毕业设计-基于大数据的电影推荐系统-python
目录
前言
课题背景和意义
实现技术思路
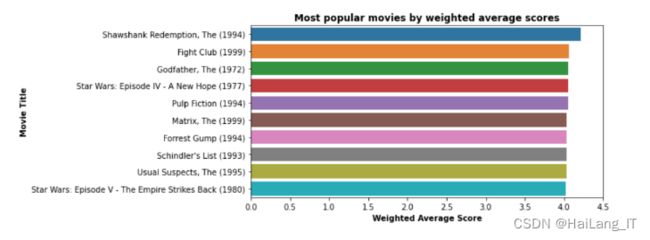
实现效果图样例
前言
大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
基于大数据的电影推荐系统
课题背景和意义
随着现代科技生产力的发展, 人们在空闲时间中逐渐开 始追求更高要求的娱乐活动, 而电影就是最为普遍的娱乐方 式之一。 不管是喜剧还是悲剧,都能勾起你纯真的眼泪;不管 是动作片还是恐怖片,都能让你的肾上腺大开大合;不管是科 幻片还是纪录片,都能让你云游古今中外。 不管是去电影院, 或是购买影碟,或是在网上观赏影片前,人们总是有选择性地 去寻找一些更符合自己喜好的、内容精致的、更受欢迎的电影 去观看。 但是,如今影片的拍摄逐渐走向高产化,佳片许多,烂 片也层出不穷,如果采用人工方法,在大量电影影片中找到自 己真正喜欢的电影是一个耗费精力的事情。 本文通过大数据挖掘技术构建了一个智能的电影推荐系 统,针对不同用户,提供多个与其过去的观影信息相似度较高 的符合该用户喜好的电影,满足用户的观影需求。 本文使用了 kaggle 网站中 TMDB 5000 Movie Dataset 的电影数据集, 主要 结合应用分类统计(Class Statistics)、样本相似度(Correlation) 分析等经典数据挖掘算法,剖析数据间的关系,从而完成电影 推荐系统的相关功能。 用户为系统提供一个电影的名称,该系 统提供与这部电影在类型、内容、受欢迎程度、年代等综合程 度最相似的五部影片。
实现技术思路
相似度
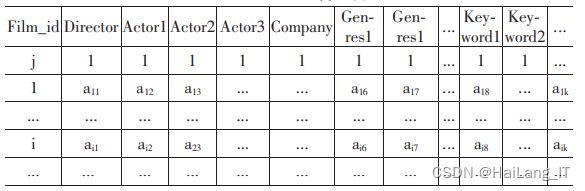
(1)用户给推荐系统提供一个自己喜欢的电影 j,取出电 影 j 的导演、三位最重要的演员、电影所属的各个电影类型、 各个预处理后的关键字。 (2)计算电影数据库中的每个电影和电影 j 的距离值,取 距离值最小的前 30 个电影。 在计算推荐候选电影 i 和用户所 选电影 j 的距离值 dij 时,首先我们根据 i 和 j 是否有相同的导 演、演员、制作公司、电影类型、关键 字,得到各个 a 的值。 举 例:如果 i 和 j 的导演相同,那 ai1 值为 1,否则 ai1 值值为 0;同 理其他属性的距离值 ai2,ai3,...,aik 也是这么求得。 然后使用欧几里得距离公式计算 dij,公式如下:
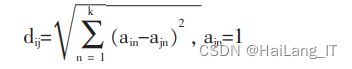
计算每部电影的加权平均分
目标是为我们推荐系统的最终用户提供一个流行电影的目录,他们可以从中选择自己喜欢的电影。
import os
from pyspark.sql.functions import mean, col
"""路径设置"""
data_path = os.environ['DATA_PATH']
movies_datapath = os.path.join(data_path, 'Movies/MovieLens/movies_data-100k')
trained_datapath = os.path.join(movies_datapath, 'Already_Trained')
"""加载数据集"""
ratings = spark.read.load(os.path.join(movies_datapath, 'ratings.csv'), format='csv', header=True, inferSchema=True).drop("timestamp")
movies = spark.read.load(os.path.join(movies_datapath, 'movies.csv'), format='csv', header=True, inferSchema=True)
"""计算每部电影的平均评分和评分数量"""
df = ratings.join(movies, on="movieId")
number_ratings = df.groupBy('movieId').count()
average_ratings = df.groupBy('movieId').avg('rating')
df_ratings = average_ratings.join(number_ratings, on="movieId")
df = df.join(df_ratings, on="movieId")
mostRatedMovies = df.where("count >= 50")
"""计算每部电影的加权平均分"""
# 我们必须将'vote_count'列从字符串类型转换为double类型(数值型),以便计算分位数
changedTypedf = mostRatedMovies.withColumn("vote_count", df["count"].cast("double"))
quantile_df = changedTypedf.approxQuantile("count", [0.75], 0)
m = quantile_df[0]
# collect()用于在驱动程序中以数组的形式返回数据集的所有元素。
mean_df = mostRatedMovies.select(mean(col('avg(rating)')).alias('mean')).collect()
C = mean_df[0]['mean']
movies_cleaned_df = mostRatedMovies.withColumn("weighted_average", ((mostRatedMovies['avg(rating)']*mostRatedMovies['count']) + (C*m)) / (mostRatedMovies['count']+m))
"""将表保存到CSV文件中以供以后访问"""
movies_cleaned_pd.to_csv(os.path.join(trained_datapath, 'MostPopularMovies.csv'), index=False)使用k近邻(kNN)
首先,它帮助用户放心,因为他至少会认出推荐的电影之一。事实上,如果他不认识任何推荐的电影,他可能会拒绝我们系统的有用性。不幸的是,这一心理和人的因素是无法量化的。这也证明,如果不考虑文化方面,最好的数学和统计模型可能不适合一些用户。
其次,使用kNN算法推荐的电影都是“流行”的,这是在训练机器学习模型之前对数据进行预先过滤的直接结果。
事实上,我们数据集中的评估频率遵循“长尾”分布。这意味着大多数电影的收视率非常低,而“少数压倒性”的收视率远远高于其他电影的总和。因此,这个过滤器只允许使用最流行的电影来训练kNN算法,因此得到的推荐也只能是流行电影。
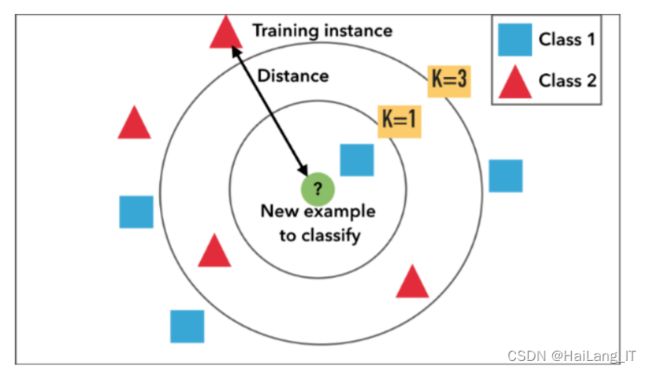
该算法还具有易于理解和解释的优点。对于非技术人员来说尤其如此,比如你公司的销售团队,或者仅仅是你的朋友和家人,他们不一定对数据科学十分理解。“当KNN对一部电影进行推断时,KNN将计算目标电影与其数据库中其他每部电影之间的‘距离’,然后对其距离进行排序,并返回前K个最近邻居电影作为最相似的电影推荐”。
from scipy.sparse import csr_matrix
from sklearn.neighbors import NearestNeighbors
import numpy as np
import pandas as pd
"""创建透视表"""
movies_pivot = mostRatedMovies.groupBy('title').pivot('userId').sum('rating').fillna(0)
movie_features_df = movies_pivot.toPandas().set_index('title')
movie_features_df_matrix = csr_matrix(movie_features_df.values)
"""使用整个数据集拟合最终的无监督模型,以找到每一个最相似的电影"""
model_knn = NearestNeighbors(metric='cosine', algorithm='brute', n_neighbors=11, n_jobs=-1)
model_knn.fit(movie_features_df_matrix)
# 选择一个标题
favoriteMovie = 'Iron Man (2008)'
query_index = movie_features_df.index.get_loc(favoriteMovie)
distances, indices = model_knn.kneighbors(movie_features_df.loc[favoriteMovie,:].values.reshape(1, -1), n_neighbors=11)
# 根据kNN模型打印10部最相似的电影
for i in range(0, len(distances.flatten())):
if i == 0:
print('Recommendations for {0}:\n'.format(movie_features_df.index[query_index]))
else:
print('{0}: {1}, with distance of {2}:'.format(i, movie_features_df.index[indices.flatten()[i]], distances.flatten()[i]))使用深层神经矩阵分解
神经网络的加入使得进一步提高模型的预测性能成为可能,从而减少预测和实际评分之间的误差。
实现效果图样例

我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!