Gated-SCNN: Gated Shape CNNs for Semantic Segmentation
目录
作者
一、Model of Gated-SCNN
二、 Gated Shape CNN
1.Regular Stream
2.Shape Stream
3. Gate Conv Layer
4.ASPP
5 总代码
三 损失函数
1.BoundaryBCELoss
2.DualTaskLoss
作者

一、Model of Gated-SCNN
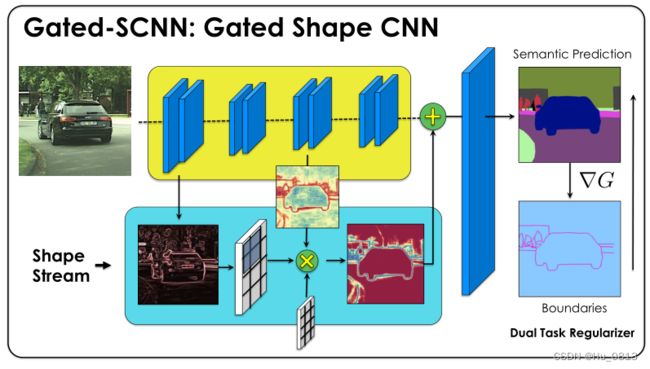
文章使用了双流CNN来处理语义分割中的边界问题,分为Regular stream 和 Shape stream.
作者认为,在编码器提取的很多特征中,例如纹理,色彩,梯度等很多细节信息,随着卷积的不断加深,会干扰定位信息,因为包含了很多与识别无关的信息,比如整体图中的背景信息,树的细节信息对于网络分割而言,属于噪声,但是轮廓这种信息又不能完全舍去(汽车轮廓).
综上,作者将形状信息作为一个单独的分支,目的是只提取对应的轮廓信息,对应图中的shape stream
二、 Gated Shape CNN

1.Regular Stream
作者使用主流的 Resnet-101 and WideResNet 作为本文的Regular stream,对输入的2D图像提取了分辨率不同的5种特征图。我们把这五种特征图记作 c1,c2,c3,c4,c5. 与此同时,在输入图像时,提取了 图像的梯度 image gradients (channel==1). 记为 grad
2.Shape Stream
1. 在shape stream 中,使用了c1,c3,c4,c5以及grad 作为形状流的输入。
2. c3,c4,c5 先经过1x1卷积降为残差结构(channel==1)对应代码中self.res()_conv. channel of c1 保持不变(64),之后将所有特征图上采样到原图大小(size of grad).
3. 在2的基础上,shape stream 会通过3个residual block,将通道数再次降低一半。
4. 在通过residual block之后,会分别与c3,c4,c5进入Gate Conv Layer 得到最终通道数为8的特征 图gate3,再次将gate3降维至1并转化为权重分数表示得到gate。
5. gate 与 grad 以第一维度(channel)拼接融合,形成新的权重。作者也对gate进行了边界损失,防止边界预测错误。最终 shape stream 输出的feat 作为针对形状的预测与regular stream 特征进行融合(加强边界信息)。
因为edge bce loss的原因,会限制其他细节的得分,例如,色彩,斑点,纹理,以及一些小的梯度,都会被bce loss在反向传播的过程中逐层减弱。 这也是形状流只关注形状的主要原因。
class ShapeStream(nn.Module):
def __init__(self):
super().__init__()
self.res2_conv = nn.Conv2d(512, 1, 1)
self.res3_conv = nn.Conv2d(1024, 1, 1)
self.res4_conv = nn.Conv2d(2048, 1, 1)
self.res1 = BasicBlock(64, 64, 1)
self.res2 = BasicBlock(32, 32, 1)
self.res3 = BasicBlock(16, 16, 1)
self.res1_pre = nn.Conv2d(64, 32, 1)
self.res2_pre = nn.Conv2d(32, 16, 1)
self.res3_pre = nn.Conv2d(16, 8, 1)
self.gate1 = GatedConv(32, 32)
self.gate2 = GatedConv(16, 16)
self.gate3 = GatedConv(8, 8)
self.gate = nn.Conv2d(8, 1, 1, bias=False)
self.fuse = nn.Conv2d(2, 1, 1, bias=False)
def forward(self, c1, c2, c3, c4, grad):
size = grad.size()[-2:]
c1 = F.interpolate(c1, size, mode='bilinear', align_corners=True)
c2 = F.interpolate(self.res2_conv(c2), size, mode='bilinear', align_corners=True)
c3 = F.interpolate(self.res3_conv(c3), size, mode='bilinear', align_corners=True)
c4 = F.interpolate(self.res4_conv(c4), size, mode='bilinear', align_corners=True)
gate1 = self.gate1(self.res1_pre(self.res1(c1)), c2)
gate2 = self.gate2(self.res2_pre(self.res2(gate1)), c3)
gate3 = self.gate3(self.res3_pre(self.res3(gate2)), c4)
gate = torch.sigmoid(self.gate(gate3))
feat = torch.sigmoid(self.fuse(torch.cat((gate, grad), dim=1)))
return gate, feat3. Gate Conv Layer
需要注意的是 每次进入GCL层的 feat的channel为 32,16,8. gate channel ==1
class GatedConv(nn.Conv2d):
def __init__(self, in_channels, out_channels):
super().__init__(in_channels, out_channels, 1, bias=False)
self.attention = nn.Sequential(
nn.BatchNorm2d(in_channels + 1),
nn.Conv2d(in_channels + 1, in_channels + 1, 1),
nn.ReLU(),
nn.Conv2d(in_channels + 1, 1, 1),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
def forward(self, feat, gate):
attention = self.attention(torch.cat((feat, gate), dim=1))
out = F.conv2d(feat * (attention + 1), 1, out_channels)
return out4.ASPP
最终ASPP的输入是c1 c4 以及 feat,rate of dilation are 6,12,and 18.
class FeatureFusion(ASPP):
def __init__(self, in_channels, atrous_rates=(6, 12, 18), out_channels=256):
# atrous_rates (6, 12, 18) is for stride 16
super().__init__(in_channels, atrous_rates, out_channels)
self.shape_conv = nn.Sequential(
nn.Conv2d(1, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU())
self.project = nn.Conv2d((len(atrous_rates) + 3) * out_channels, out_channels, 1, bias=False)
self.fine = nn.Conv2d(256, 48, kernel_size=1, bias=False)
def forward(self, c1, c4, feat):
res = []
for conv in self.convs:
res.append(conv(c4))
res = torch.cat(res, dim=1)
feat = F.interpolate(feat, res.size()[-2:], mode='bilinear', align_corners=True)
res = torch.cat((res, self.shape_conv(feat)), dim=1)
coarse = F.interpolate(self.project(res), c1.size()[-2:], mode='bilinear', align_corners=True)
fine = self.fine(c1)
out = torch.cat((coarse, fine), dim=1)
return out5 总代码
class GatedSCNN(nn.Module):
def __init__(self, backbone_type='resnet50', num_classes=19):
super().__init__()
self.regular_stream = RegularStream(backbone_type)
self.shape_stream = ShapeStream()
self.feature_fusion = FeatureFusion(2048, (12, 24, 36), 256)
self.seg = nn.Sequential(
nn.Conv2d(256 + 48, 256, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, num_classes, kernel_size=1, bias=False))
def forward(self, x, grad):
x, res1, res2, res3, res4 = self.regular_stream(x)
gate, feat = self.shape_stream(x, res2, res3, res4, grad)
out = self.feature_fusion(res1, res4, feat)
seg = F.interpolate(self.seg(out), grad.size()[-2:], mode='bilinear', align_corners=False)
# [B, N, H, W], [B, 1, H, W]
return seg, gate三 损失函数
1.BoundaryBCELoss
torch.clamp 的作用是将输入的tensor 缩放到最小值和最大值之间
edge是网络预测的输出,而boundary 是针对 GT 的边界
class BoundaryBCELoss(nn.Module):
def __init__(self, ignore_index=255):
super().__init__()
self.ignore_index = ignore_index
def forward(self, edge, target, boundary):
edge = edge.squeeze(dim=1)
mask = target != self.ignore_index
pos_mask = (boundary == 1.0) & mask
neg_mask = (boundary == 0.0) & mask
num = torch.clamp(mask.sum(), min=1)
pos_weight = neg_mask.sum() / num
neg_weight = pos_mask.sum() / num
weight = torch.zeros_like(boundary)
weight[pos_mask] = pos_weight
weight[neg_mask] = neg_weight
loss = F.binary_cross_entropy(edge, boundary, weight, reduction='sum') / num
return loss2.DualTaskLoss
threshold的作用是将太细的梯度过滤
class DualTaskLoss(nn.Module):
def __init__(self, threshold=0.8, ignore_index=255):
super().__init__()
self.threshold = threshold
self.ignore_index = ignore_index
def forward(self, seg, edge, target):
edge = edge.squeeze(dim=1)
logit = F.cross_entropy(seg, target, ignore_index=self.ignore_index, reduction='none')
mask = target != self.ignore_index
num = torch.clamp(((edge > self.threshold) & mask).sum(), min=1)
loss = (logit[edge > self.threshold].sum()) / num
return loss