Windows下Labelimg标注自己的数据集使用(Ubuntu18.04)Jetson AGX Orin进行YOLO5训练测试完整版教程
一、环境配置介绍
整个实现过程所涉及的文件目录,其中,自备表示自己需要准备的,生成表示无需自己准备。
使用yolov5时出现“assertionerror:no labels found in */*/*/JPEGImages.cache can not train without labels”问题
很多朋友都会遇到的一个问题,yolo5-6.1已经不能使用之前的方法了了,是下载源码后的coco示例。
nvidia@nvidia-desktop:~/works/yolov5-6.1$ cat data/coco128.yaml
# YOLOv5 by Ultralytics, GPL-3.0 license
# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: python train.py --data coco128.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco128 ← downloads here
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
nc: 80 # number of classes
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush'] # class names
# Download script/URL (optional)
| 检测目标 | 类型 | 标注工具 | 标注格式 | 训练工具 |
|---|---|---|---|---|
| 笔 | "open" | labelimg | pascalVOC | YOLO5 |
二、目录结构
整个实现过程所涉及的文件目录,其中,自备表示自己需要准备的,生成表示无需自己准备。
首先录取视频获取图片,在d盘下创建目录dataSet,然后再dataSet内分别创建目录images、和video目录,如下:
import cv2
import os.path
import random
# 检查已有图片的数量,确定本次图片抽取开始的下标
cnt = len(os.listdir('D:/dataSet/images')) + 1
# 视频存放路径
videoDir = os.listdir('D:/dataSet/video')
# 提示使用者抽取开始
print("Start!")
# 每30帧随机抽取一帧
start, ran = 0, random.randrange(0, 30)
try:
temp = 0
for video in videoDir:
# 拼接视频路径
videoPath = r'D:/dataSet/video/' + video
# 打开视频流
vc = cv2.VideoCapture(videoPath)
# 判断是否打开成功
if vc.isOpened():
while True:
# activity: 读取成功标签,frame: 读取的画面
activity, frame = vc.read()
# 如果读取不成功(没有下一帧),就退出
if not activity:
break
if temp == start + ran:
cv2.imwrite(f"D:/VOCdevkit/VOC2007/PEGImages/{cnt}.jpg", frame)#这里的路径是提前建好的
cnt, start, ran = cnt + 1, start + 30, random.randrange(0, 30)
temp = temp + 1
vc.release()
# 提示抽取完成
print("Finish!")
except:
vc.release()
# 提示抽取出现错误
print("Error!")
内容为空 。
从视频素材中抽取画面
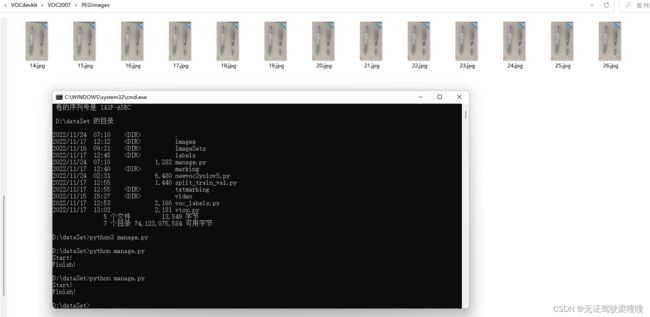
在cmd窗口进入d盘,输入命令:
python manage.py出现“Finish!”即为抽取完成,效果如下:
使用labelimg
完成前面的工作后,在控制台输入labelimg:



最终目录架构,test的目录不是必须的,现在的版本是没用到
D:\VOCdevkit>tree
卷 DATA1 的文件夹 PATH 列表
卷序列号为 141F-A5EC
D:.
├─images
│ ├─test
│ ├─train
│ └─val
├─labels
│ ├─test
│ ├─train
│ └─val
└─VOC2007
├─Annotations
├─PEGImages
└─YOLOLabels三、操作步骤
使用图如下代码即可将标注的文件.xml格式文件转为.txt格式
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
# 根据自己的数据标签修改
classes=["pen", "pen"]
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('D:/VOCdevkit/VOC2007/Annotations/%s.xml' % image_id, encoding='UTF-8' )
out_file = open('D:/VOCdevkit/VOC2007/YOLOLabels/%s.txt' % image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, 'D:/VOCdevkit/')
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, 'D:/VOCdevkit/VOC2007/')
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, 'D:/VOCdevkit/VOC2007/Annotations/')
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, 'D:/VOCdevkit/VOC2007/PEGImages/')
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, 'D:/VOCdevkit/VOC2007/YOLOLabels/')
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, 'images/')
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, 'labels/')
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, 'train/')
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, 'val/')
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_images_val_dir = os.path.join(yolov5_images_dir, 'test/')
if not os.path.isdir(yolov5_images_val_dir):
os.mkdir(yolov5_images_val_dir)
clear_hidden_files(yolov5_images_val_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, 'train/')
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, 'val/')
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
yolov5_labels_val_dir = os.path.join(yolov5_labels_dir, 'test/')
if not os.path.isdir(yolov5_labels_val_dir):
os.mkdir(yolov5_labels_val_dir)
clear_hidden_files(yolov5_labels_val_dir)
train_file = open(os.path.join(wd, 'yolov5_train.txt'), 'w')
test_file = open(os.path.join(wd, 'yolov5_val.txt'), 'w')
val_file = open(os.path.join(wd, 'yolov5_tes.txt'), 'w')
train_file.close()
test_file.close()
val_file.close()
train_file = open(os.path.join(wd, 'yolov5_train.txt'), 'a')
test_file = open(os.path.join(wd, 'yolov5_val.txt'), 'a')
val_file = open(os.path.join(wd, 'yolov5_test.txt'), 'a')
list_imgs = os.listdir(image_dir) # list image files
probo = random.randint(1, 100)
print("Probobility: %d" % probo)
for i in range(0,len(list_imgs)):
path = os.path.join(image_dir,list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
probo = random.randint(1, 100)
print("Probobility: %d" % probo)
if(probo < 80): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
elif(80 <=probo < 90): # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
else: # val dataset
if os.path.exists(annotation_path):
val_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_val_dir + voc_path)
copyfile(label_path, yolov5_labels_val_dir + label_name)
train_file.close()
test_file.close()
val_file.close()然后将整个文档上传到Jetson下的yolo5同级路径下的文件夹内。
![]()
在yolov5-6.1/data/.yaml中先复制一份,改名为ljx.yaml(意义为自己的参数配置)ljx.yaml文件需要修改的参数是nc与names以及你的训练测试路径。nc是标签名个数,names就是标签的名字。
训练集测试集验证集关系如下s
在yolov5-6.1/models先复制一份yolov5s.yaml至ljxs.yaml,更名ljxs.yaml(意为模型),只将如下的nc修改为训练集种类即可
四、开始训练
python3 train.py --img 640 --batch 8 --epochs 300 --data ../../yolov5-6.1/data/ljx.yaml --cfg ../../yolov5-6.1/models/ljxs.yaml --weights weights/yolov5s.pt --device '0'
如果出现无法wandb可视化毕业设计记录-yolov5的wandb报错,原因和解决方法(非屏蔽wandb)_芃芃です的博客-CSDN博客
Weights & Biases

GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite

五、开始测试
测试pen
估计使用的数据量太小导致精度太低,小白一个刚开始学习没几天欢迎大佬提点一二