Pytorch总结十一之 神经网络模型:LeNet、AlexNet、VGG
Pytorch总结十之 神经网络模型:LeNet、AlexNet、VGG
1.卷积神经网络 LENET
在多层感知机的从零开始实现⾥我们构造了⼀个含单隐藏层的多层感知机模型来对Fashion-MNIST数据集中的图像进⾏分类。每张图像⾼和宽均是28像素。我们将图像中的像素逐⾏展开,得到⻓度为784的向量,并输⼊进全连接层中。然⽽,这种分类⽅法有⼀定的局限性。
- 1.图像在同⼀列邻近的像素在这个向量中可能相距较远。它们构成的模式可能难以被模型识别。
- 2.对于⼤尺⼨的输⼊图像,使⽤全连接层容易造成模型过⼤。假设输⼊是⾼和宽均为
1000像素的彩⾊照⽚(含 3 个通道)。即使全连接层输出个数仍是256,该层权重参数的形状是3000000x256:它占⽤了⼤约3 GB的内存或显存。这带来过复杂的模型和过⾼的存储开销。
- 卷积层尝试解决这两个问题。⼀⽅⾯,卷积层保留输⼊形状,使图像的像素在⾼和宽两个⽅向上的相关性均可能被有效识别;另⼀⽅⾯,卷积层通过滑动窗⼝将同⼀卷积核与不同位置的输⼊重复计算,从⽽避免参数尺⼨过⼤。
- 卷积神经⽹络就是含卷积层的⽹络。将介绍⼀个早期⽤来识别⼿写数字图像的卷积神经⽹络:
LeNet。这个名字来源于LeNet论⽂的第⼀作者Yann LeCun。LeNet展示了通过梯度下降训练卷积神经⽹络可以达到⼿写数字识别在当时最先进的结果。这个奠基性的⼯作第⼀次将卷积神经⽹络推上舞台,为世⼈所知。 - LeNet的⽹络结构如下图所示。
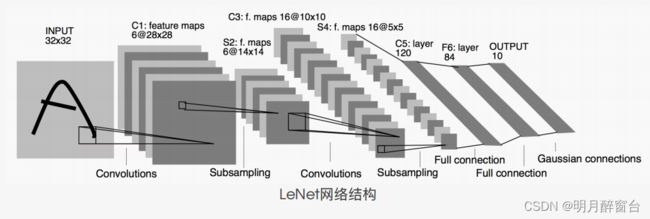
1.1 LENET 模型
- 卷积层块⾥的基本单位是卷积层后接最⼤池化层:卷积层⽤来识别图像⾥的空间模式,如线条和物体局部,之后的最⼤池化层则⽤来降低卷积层对位置的敏感性。卷积层块由两个这样的基本单位重复堆叠构成。在卷积层块中,每个卷积层都使⽤
5x5的窗⼝,并在输出上使⽤sigmoid激活函数。第⼀个卷积层输出通道数为6,第⼆个卷积层输出通道数则增加到16。这是因为第⼆个卷积层⽐第⼀个卷积层的输⼊的⾼和宽要⼩,所以增加输出通道使两个卷积层的参数尺⼨类似。卷积层块的两个最⼤池化层的窗⼝形状均为2x2,且步幅为2。由于池化窗⼝与步幅形状相同,池化窗⼝在输⼊上每次滑动所覆盖的区域互不重叠。 - 卷积层块的输出形状为(批量⼤⼩, 通道, ⾼, 宽)。当卷积层块的输出传⼊全连接层块时,全连接层块会将⼩批量中每个样本变平(flatten)。也就是说,全连接层的输⼊形状将变成⼆维,其中第⼀维是⼩批量中的样本,第⼆维是每个样本变平后的向量表示,且向量⻓度为通道、⾼和宽的乘积。全连接层块含3个全连接层。它们的输出个数分别是120、84和10,其中10为输出的类别个数。
- 下⾯我们通过
Sequential类来实现LeNet模型。
import time
import torch
from torch import nn,optim
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
self.conv=nn.Sequential(nn.Conv2d(1,6,5), #in_channels,out_channels,kernel_size
nn.Sigmoid(),
nn.MaxPool2d(2,2),
nn.Conv2d(6,16,5),
nn.Sigmoid(),
nn.MaxPool2d(2,2))
self.fc=nn.Sequential(
nn.Linear(16*4*4,120),
nn.Sigmoid(),
nn.Linear(120,84),
nn.Sigmoid(),
nn.Linear(84,10)
)
def forward(self,img):
feature=self.conv(img)
output=self.fc(feature.view(img.shape[0],-1))
return output
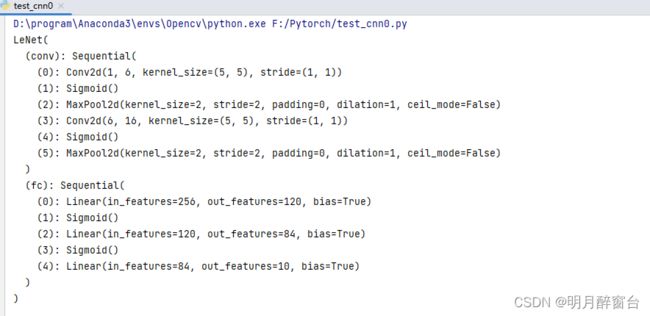
net=LeNet()
print(net)
可以看到,在卷积层块中输⼊的⾼和宽在逐层减⼩。卷积层由于使⽤⾼和宽均为5的卷积核,从⽽将⾼和宽分别减⼩4,⽽池化层则将⾼和宽减半,但通道数则从1增加到16。全连接层则逐层减少输出个数,直到变成图像的类别数10。
output:
1.2 获取数据和训练模型
实验LeNet模型,使用 Fashion-MNIST 作为训练数据集:
batch_size=256
train_iter,test_iter=d2l.load_data_fashion_mnist(batch_size=batch_size)
因为卷积神经⽹络计算⽐多层感知机要复杂,建议使⽤GPU来加速计算。因此,我们对softmax
回归的从零开始实现 中描述的 evaluate_accuracy 函数略作修改,使其⽀持GPU计算。
# 本函数已保存在d2lzh_pytorch包中⽅便以后使⽤。该函数将被逐步改进。
def evaluate_accuracy(data_iter, net, device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')):
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X.to(device)).argmax(dim=1) ==y.to(device)).float().sum().cpu().item()
net.train() # 改回训练模式
else: # ⾃定义的模型, 3.13节之后不会⽤到, 不考虑GPU
if ('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数
# 将is_training设置成False
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
我们同样对定义的 train_ch3 函数略作修改,确保计算使⽤的数据和模型同在内存或显存上。
def train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs):
net = net.to(device)
print("training on ", device)
loss = torch.nn.CrossEntropyLoss()
batch_count = 0
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = d2l.evaluate_accuracy(test_iter, net) #我用的cpu,所以这里不用修改的方法
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f,time % .1fsec'
% (epoch + 1, train_l_sum / batch_count,train_acc_sum / n, test_acc, time.time() - start))
#学习率采⽤0.001,训练算法使⽤Adam算法,损失函数使⽤交叉熵损失函数。
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
train_ch5(net, train_iter, test_iter, batch_size, optimizer, device,num_epochs)
2.深度卷积神经网络 ALEXNET
简介:
- 在
LeNet提出后的将近20年⾥,神经⽹络⼀度被其他机器学习⽅法超越,如⽀持向量机。虽然LeNet可以在早期的⼩数据集上取得好的成绩,但是在更⼤的真实数据集上的表现并不尽如⼈意。⼀⽅⾯,神经⽹络计算复杂。虽然20世纪90年代也有过⼀些针对神经⽹络的加速硬件,但并没有像之后GPU那样⼤量普及。因此,训练⼀个多通道、多层和有⼤量参数的卷积神经⽹络在当年很难完成。另⼀⽅⾯,当年研究者还没有⼤量深⼊研究参数初始化和⾮凸优化算法等诸多领域,导致复杂的神经⽹络的训练通常较困难。- 从上⼀节看到,神经⽹络可以直接基于图像的原始像素进⾏分类。这种称为端到端(
end-to-end)的⽅法节省了很多中间步骤。然⽽,在很⻓⼀段时间⾥更流⾏的是研究者通过勤劳与智慧所设计并⽣成的⼿⼯特征。这类图像分类研究的主要流程是:
1. 获取图像数据集;
2. 使⽤已有的特征提取函数⽣成图像的特征;
3. 使⽤机器学习模型对图像的特征分类。- 当时认为的机器学习部分仅限最后这⼀步。如果那时候跟机器学习研究者交谈,他们会认为机器学习既重要⼜优美。优雅的定理证明了许多
分类器的性质。机器学习领域⽣机勃勃、严谨⽽且极其有⽤。然⽽,如果跟计算机视觉研究者交谈,则是另外⼀幅景象。他们会告诉你图像识别⾥“不可告⼈”的现实是:计算机视觉流程中真正重要的是数据和特征。也就是说,使⽤较⼲净的数据集和较有效的特征甚⾄⽐机器学习模型的选择对图像分类结果的影响更⼤。- 即
机器学习分类器的重要程度与深度学习数据处理和提取特征的能力
2.1 学习特征表示


2.2 AlexNet
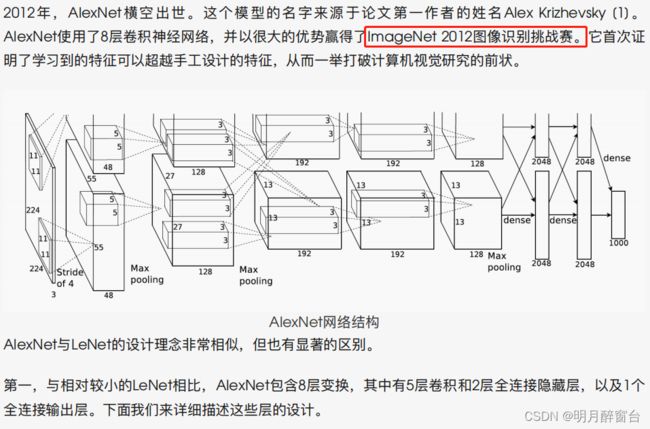

下边实现稍微简化过的AlexNet:
#AlexNet
import time
import torch
from torch import nn,optim
import torchvision
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__() #对继承自父类的属性进行初始化。而且是用父类的初始化方法来初始化继承的属性。
def __init__(self):
super(AlexNet, self).__init__()
# 定义卷积层
self.conv = nn.Sequential(
nn.Conv2d(1, 96, 11, 4), # in_channels, out_channels,kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减⼩卷积窗⼝,使⽤填充为2来使得输⼊与输出的⾼和宽⼀致,且增⼤输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使⽤更⼩的卷积窗⼝。除了最后的卷积层外,进⼀步增⼤了输出通道数。
# 前两个卷积层后不使⽤池化层来减⼩输⼊的⾼和宽
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2))
# 这⾥全连接层的输出个数⽐LeNet中的⼤数倍。使⽤丢弃层来缓解过拟合
self.fc = nn.Sequential(
nn.Linear(256 * 5 * 5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
# 输出层。由于这⾥使⽤Fashion-MNIST,所以⽤类别数为10,⽽⾮论⽂中的1000
nn.Linear(4096, 10), )
# 定义前向通道
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
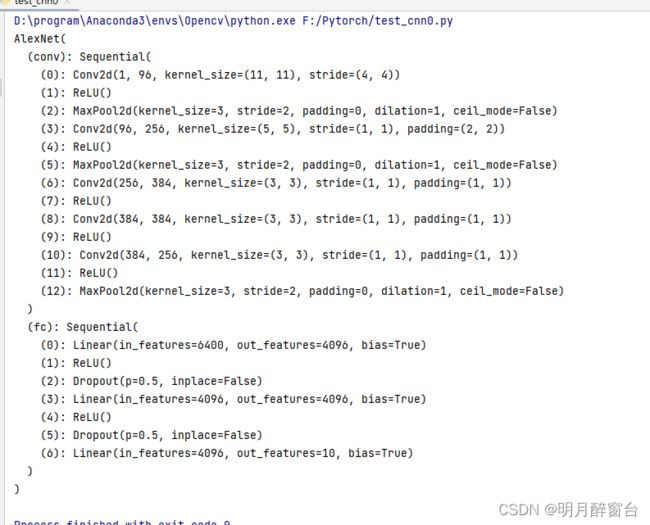
# 打印网络结构
net = AlexNet()
print(net)
output:
2.3 读取数据
虽然论⽂中AlexNet使⽤ImageNet数据集,但因为ImageNet数据集训练时间较⻓,我们仍⽤前⾯的
Fashion-MNIST数据集来演示AlexNet。读取数据的时候我们额外做了⼀步将图像⾼和宽扩⼤到AlexNet使⽤的图像⾼和宽224。这个可以通过 torchvision.transforms.Resize 实例来实现。也就是说,我们在 ToTensor 实例前使⽤ Resize 实例,然后使⽤ Compose 实例来将这两个变换串联以⽅便调⽤。
#读取数据:
# 本函数已保存在d2lzh_pytorch包中⽅便以后使⽤
def load_data_fashion_mnist(batch_size, resize=None, root='~/Datasets/FashionMNIST'):
"""Download the fashion mnist dataset and then load into memory."""
trans = []
if resize:
trans.append(torchvision.transforms.Resize(size=resize))
trans.append(torchvision.transforms.ToTensor())
transform = torchvision.transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root=root,train=True, download=True, transform=transform)
mnist_test = torchvision.datasets.FashionMNIST(root=root,train=False, download=True, transform=transform)
#num_workers,设置多进程数量,默认为0,若保存runtime,则改为0
train_iter = torch.utils.data.DataLoader(mnist_train,batch_size=batch_size, shuffle=True, num_workers=0)
test_iter = torch.utils.data.DataLoader(mnist_test,batch_size=batch_size, shuffle=False, num_workers=0)
return train_iter, test_iter
batch_size = 128
# 如出现“out of memory”的报错信息,可减⼩batch_size或resize
train_iter, test_iter = load_data_fashion_mnist(batch_size,resize=224)
2.4 训练
以开始训练AlexNet了。相对于LeNet,由于图⽚尺⼨变⼤了⽽且模型变⼤了,所以需要更⼤的显存,也需要更⻓的训练时间了。
#开始训练:
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer,device, num_epochs)
我用的cpu,太慢了,直接贴个结果吧:
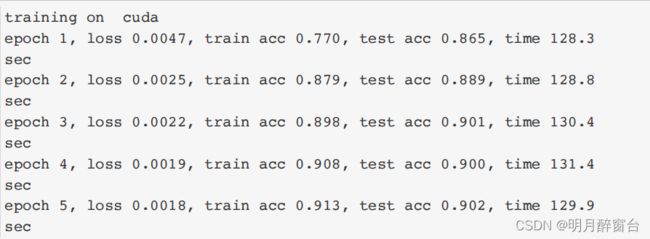
2.5 小结
- AlexNet跟LeNet结构类似,但使⽤了更多的卷积层和更⼤的参数空间来拟合⼤规模数据集ImageNet。它是浅层神经⽹络和深度神经⽹络的分界线。
- 虽然看上去AlexNet的实现⽐LeNet的实现也就多了⼏⾏代码⽽已,但这个观念上的转变和真正优秀实验结果的产⽣令学术界付出了很多年。
3.使用重复元素的网络(VGG)
AlexNet在LeNet的基础上增加了3个卷积层。但AlexNet作者对它们的卷积窗⼝、输出通道数和构造顺序均做了⼤量的调整。虽然AlexNet指明了深度卷积神经⽹络可以取得出⾊的结果,但并没有提供简单的规则以指导后来的研究者如何设计新的⽹络。- 本节介绍
VGG,它的名字来源于论⽂作者所在的实验室Visual Geometry Group [1]。VGG提出了可以通过重复使⽤简单的基础块来构建深度模型的思路。
3.1 VGG块
- VGG块的组成规律是:连续使⽤数个相同的填充为1、窗⼝形状为
3x3的卷积层后接上⼀个步幅为2、窗⼝形状为2x2的最⼤池化层。卷积层保持输⼊的⾼和宽不变,⽽池化层则对其减半。我们使⽤vgg_block函数来实现这个基础的VGG块,它可以指定卷积层的数量和输⼊输出通道数。 - 对于给定的感受野(与输出有关的输⼊图⽚的局部⼤⼩),采⽤堆积的⼩卷积核优于采⽤⼤的卷积核,因为可以增加⽹络深度来保证学习更复杂的模式,⽽且代价还⽐较⼩(参数更少)。例如,在
VGG中,使⽤了3个3x3卷积核来代替7x7卷积核,使⽤了2个3x3卷积核来代替5*5卷积核,这样做的主要⽬的是在保证具有相同感知ᰀ的条件下,提升了⽹络的深度,在⼀定程度上提升了神经⽹络的效果。
import time
import torch
from torch import nn,optim
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def vgg_block(num_convs,in_channels,out_channels):
blk=[]
for i in range(num_convs):
if i==0:
blk.append(nn.Conv2d(in_channels,out_channels,kernel_size=3,padding=1)) #padding 填充
else:
blk.append(nn.Conv2d(out_channels,out_channels,kernel_size=3,padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2,stride=2)) #这里是宽高减半
return nn.Sequential(*blk)
3.2 VGG网络
- 与
AlexNet和LeNet一样,VGG网络由卷积层模块后接全连接层模块构成。卷积层模块串联数个vgg_block,其超参数由变量conv_arch定义。该变量指定了每个VGG块里卷积层个数和输入输出通道数。全连接模块则跟AlexNet中的一样。 - 现在我们构造一个
VGG网络,他有5个卷积块,前两块使用单卷积层,而后3块使用双卷积层。第一块的输入输出通道分别是1(因为下⾯要使⽤的Fashion-MNIST数据的通道数为1)和64,之后每次对输出通道数翻倍,直到变为512。因为这个⽹络使⽤了8个卷积层和3个全连接层,所以经常被称为VGG-11。
conv_arch = ((1, 1, 64), (1, 64, 128), (2, 128, 256), (2, 256, 512),(2, 512, 512))
# 经过5个vgg_block, 宽⾼会减半5次, 变成 224/32 = 7
fc_features = 512 * 7 * 7 # c * w * h
fc_hidden_units = 4096 # 任意
下边实现VGG-11:
#下边 实现VGG-11
def vgg(conv_arch, fc_features, fc_hidden_units=4096):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过⼀个vgg_block都会使宽⾼减半
net.add_module("vgg_block_" + str(i+1),vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module("fc", nn.Sequential(d2l.FlattenLayer(),nn.Linear(fc_features,fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5), #丢弃法防止过拟合
nn.Linear(fc_hidden_units,fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 10)))
return net
下⾯构造⼀个⾼和宽均为224的单通道数据样本来观察每⼀层的输出形状。
#构造一个高和宽均为224的单通道数据样本来观察每一层的输出形状
net = vgg(conv_arch, fc_features, fc_hidden_units)
X = torch.rand(1, 1, 224, 224)
# named_children获取⼀级⼦模块及其名字(named_modules会返回所有⼦模块,包括⼦模块的⼦模块)
for name, blk in net.named_children():
X = blk(X)
print(name, 'output shape: ', X.shape)
output:

可以看到,每次我们将输⼊的⾼和宽减半,直到最终⾼和宽变成 7 后传⼊全连接层。与此同时,输出通道数每次翻倍,直到变成 512。因为每个卷积层的窗⼝⼤⼩⼀样,所以每层的模型参数尺⼨和计算复杂度与输⼊⾼、输⼊宽、输⼊通道数和输出通道数的乘积成正⽐。VGG这种⾼和宽减半以及通道翻倍的设计使得多数卷积层都有相同的模型参数尺⼨和计算复杂度。
3.3 获取数据和训练模型
因为VGG-11计算上⽐AlexNet更加复杂,出于测试的⽬的我们构造⼀个通道数更⼩,或者说更窄的⽹络在Fashion-MNIST数据集上进⾏训练。
#加载数据集和构造模型:
ratio = 8
small_conv_arch = [(1, 1, 64//ratio), (1, 64//ratio, 128//ratio),(2, 128//ratio, 256//ratio),
(2, 256//ratio, 512//ratio), (2, 512//ratio,512//ratio)]
net = vgg(small_conv_arch, fc_features // ratio, fc_hidden_units //ratio)
print(net)
output:
Sequential(
(vgg_block_1): Sequential(
(0): Conv2d(1, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_2): Sequential(
(0): Conv2d(8, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_3): Sequential(
(0): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_4): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_5): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): FlattenLayer()
(1): Linear(in_features=3136, out_features=512, bias=True)
(2): ReLU()
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=512, out_features=512, bias=True)
(5): ReLU()
(6): Dropout(p=0.5, inplace=False)
(7): Linear(in_features=512, out_features=10, bias=True)
)
)
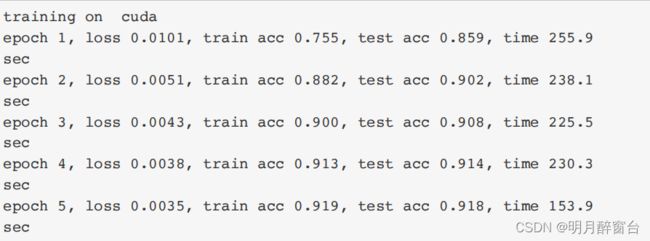
模型训练过程与上⼀节的AlexNet中的类似。
#训练
batch_size = 64
# 如出现“out of memory”的报错信息,可减⼩batch_size或resize
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size,resize=224)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer,device, num_epochs)
3.4 小结
VGG-11通过5个可以重复使⽤的卷积块来构造⽹络。根据每块⾥卷积层个数和输出通道数的不同可以定义出不同的VGG模型。