卷积神经网络 递归神经网络
Artificial intelligence (AI) is bridging the gap between technology and humans by allowing machines to automatically learn things from data and become more ‘human-like’; thus, becoming more ‘intelligent’. In this case, intelligence can be considered to be the ability to process information which can be used to inform future decisions. This is ideal because humans can spontaneously put information together by recognizing old patterns, developing new connections, and perceiving something that they have learnt in a new light to develop new and effective processes. When combined with a machine’s computational power, tremendous results can be achieved.
人工智能(AI)通过允许机器自动从数据中学习事物并变得更像“人类”来弥合技术与人类之间的鸿沟。 因此,变得更加“智能”。 在这种情况下,可以将智能视为处理信息的能力,该信息可用于为将来的决策提供依据。 之所以理想,是因为人们可以通过识别旧模式,建立新的联系并感知他们以新的视角学到的东西来自动开发信息,从而开发出新的有效流程。 与机器的计算能力相结合,可以获得巨大的结果。
The combination of automatic learning and computational efficiency can best be described by deep learning. This is a subset of AI and machine learning (ML) where algorithms are made to determine a pattern in data and develop a target function which best maps an input variable, x, to a target variable, y. The goal here is to automatically extract the most useful pieces of information needed to inform future decisions. Deep learning models are very powerful and they can be used to tackle a wide variety of problems; from predicting the likelihood that a student will pass a course, to recognizing an individual’s face to unlock their iPhones using Face ID.
深度学习可以最好地描述自动学习和计算效率的结合。 这是AI和机器学习(ML)的子集,在其中进行算法以确定数据中的模式并开发目标函数,该函数最好将输入变量x映射到目标变量y 。 这里的目标是自动提取最有用的信息,以为将来的决策提供依据。 深度学习模型非常强大,可用于解决各种问题。 从预测学生通过课程的可能性,到识别人脸以使用Face ID解锁iPhone。
Deep learning models are built on the idea of ‘neural networks’, and this is what allows the models to learn from raw data. Simply put, the deep neural network is created by stacking perceptrons, which is a single neuron. Information is propagated forward through this system by having a set of inputs, x, and each input has a corresponding weight, w. The input should also include a ‘bias term’ which is independent of x. The bias term is used to shift the function being used accordingly, given a problem at hand. Each corresponding input and weight are then multiplied, and the sum of products is calculated. The sum then passes through a non-linear activation function, and an output, y, is generated.
深度学习模型是基于“神经网络”的思想构建的,这使模型可以从原始数据中学习。 简而言之,深层神经网络是通过堆叠感知器(单个神经元)创建的。 通过具有一组输入x ,信息通过该系统向前传播,并且每个输入具有对应的权重w 。 输入还应包括一个独立于x的“偏差项”。 给定当前的问题,可以使用偏置项来相应地改变所使用的功能。 然后将每个相应的输入和权重相乘,然后计算出乘积之和。 然后,该和通过非线性激活函数,并生成输出y 。
However, this ‘feed-forward’ type of model is not always applicable, and their fundamental architecture makes it difficult to apply them to certain scenarios. For example, consider a model that is designed to predict where a flying object will go to next, given a snapshot of that flying object. This is a sequential problem because the object will be covering some distance over time, and the current position of the object will depend on where the object was previously. If no information about the object’s previous position is given, then predicting where the object will go next is no better than a random guess.
但是,这种“前馈”类型的模型并不总是适用,并且它们的基本体系结构使其很难将它们应用于某些情况。 例如,考虑一个模型,该模型被设计为在给定飞行物体快照的情况下预测该飞行物体将要到达的位置。 这是一个顺序问题,因为随着时间的推移,对象将覆盖一定距离,并且对象的当前位置将取决于对象先前所在的位置。 如果没有给出有关对象的先前位置的信息,那么预测对象下一步将去的地方并不比随机猜测更好。

Let us consider another simple, yet important problem: predicting the next word. Models which do this are common now as they are used in applications such as autofill and autocorrect, and they are often taken for granted. This is a sequential task since the most appropriate ‘next word’ depends on the words which came before it. A feed-forward network would not be appropriate for this task because it would require a sentence with a particular length as an input to then predict the next word. However, this is an issue because we cannot guarantee an input of the same length each time, and the model’s performance would then be negatively affected.
让我们考虑另一个简单但重要的问题:预测下一个单词。 执行此操作的模型现在很普遍,因为它们被用于诸如自动填充和自动更正之类的应用程序中,并且通常被认为是理所当然的。 这是一个顺序的任务,因为最合适的“下一个单词”取决于之前的单词。 前馈网络不适用于该任务,因为它将需要一个具有特定长度的句子作为输入,然后才能预测下一个单词。 但是,这是一个问题,因为我们不能保证每次输入的长度都是相同的,这样会对模型的性能造成负面影响。
A potential way to combat this issue is to only look at a subsection of this input sentence, such as the last two words maybe. This combats the issue of variable-length inputs because, despite the total input length, the model will only use the last two words of the sentence to predict the next word. But this is still not ideal because the model now cannot account for long-term dependencies. That is, consider the sentence “I grew up in Berlin and only moved to New York a year ago. I can speak fluent …”. By only considering the last two words, every language would be equally likely. But when the entire sentence is considered, German would be most likely.
解决此问题的一种潜在方法是仅查看此输入句子的一个小节,例如最后两个单词。 这解决了可变长度输入的问题,因为尽管输入总长度很大,但是该模型将仅使用句子的最后两个单词来预测下一个单词。 但这仍然不是理想的,因为该模型现在无法解决长期依赖性。 也就是说,请考虑以下句子:“我在柏林长大,一年前才搬到纽约。 我会说流利的……”。 仅考虑最后两个词,每种语言的可能性均等。 但是当考虑整个句子时,德语很有可能会出现。
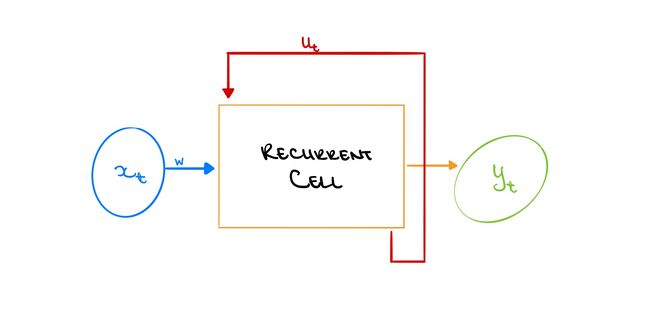
The best way to overcome these issues is to have an entirely new network structure; one that can update information over time. This is a Recurrent Neural Network (RNN). This is similar to a perceptron in that over time, information is being forward through the system by a set of inputs, x, and each input has a weight, w. Each corresponding input and weight are then multiplied, and the sum of products is calculated. The sum then passes through a non-linear activation function, and an output, y, is generated.
解决这些问题的最佳方法是拥有一个全新的网络结构。 一种可以随着时间更新信息的工具。 这是递归神经网络(RNN)。 这类似于感知器,随着时间的流逝,信息由一组输入x通过系统转发,并且每个输入的权重w 。 然后将每个相应的输入和权重相乘,然后计算出乘积之和。 然后,该和通过非线性激活函数,并生成输出y 。
The difference is that, in addition to the output, the network is also generating an internal state update, u. This update is then used when analyzing the next set of input information and provides a different output that is also dependent on the previous information. This is ideal because information persists throughout the network over time. As the name suggests, this update function is essentially a recurrence relation that happens at every step of the sequential process, where u is a function of the previous u and the current input, x.
区别在于,除了输出之外,网络还生成内部状态更新u 。 然后,在分析下一组输入信息时使用此更新,并提供一个也取决于先前信息的不同输出。 这是理想的,因为随着时间的推移,信息会在整个网络中持续存在。 顾名思义,此更新函数本质上是在顺序过程的每个步骤中发生的递归关系,其中u是上一个u和当前输入x的函数。
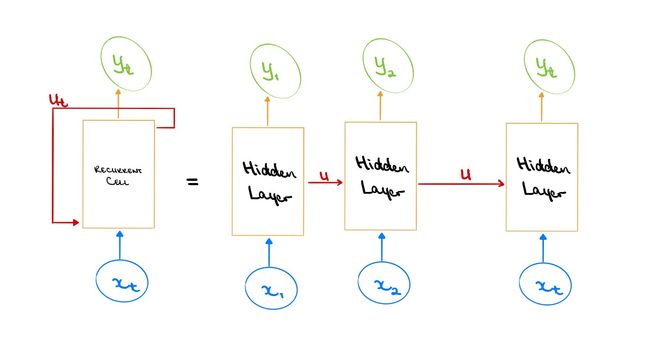
The concept of looping through the RNN’s system over time might be a bit abstract and difficult to grasp. Another way to think of an RNN is to actually unfold this system over time. That is, think of the RNN as a set of singular feed-forward models, where each model is linked together by the internal state update. Viewing the RNN like this can truly provide some insight as to why this structure is suitable for sequential tasks. At each step of the sequence, there is an input, some process being performed on that input, and a related output. For the next step of the sequence, the step before must have some influence does not affect the input but affects the related output.
随着时间的流逝,循环遍历RNN系统的概念可能有点抽象并且难以掌握。 想到RNN的另一种方法是随着时间的推移实际展开该系统。 也就是说,将RNN视为一组奇异的前馈模型,其中每个模型都通过内部状态更新链接在一起。 像这样查看RNN可以真正提供一些有关为什么此结构适合于顺序任务的见解。 在序列的每个步骤中,都有一个输入,对该输入执行一些处理,以及相关的输出。 对于序列的下一个步骤,之前的步骤必须具有一定的影响力,但不会影响输入,但会影响相关的输出。
If we go back to either the flying object scenario or the word prediction scenario, and we consider them using the unfolded RNN, we would be able to understand the solutions more. At each previous position of the flying object, we can predict a possible path. The predicted path updates as the model receives more information about where the object was previously, and this information updates itself to then feed into the future sequences of the model. Similarly, as each new word from the sentence scenario is fed into the model, a new combination of likely words is generated.
如果我们回到飞行物体场景或单词预测场景,并使用展开的RNN考虑它们,我们将能够更多地了解解决方案。 在飞行物体的每个先前位置,我们可以预测一条可能的路径。 当模型接收到有关对象先前所在位置的更多信息时,预测的路径会更新,并且此信息会更新自身,然后输入到模型的未来序列中。 类似地,当将来自句子场景的每个新单词输入到模型中时,将生成可能单词的新组合。
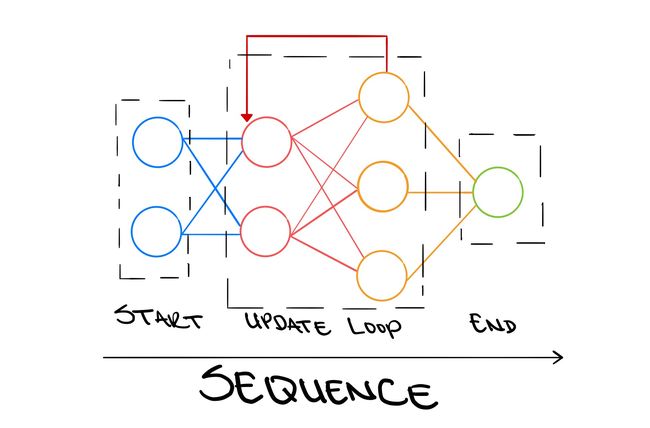
Neural networks are an essential part of AI and ML as they allow models to automatically learn from data, and they combine a version of human learning with great computational ability. However, applying a non-sequential structure to a sequential task will result in poor model performance, and the true power of neural networks would not be harnessed. RNNs are artificial learning systems which internally update themselves based on previous information, in order to predict the most accurate results over time.
神经网络是AI和ML的重要组成部分,因为它们允许模型自动从数据中学习,并且将人类学习的一种版本与强大的计算能力结合在一起。 但是,将非顺序结构应用于顺序任务将导致较差的模型性能,并且无法利用神经网络的真正功能。 RNN是人工学习系统,可以根据以前的信息在内部进行自我更新,以便预测一段时间内最准确的结果。
dspace.mit.edu/bitstream/handle/1721.1/113146/1018306404-MIT.pdf?sequence=1
dspace.mit.edu/bitstream/handle/1721.1/113146/1018306404-MIT.pdf?sequence=1
stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks
stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks
wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
karpathy.github.io/2015/05/21/rnn-effectiveness/
karpathy.github.io/2015/05/21/rnn-efficiency/
Other Useful Material:
其他有用的材料:
deeplearning.mit.edu/
deeplearning.mit.edu/
neuralnetworksanddeeplearning.com/
neuronetworksanddeeplearning.com/
towardsdatascience.com/what-is-deep-learning-adf5d4de9afc
向datascience.com/what-is-deep-learning-adf5d4de9afc
towardsdatascience.com/the-mathematics-behind-deep-learning-f6c35a0fe077
向datascience.com/the-mathematics-behind-deep-learning-f6c35a0fe077
翻译自: https://towardsdatascience.com/introducing-recurrent-neural-networks-f359653d7020
卷积神经网络 递归神经网络