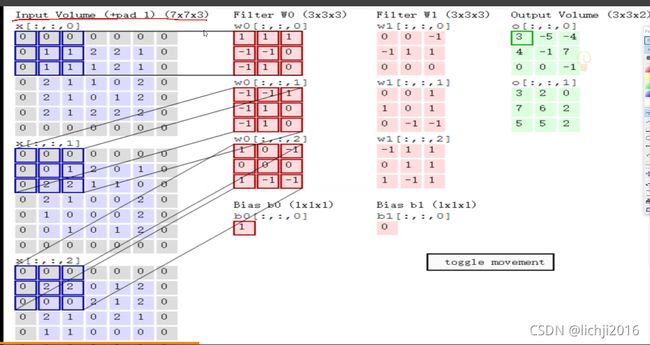
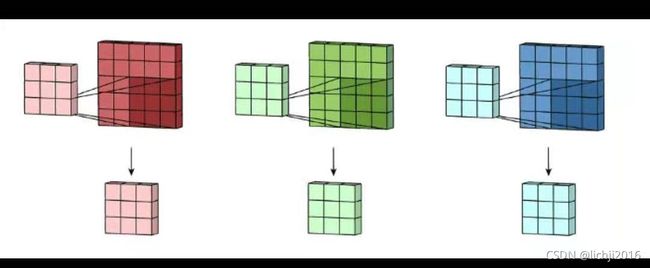
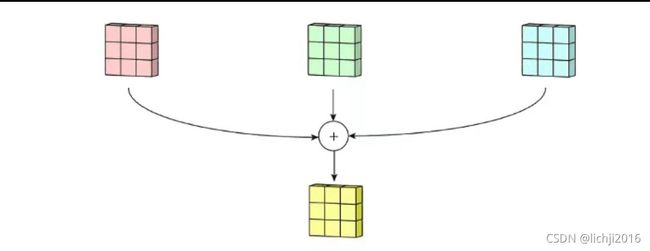
在上述三个通道分别进行卷积后与偏置bias进行相加,即可得到经过Wo后的特征提取。
三、卷积神经网络分类
3.1 单位卷积(1x1)
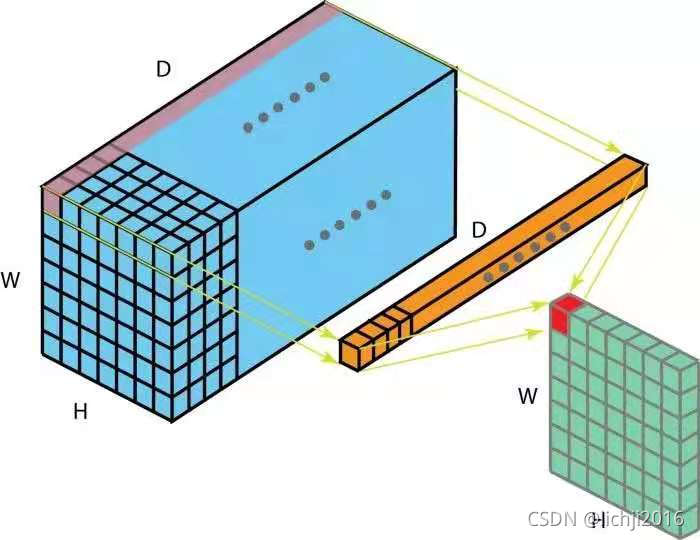
在卷积特征映射过程中,每个映射乘以一个数(单位卷积1x1),一方面经过激活函数,象征着进行了非线性变换,同时会改变通道(channel)的数量。
例如:一个hwD的输入经过一个单位卷积(1x1xD)的filter后,输出通道变成维度变为hw1,我们执行k次操作单位卷积后,得到一个hwk维度的输出值。
3.2 2D卷积
我们学习信号处理中卷积的定义是一个函数经过翻转和移动后与另一个函数进行乘积积分。而在深度学习中,卷积不需要经过翻转。在卷积神经网络中,单通道channel,卷积就是对应元素相乘累加求和,如下图所示
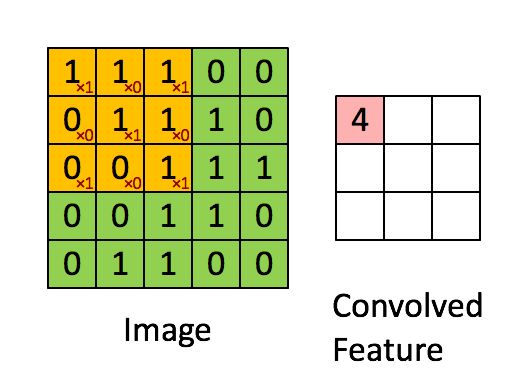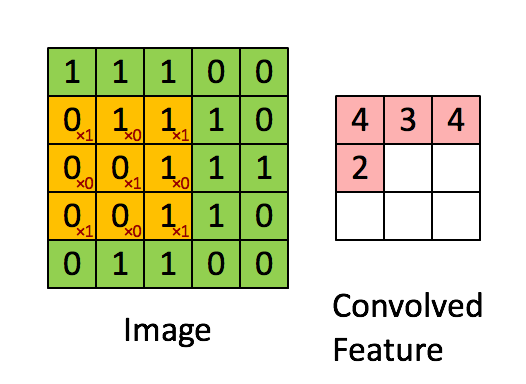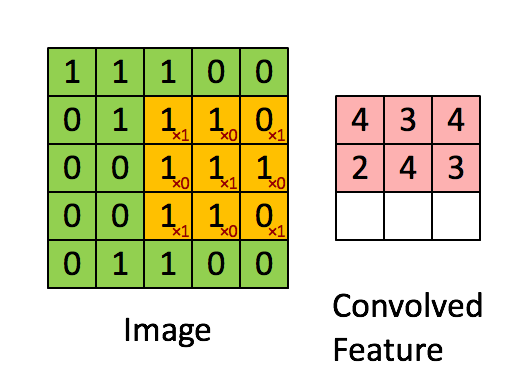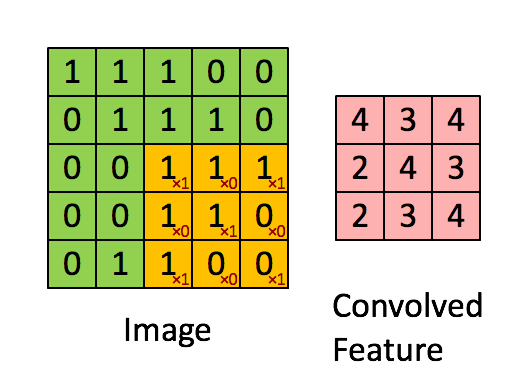
上述的filter是一个33矩阵元素为(1,0,1),(0,1,0),(1,0,1),卷积步长为1(每次移动一格),最终输出的为一个33矩阵。
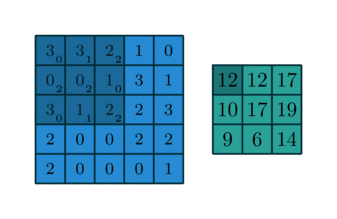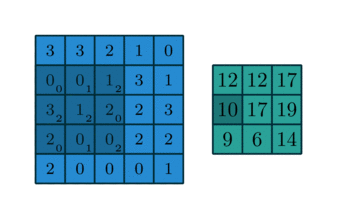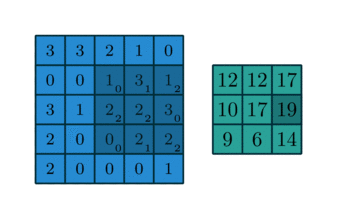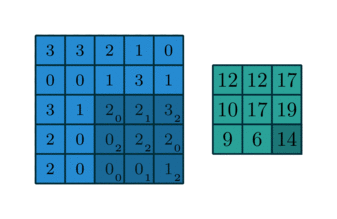
上述的filter是一个33矩阵元素为(0,1,2),(2,2,0),(0,1,2),卷积步长为1(每次移动一格),最终输出的为一个33矩阵。
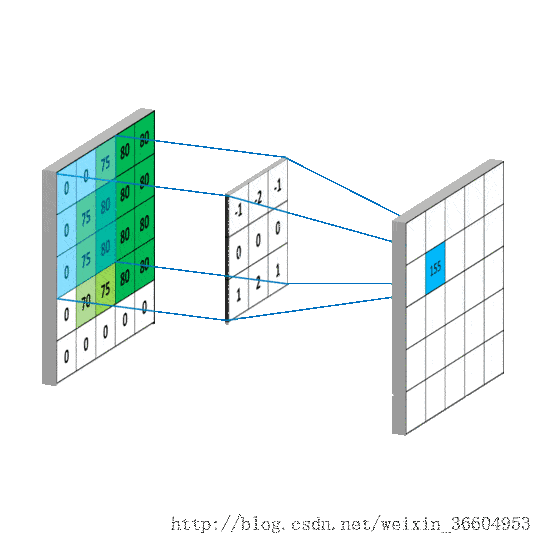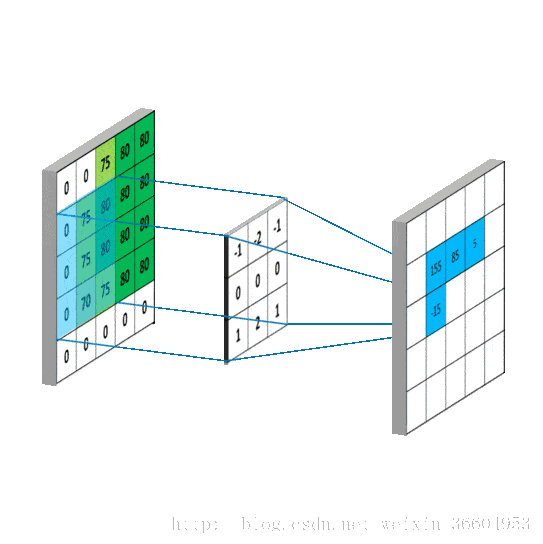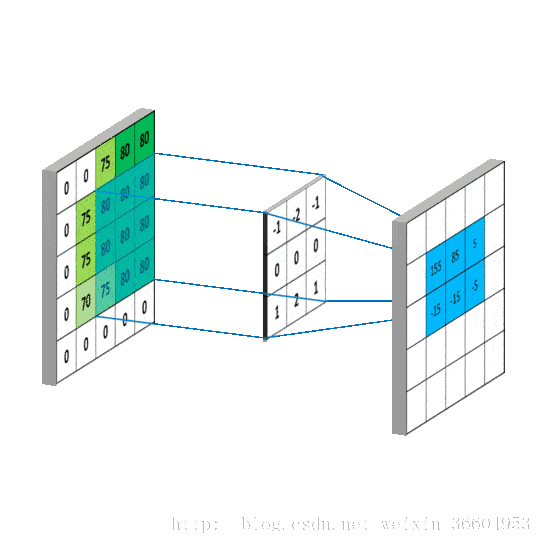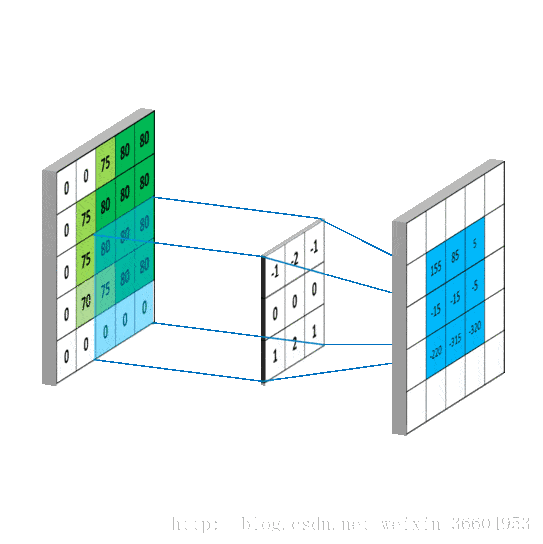
多通道中,图像一般由RGB三种颜色三个通道,卷积中分别对三个通道进行卷积。
这里输入层为一个77矩阵,有三个通道,filter是333矩阵,filter中的每个kernels分别与输入层中的三个通道,产生3个尺寸33的通道。然后将三个通道相加(对应元素相加)形成一个单一通道331。
3.3 3D卷积
3D卷积定义为Filter的深度小于输入层深度(卷积核的个数小于输入层通道层道数)。它需要在三个维度(长、宽、高)三个方向滑动,每滑动一次位置,执行一次卷积,得到一个数值。当滑过整个空间,输出的结构也是3D。2D和3D卷积区别在于filter滑动的维度。3D主要应用于分割以及医学重构等领域。
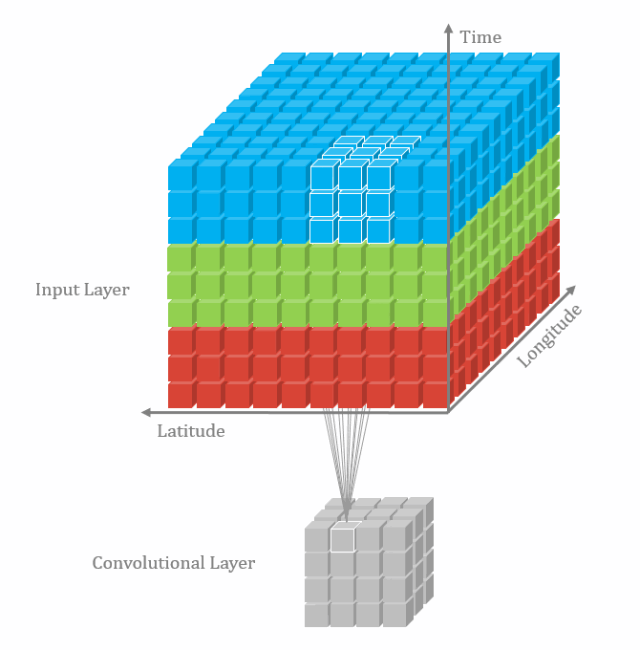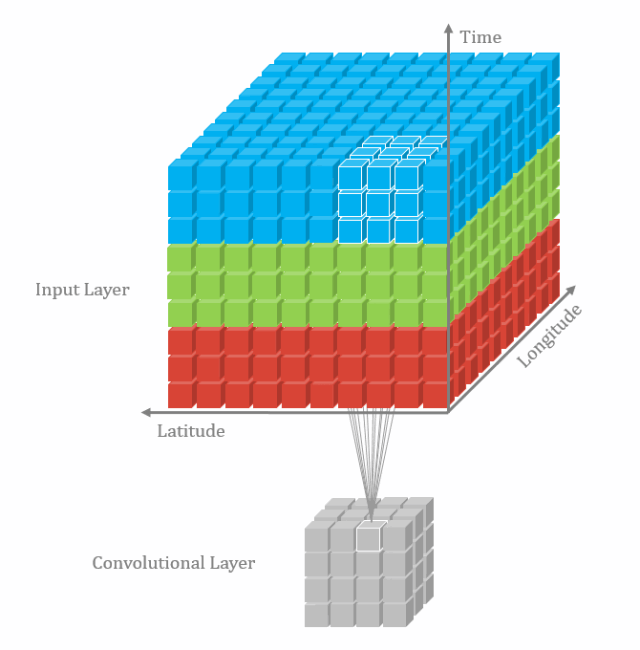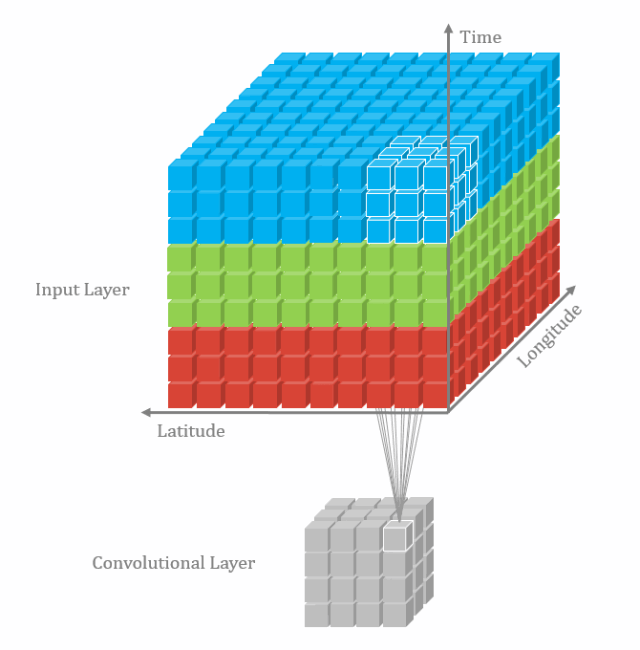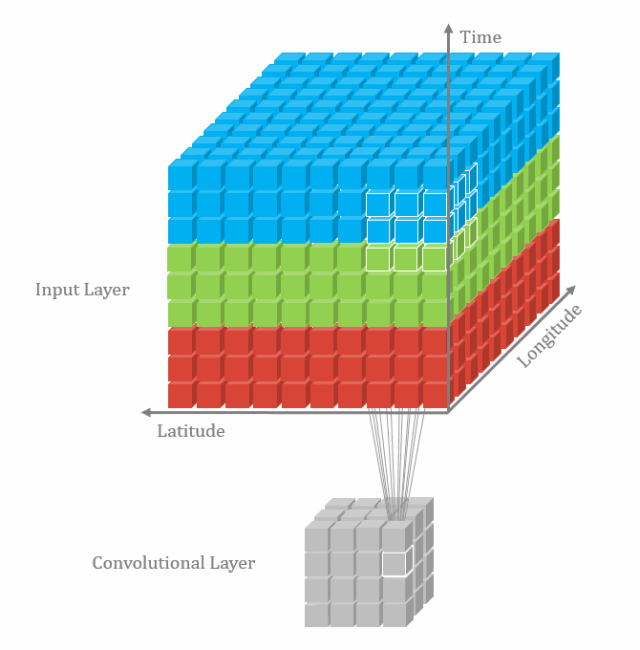
3.4 空间可分离卷积(separable convolution)
在一个可分离卷积中,我们可以将内核操作拆分成多个步骤。我们用y = conv(x,k)表示卷积,其中y是输出图像,x是输入图像,k是内核。这一步很简单。接下来,我们假设k可以由下面这个等式计算得出:k = k1.dot(k2)。这将使它成为一个可分离的卷积,因为我们可以通过对k1和k2做2个一维卷积来取得相同的结果,而不是用k做二维卷积,这样做可以有效的减少超参数的个数(降低计算复杂度)。
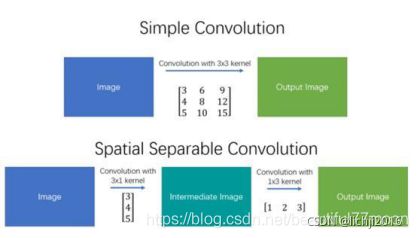
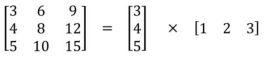
空间卷积用以边缘检测的sobel卷积为主要代表。但是并不是所有的都可以采用此卷积。
3.5 深度可分离卷积(depthwise separable convolution)
常规卷积中,连接的上一层一般具有多个通道(这里假设为n个通道),因此在做卷积时,一个滤波器(filter)必须具有n个卷积核(kernel)来与之对应。一个滤波器完成一次卷积,实际上是多个卷积核与上一层对应通道的特征图进行卷积后,再进行相加,从而输出下一层的一个通道特征图。在下一层中,若需要得到多个通道的特征图(这里假设为m个通道),那么对应的滤波器就需要m个。
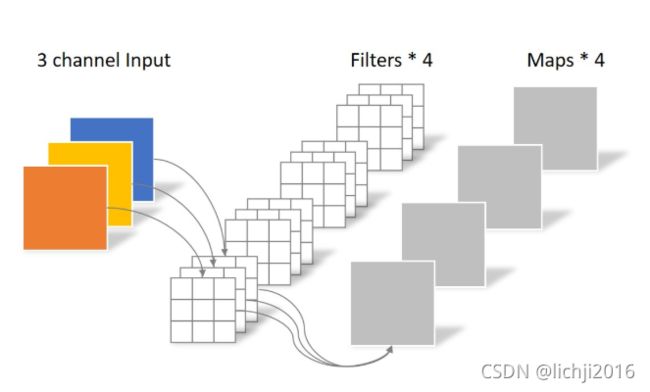
深度可分离的思路是:对于不同的输入channel,采取不同的卷积核进行卷积,将传统的卷积分为两个过程来进行:**对于上一层的多通道特征图,首先将其拆分为单个通道的特征图,分别进行单通道的卷积,然后一起叠加。**它只对上一层特征尺寸进行调整,通道没有变化,然后将前面得到特征进行二次卷积,采用1*1卷积。滤波器包含了与上一层通道数一样数量的卷积核。一个滤波器输出一张特征图,因此多个通道,则需要多个滤波器。这又被称之为逐点卷积(Pointwise Convolution)。
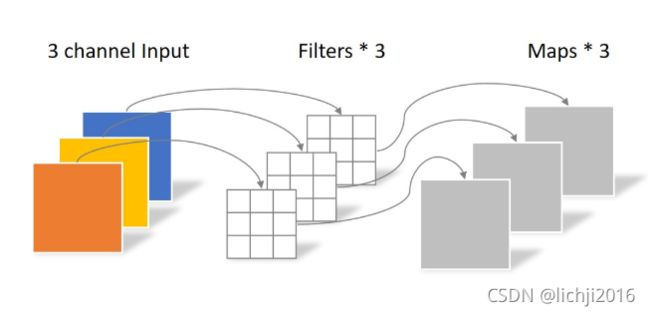
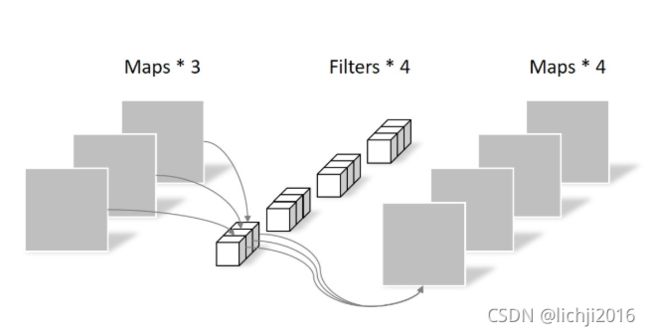
深度可分离卷积比普通卷积减少了所需要的参数。重要的是深度可分离卷积将以往普通卷积操作同时考虑通道和区域改变成,卷积先只考虑区域,然后再考虑通道。实现了通道和区域的分离。
3.6 分组卷积(Group convolution)
最早见于AlexNet——2012年Imagenet的冠军方法,Group Convolution被用来切分网络,使其在2个GPU上并行运行,AlexNet网络结构如下:
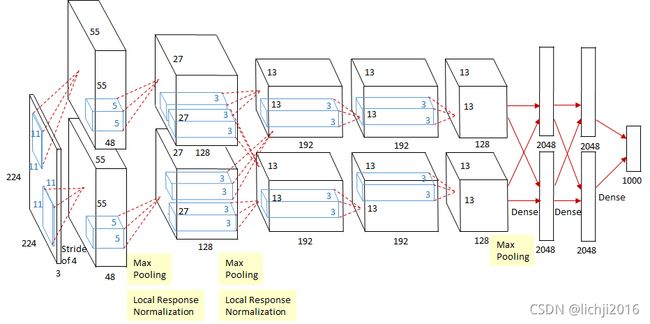
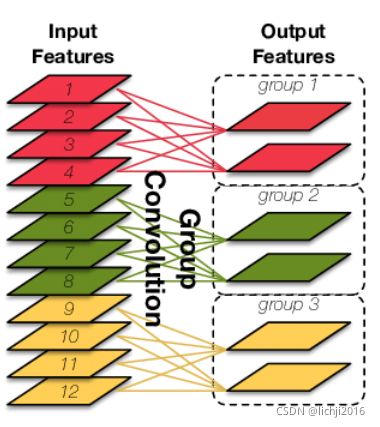
卷积就是输入feature map进行分组,然后每组分别卷积。假设输入feature map的尺寸仍为C∗H∗W,输出feature map的数量为N个,如果设定要分成G个groups,则每组的输入feature map数量为C/G,每组的输出feature map数量为N/G,每个卷积核的尺寸为CG∗K∗K,卷积核的总数仍为N个,每组的卷积核数量为N/G,卷积核只与其同组的输入map进行卷积,卷积核的总参数量为N∗C/G∗K∗K,可见,总参数量减少为原来的 1/G,其连接方式如下图所示,group1输出map数为2,有2个卷积核,每个卷积核的channel数为4,与group1的输入map的channel数相同,卷积核只与同组的输入map卷积,而不与其他组的输入map卷积。
3.7 空洞卷积(Dilated convolution)
空洞卷积(Dilated/Atrous Convolution),广泛应用于语义分割与目标检测等任务中,语义分割中经典的deeplab系列与DUC对空洞卷积进行了深入的思考。目标检测中SSD与RFBNet,同样使用了空洞卷积。空洞卷积可以任意扩大感受野,且不需要引入额外参数,但如果把分辨率增加了,算法整体计算量肯定会增加。
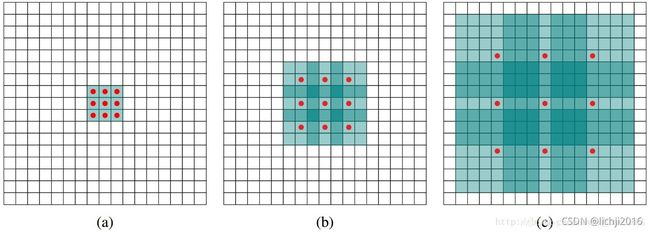
(a)图是33,空洞卷积为1;(b)图是空洞卷积为2;(c)为空洞卷积为4。
其中空洞卷积就是在相应位置加0进行填充,如下所示:空洞卷积为2,在相应位置进行填充0。
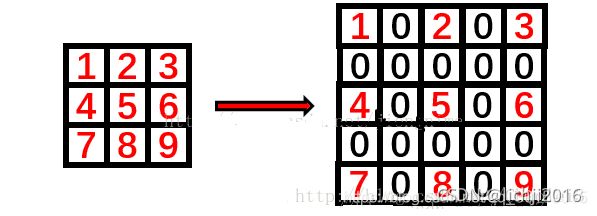
其动态过程如下所示:

上图是一个扩张率为2的3×3卷积核,感受野与5×5的卷积核相同,而且仅需要9个参数。你可以把它想象成一个5×5的卷积核,每隔一行或一列删除一行或一列。
在相同的计算条件下,空洞卷积提供了更大的感受野。空洞卷积经常用在实时图像分割中。当网络层需要较大的感受野,但计算资源有限而无法提高卷积核数量或大小时,可以考虑空洞卷积。
空洞卷积可以增加感受野。感受野计算公式:RF = ((RF -1) stride) + fsize 其中公式里RF为上一层的感受野,第一次一般为1,fsize是kernel size,这个公式是用来计算多层卷积层的感受野的。
感受野计算时有下面的几个情况需要说明:
(1)第一层卷积层的输出特征图像素的感受野的大小等于滤波器的大小
(2)深层卷积层的感受野大小和它之前所有层的滤波器大小和步长有关系
(3)计算感受野大小时,忽略了图像边缘的影响,即不考虑padding的大小
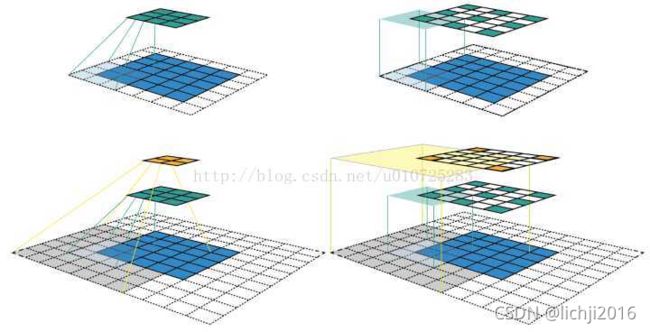
3.8 转置卷积(Transposed convolution)
直观理解就是卷积的反向操作,比如44的图片用33的卷积核卷积,s=1,p=0,得到22的大小图片,反卷积就是要使输入22的输出为4*4的。反卷积的实现原理实际就是卷积,但为了输出大小反而变大,就在输入图片中添加了padding。
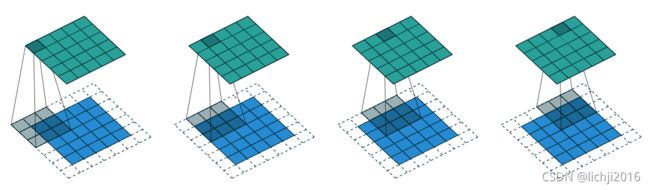
上图所示,输入特征图为 5×5 ,补零为1( padding = 1 ), 使用 3×3 卷积核,卷积核移动的步幅为1( stride = 1 ),则经过卷积操作后,输出特征图的尺寸仍为 5×5 。可以看到,特征图的尺寸未发生变化,而通道数则取决于卷积核的个数。正是这个良好的特性, 使得 3×3 卷积被广泛地应用于卷积神经网络的前端特征提取部分。
以上所涉及到的特征图尺寸计算,可用下面的公式来表示:
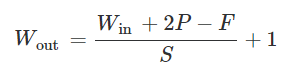
Win -----为输入的特征图宽度或者高度
Wout ----- 为输出的特征图宽度或者高度
P ----- padding取值
F -----卷积核的大小(一般卷积核为方形的)
S ----卷积核移动的步幅
反卷积其实只要调整卷积的一些参数,就可以将小的特征图通过 “卷积” 变成大的特征图,实现上采样操作。这便是所谓的 转置卷积 。
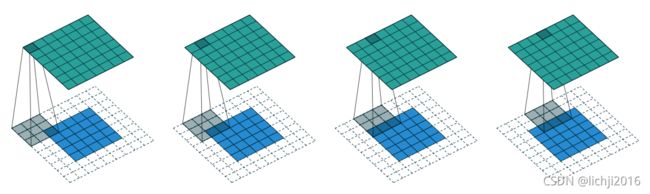
如上图所示,输入特征图为 5×5 ,补零为2( padding = 2 ), 使用 3×3 卷积核,卷积核移动的步幅为1( stride = 1 ),则经过卷积操作后,输出特征图的尺寸为 7×7。
转置卷积一般可用于上采样操作,放大特征图。假设需要完成 n 倍上采样操作,则这些参数之间应该满足:
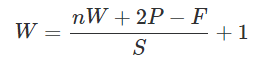
可以推算出:
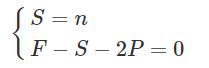
上采用一般是2的倍数,于是可以推导出:
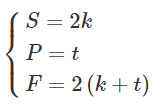
上面公式中k,t取值为1到正无穷的整数。
总结
本文对常见的卷积进行总结,方便后续学习。