PaddlePaddle百度论文复现营——GAN入门学习笔记
PaddlePaddle百度论文复现营——GAN入门学习笔记
1 GAN 概述
什么是生成对抗网络?由谁提出?为什么要学习GAN?
1.1 GAN是什么?
GAN是“Generative Adversarial Networks”三个单词的首字母缩写,表示通过对抗的方式去学习数据分布的生成式模型。GAN的核心思想是通过生成网络G(Generator)和判别网络D(Discriminator)不断博弈,来达到生成类真数据的目的。
补充理解:
1.2 GAN作者
GAN最早是由Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio等人于2014提出,其源码可通过GitHub获取,地址是https://github.com/goodfeli/adversarial
1.3 学习GAN的原因
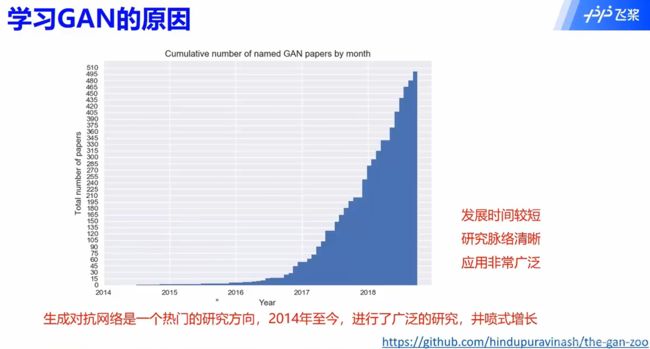

2 原理与改进
GAN的基本原理,GAN的训练方法,GAN的现有问题,GAN的改进方法
2.1 GAN的发展脉络
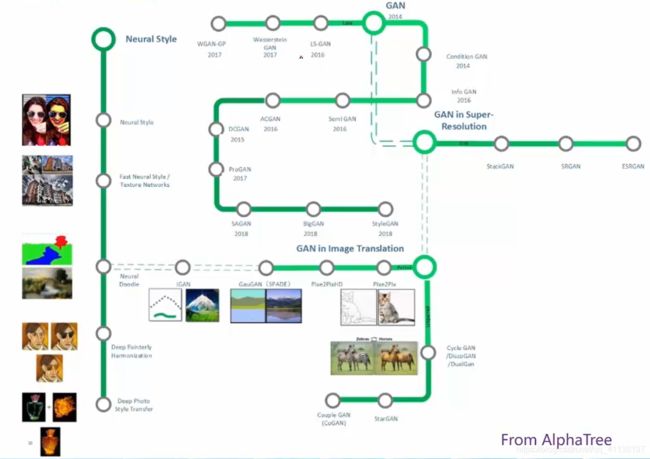
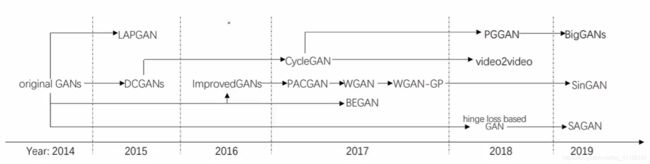
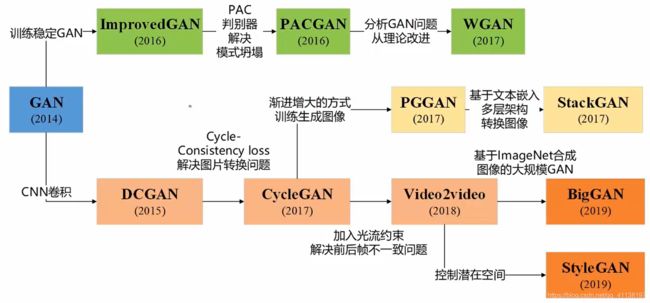
2.2 GAN的原理
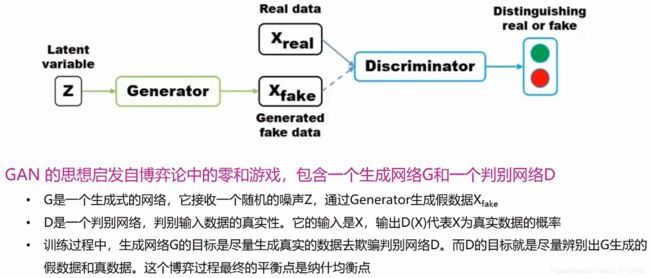
Tip: G生成的是假数据,D用于区分G生成的假数据&输入的真数据。
- 补充理解:
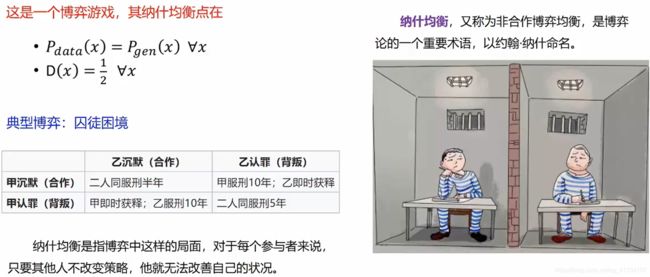
- 纳什均衡(Nash equilibrium)
- 最大似然估计(maximum likelihood estimation, MLE)
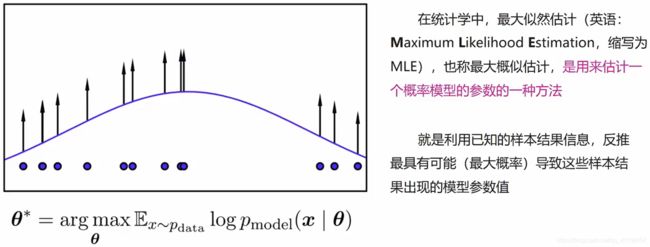
Tip: 如对此概念仍有困惑,可参考https://zhuanlan.zhihu.com/p/26614750
2.3 GAN的目标函数

2.4 GAN的训练方法
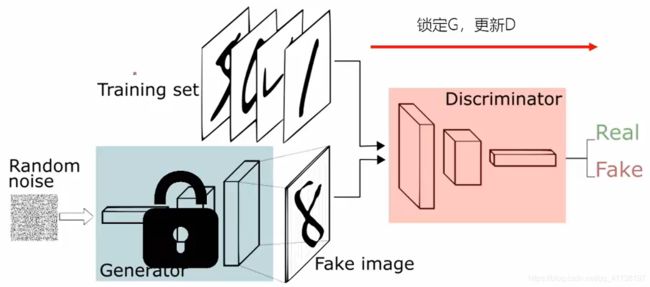
考虑到G,D互相依赖,在训练时通常采取“锁定一个,训练另一个”的策略。通常先锁定G,更新D,待D网络训练一定轮次之后再锁定D,更新G。
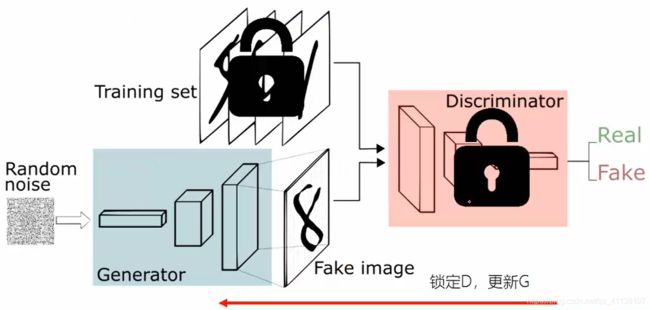
2.5 GAN的训练细节

2.6 GAN的训练可视化
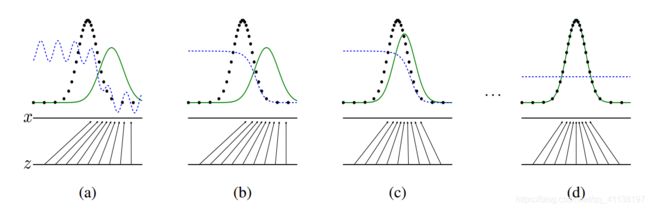
- 虚线点为真实的数据分布,蓝色虚线是判别器,绿色实现为生成器
- 由左至右可看到生成的分布越来越接近真实分布,而判别器的概率最后变为0.5
2.7 GAN的优点

2.8 GAN存在的问题
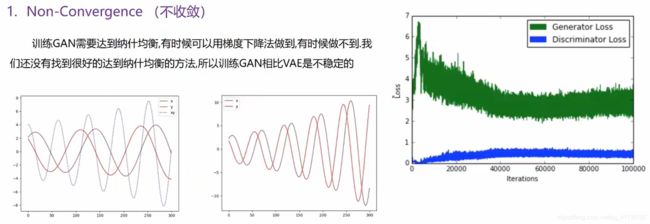
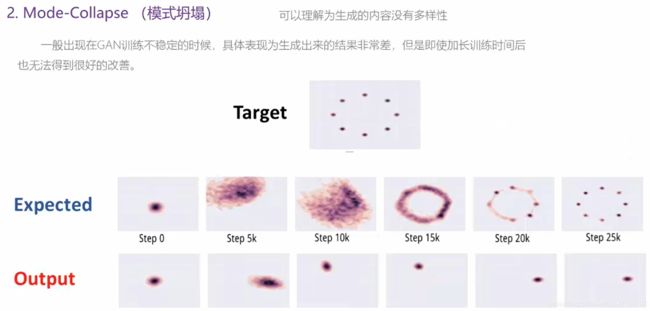

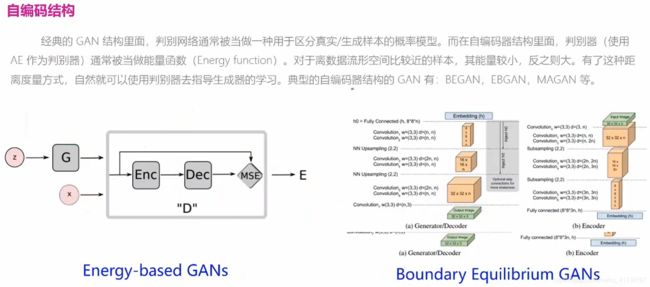
2.9 GAN常见的模型结构

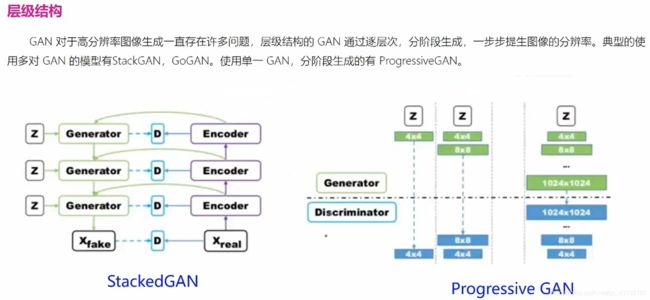
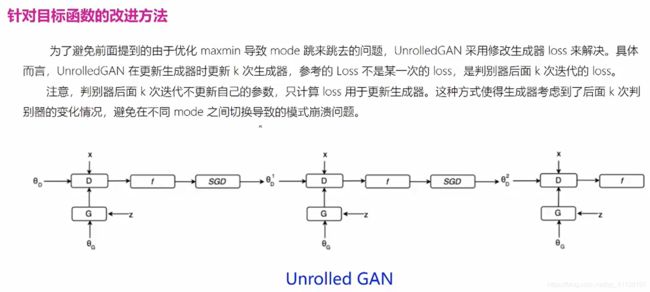
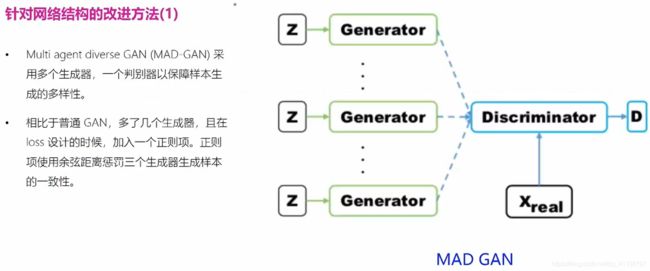
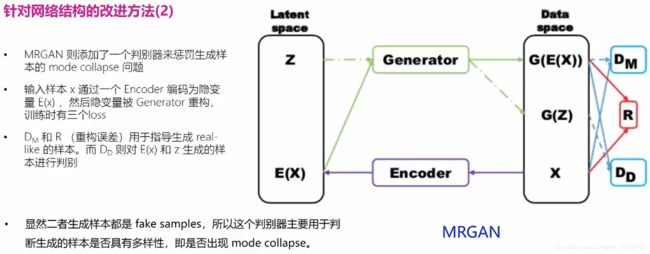
2.10 模式坍塌的解决方案
2.11 Wasserstein GAN(WGAN)

2.12 WGAN解决的问题
2.13 Wasserstein距离


3 应用场景
图像风格迁移,超分辨率图像生成,序列生成,文本风格迁移等场景
3.1 GAN的应用场景
3.2 超分辨率图像生成
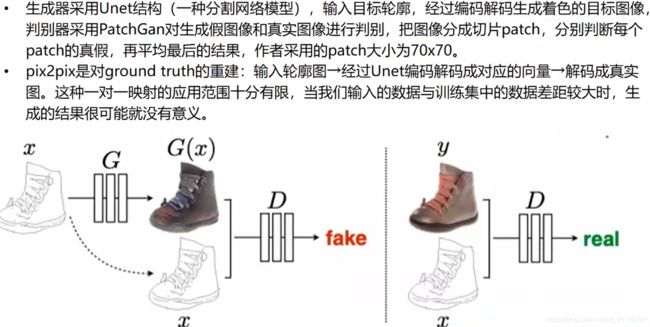
3.3 图像转换
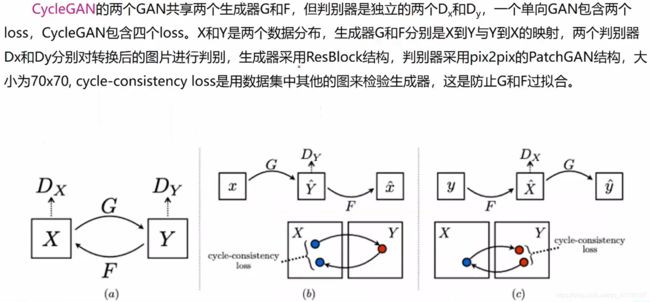
3.4 图像风格迁移
3.5 风格迁移面部生成器
3.6 鉴别图像真伪
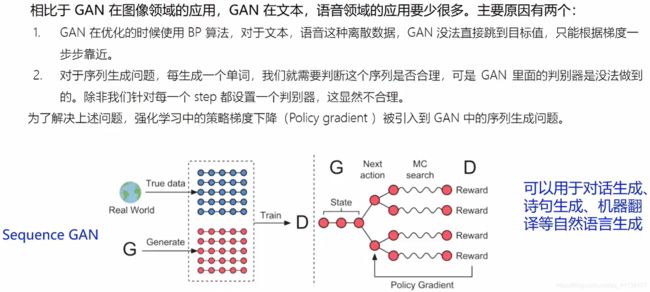
3.7 序列生成
3.8 文本风格迁移
4 课程实践
手写数字生成案例
Step 1 数据准备
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph import Conv2D, Pool2D, Linear
import numpy as np
import matplotlib.pyplot as plt
# 噪声维度
Z_DIM = 100 # 此处将要喂入生成器高斯分布的噪声隐变量z的维度设置为100。
BATCH_SIZE = 128
# 读取真实图片的数据集,这里去除了数据集中的label数据,因为label在这里使用不上,这里不考虑标签分类问题。
def mnist_reader(reader):
def r():
for img, label in reader():
yield img.reshape(1, 28, 28)
return r
# 噪声生成,通过由噪声来生成假的图片数据输入。
def z_reader():
while True:
yield np.random.normal(0.0, 1.0, (Z_DIM, 1, 1)).astype('float32') #正态分布,正态分布的均值、标准差、参数
# 生成真实图片reader
mnist_generator = paddle.batch(paddle.reader.shuffle(mnist_reader(paddle.dataset.mnist.train()), 30000), batch_size=BATCH_SIZE)
# 生成假图片的reader
z_generator = paddle.batch(z_reader, batch_size=BATCH_SIZE)
# 以下部分用来测试数据读取器和高斯噪声生成器
import matplotlib.pyplot as plt
%matplotlib inline
pics_tmp = next(mnist_generator())
print('一个batch图片数据的形状:batch_size =', len(pics_tmp), ', data_shape =', pics_tmp[0].shape)
plt.imshow(pics_tmp[0][0]) # (28,28)
plt.show
Step 2 GAN网络
# 通过上采样扩大特征图
class G(fluid.dygraph.Layer):
def __init__(self, name_scope):
super(G, self).__init__(name_scope)
name_scope = self.full_name()
# My_G的代码
# 第一层全连接和BN层
self.fc1 = Linear(input_dim = 100, output_dim = 1024)
self.bn1 = fluid.dygraph.BatchNorm(num_channels = 1024, act = 'tanh')
# 第二层全连接和BN层
self.fc2 = Linear(input_dim = 1024, output_dim = 128*7*7)
self.bn2 = fluid.dygraph.BatchNorm(num_channels = 128*7*7, act = 'tanh')
# 第一层卷积运算(卷积前进行上采样,以扩大特征图)
self.conv1 = Conv2D(num_channels = 128, num_filters = 64, filter_size = 5, padding = 2)
self.bn3 = fluid.dygraph.BatchNorm(num_channels = 64, act = 'tanh')
# 第二层卷积运算(卷积前进行上采样,以扩大特征图)
self.conv2 = Conv2D(num_channels = 64, num_filters = 1, filter_size = 5, padding = 2, act = 'tanh')
def forward(self, z):
# My_G forward的代码,前向传播
z = fluid.layers.reshape(z, shape = [-1, 100])
y = self.fc1(z)
y = self.bn1(y)
y = self.fc2(y)
y = self.bn2(y)
y = fluid.layers.reshape(y, shape = [-1, 128, 7, 7])
y = fluid.layers.image_resize(y, scale = 2)
y = self.conv1(y)
y = self.bn3(y)
y = fluid.layers.image_resize(y, scale = 2)
y = self.conv2(y)
return y
class D(fluid.dygraph.Layer):
def __init__(self, name_scope):
super(D, self).__init__(name_scope)
name_scope = self.full_name()
# My_D的代码
# 第一层卷积池化
self.conv1 = Conv2D(num_channels=1, num_filters=64, filter_size=3)
self.bn1 = fluid.dygraph.BatchNorm(num_channels = 64, act = 'relu')
self.pool1 = Pool2D(pool_size = 2, pool_stride = 2)
# 第二层卷积池化
self.conv2 = Conv2D(num_channels=64, num_filters=128, filter_size=3)
self.bn2 = fluid.dygraph.BatchNorm(num_channels = 128, act = 'relu')
self.pool2 = Pool2D(pool_size = 2, pool_stride = 2)
# 全连接output层
self.fc1 = Linear(input_dim = 128*5*5, output_dim = 1024)
self.bnfc1 = fluid.dygraph.BatchNorm(num_channels = 1024, act = 'relu')
self.fc2 = Linear(input_dim =1024, output_dim = 1)
def forward(self, img):
# My_G forward的代码
y = self.conv1(img)
y = self.bn1(y)
y = self.pool1(y)
y = self.conv2(y)
y = self.bn2(y)
y = self.pool2(y)
y = fluid.layers.reshape(y, shape = [-1, 128*5*5])
y = self.fc1(y)
y = self.bnfc1(y)
y = self.fc2(y)
return y
# 测试生成网络G和判别网络D
with fluid.dygraph.guard():
g_tmp = G('G')
tmp_g = g_tmp(fluid.dygraph.to_variable(np.array(z_tmp))).numpy()
print('生成器G生成图片数据的形状:', tmp_g.shape)
plt.imshow(tmp_g[0][0])
plt.show()
d_tmp = D('D')
tmp_d = d_tmp(fluid.dygraph.to_variable(tmp_g)).numpy()
print('判别器D判别生成的图片的概率数据形状:', tmp_d.shape)
print(max(tmp_d))
# 显示图片,构建一个16*n大小(n=batch_size/16)的图片阵列,把预测的图片打印到note中。
import matplotlib.pyplot as plt
%matplotlib inline
def show_image_grid(images, batch_size=128, pass_id=None):
fig = plt.figure(figsize=(8, batch_size/32))
fig.suptitle("Pass {}".format(pass_id))
gs = plt.GridSpec(int(batch_size/16), 16)
gs.update(wspace=0.05, hspace=0.05)
for i, image in enumerate(images):
ax = plt.subplot(gs[i])
plt.axis('off')
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_aspect('equal')
plt.imshow(image[0], cmap='Greys_r')
plt.show()
show_image_grid(tmp_g, BATCH_SIZE)
Step 3 网络训练
def train(mnist_generator, epoch_num=1, batch_size=128, use_gpu=True, load_model=False):
place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()
with fluid.dygraph.guard(place):
# 模型存储路径
model_path = './output/'
d = D('D')
d.train()
g = G('G')
g.train()
# 创建优化方法
real_d_optimizer = fluid.optimizer.AdamOptimizer(learning_rate=2e-4, parameter_list=d.parameters())
fake_d_optimizer = fluid.optimizer.AdamOptimizer(learning_rate=2e-4, parameter_list=d.parameters())
g_optimizer = fluid.optimizer.AdamOptimizer(learning_rate=2e-4, parameter_list=g.parameters())
# 读取上次保存的模型
if load_model == True:
g_para, g_opt = fluid.load_dygraph(model_path+'g')
d_para, d_r_opt = fluid.load_dygraph(model_path+'d_o_r')
# 上面判别器的参数已经读取到d_para了,此处无需再次读取
_, d_f_opt = fluid.load_dygraph(model_path+'d_o_f')
g.load_dict(g_para)
g_optimizer.set_dict(g_opt)
d.load_dict(d_para)
real_d_optimizer.set_dict(d_r_opt)
fake_d_optimizer.set_dict(d_f_opt)
iteration_num = 0
for epoch in range(epoch_num):
for i, real_image in enumerate(mnist_generator()):
# 丢弃不满整个batch_size的数据
if(len(real_image) != BATCH_SIZE):
continue
iteration_num += 1
'''
判别器d通过最小化输入真实图片时判别器d的输出与真值标签ones的交叉熵损失,来优化判别器的参数,
以增加判别器d识别真实图片real_image为真值标签ones的概率。
'''
# 将MNIST数据集里的图片读入real_image,将真值标签ones用数字1初始化
real_image = fluid.dygraph.to_variable(np.array(real_image))
ones = fluid.dygraph.to_variable(np.ones([len(real_image), 1]).astype('float32'))
# 计算判别器d判断真实图片的概率
p_real = d(real_image)
# 计算判别真图片为真的损失
real_cost = fluid.layers.sigmoid_cross_entropy_with_logits(p_real, ones)
real_avg_cost = fluid.layers.mean(real_cost)
# 反向传播更新判别器d的参数
real_avg_cost.backward()
real_d_optimizer.minimize(real_avg_cost)
d.clear_gradients()
'''
判别器d通过最小化输入生成器g生成的假图片g(z)时判别器的输出与假值标签zeros的交叉熵损失,
来优化判别器d的参数,以增加判别器d识别生成器g生成的假图片g(z)为假值标签zeros的概率。
'''
# 创建高斯分布的噪声z,将假值标签zeros初始化为0
z = next(z_generator())
z = fluid.dygraph.to_variable(np.array(z))
zeros = fluid.dygraph.to_variable(np.zeros([len(real_image), 1]).astype('float32'))
# 判别器d判断生成器g生成的假图片的概率
p_fake = d(g(z))
# 计算判别生成器g生成的假图片为假的损失
fake_cost = fluid.layers.sigmoid_cross_entropy_with_logits(p_fake, zeros)
fake_avg_cost = fluid.layers.mean(fake_cost)
# 反向传播更新判别器d的参数
fake_avg_cost.backward()
fake_d_optimizer.minimize(fake_avg_cost)
d.clear_gradients()
'''
生成器g通过最小化判别器d判别生成器生成的假图片g(z)为真的概率d(fake)与真值标签ones的交叉熵损失,
来优化生成器g的参数,以增加生成器g使判别器d判别其生成的假图片g(z)为真值标签ones的概率。
'''
# 生成器用输入的高斯噪声z生成假图片
fake = g(z)
# 计算判别器d判断生成器g生成的假图片的概率
p_confused = d(fake)
# 使用判别器d判断生成器g生成的假图片的概率与真值ones的交叉熵计算损失
g_cost = fluid.layers.sigmoid_cross_entropy_with_logits(p_confused, ones)
g_avg_cost = fluid.layers.mean(g_cost)
# 反向传播更新生成器g的参数
g_avg_cost.backward()
g_optimizer.minimize(g_avg_cost)
g.clear_gradients()
# 打印输出
if epoch < 45:
if(iteration_num % 500 == 0):
print('epoch =', epoch, ', batch =', i, ', real_d_loss =', real_avg_cost.numpy(), ', fake_d_loss =', fake_avg_cost.numpy(), 'g_loss =', g_avg_cost.numpy())
show_image_grid(fake.numpy(), BATCH_SIZE, epoch)
else:
if(iteration_num % 100 == 0):
print('epoch =', epoch, ', batch =', i, ', real_d_loss =', real_avg_cost.numpy(), ', fake_d_loss =', fake_avg_cost.numpy(), 'g_loss =', g_avg_cost.numpy())
show_image_grid(fake.numpy(), BATCH_SIZE, epoch)
# 存储模型
fluid.save_dygraph(g.state_dict(), model_path+'g')
fluid.save_dygraph(g_optimizer.state_dict(), model_path+'g')
fluid.save_dygraph(d.state_dict(), model_path+'d_o_r')
fluid.save_dygraph(real_d_optimizer.state_dict(), model_path+'d_o_r')
fluid.save_dygraph(d.state_dict(), model_path+'d_o_f')
fluid.save_dygraph(fake_d_optimizer.state_dict(), model_path+'d_o_f')
train(mnist_generator, epoch_num=50, batch_size=BATCH_SIZE, use_gpu=True)