python金融分析小知识(32)——机器学习之KNN回归算法的使用
Hello 大家好,我是一名新来的金融领域打工人,日常分享一些python知识,都是自己在学习生活中遇到的一些问题,分享给大家,希望对大家有一定的帮助!
在上一篇文章中我给大家介绍了KNN分类算法的使用,今天给大家讲讲KNN回归算法的使用,这里我们使用的数据集是波士顿房价数据集,该数据集有506个样本,每个样本有13个特征,以及对应的价格,我们可以用这个数据集在进行房价的预测。
1.导入数据集
from sklearn.datasets import load_boston
from sklearn.neighbors import KNeighborsRegressor
boston = load_boston()
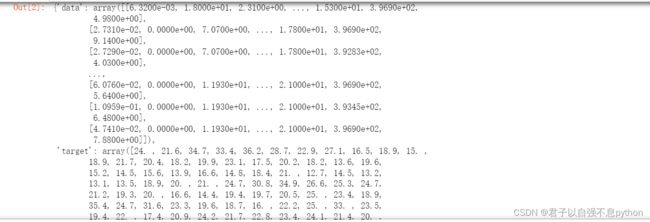
boston #回归任务我们使用波士顿房价数据集波士顿房价数据集如下:
#将数据的特征与标签分别赋值给X,y
X, y = boston.data, boston.target
X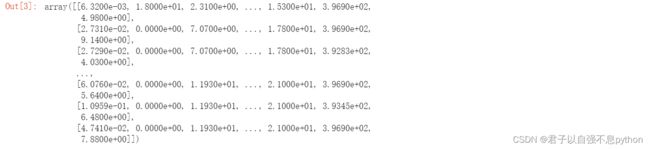
查看一下标签:

# 拆分数据集(训练集+测试集)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y) #拆分的比例用默认的# 创建KNN回归器 参数保持默认 默认为5个邻居
knn_reg = KNeighborsRegressor()
# 训练模型
knn_reg.fit(X_train, y_train)
我们来查看一下模型的准确率:
# 查看模型在训练集的准确率
print(knn_reg.score(X_train, y_train))
# 查看模型在测试集的准确率
print(knn_reg.score(X_test, y_test))
感觉回归模型的准确率不是很高呀。。
2.网格搜索
接下来我们和KNN分类模型一样使用网格搜索来进行回归模型最优参数的寻找:
# 下面使用网格搜索进行参数分析(邻居的数量参数的分析)
from sklearn.model_selection import GridSearchCV
n_neighbors = list(range(1,21,1)) #指定参数的值
cv_reg = GridSearchCV(estimator=KNeighborsRegressor(), param_grid={'n_neighbors':n_neighbors}, cv=5) #进行五折交叉验证
cv_reg.fit(X,y) #使用网格搜索拟合数据集
cv_reg.best_params_ #查看最优的参数![]() 也就是说最有的邻居数是10个。
也就是说最有的邻居数是10个。
下面我们使用最优参数来训练模型:
# 创建KNN回归器 参数保持默认 采用最佳参数
knn_reg2 = KNeighborsRegressor(n_neighbors=10)
# 训练模型
knn_reg2.fit(X_train, y_train) 看看准确率:
看看准确率:

这里我们可以看出使用最优参数的模型的准确率还没有默认参数的模型高!
注意:在使用网格搜索时,我们没有手动将数据集拆分为训练集和测试集,这是因为网格搜索内置了交叉验证(cross validation)法。我们在网格搜索时将参数cv设置为5,也就是说交叉验证会将数据分为5份,1份作为测试集,其余4份作为训练集,而后又将第二份作为测试集,其余作为训练集,以此类推,直到全部验证完毕,因此不用我们手动拆分数据集。
3.模型评估方法
通过我的上一篇讲KNN分类模型的文章还有本篇KNN回归模型的文章我们可以发现,对于分类模型还是回归模型我们都使用了.score()方法来评估模型的性能。但是在两类模型中该方法所进行的计算是不一样的。在分类模型中该方法返回的是模型预测的准确率(accuracy),计算公式如下:
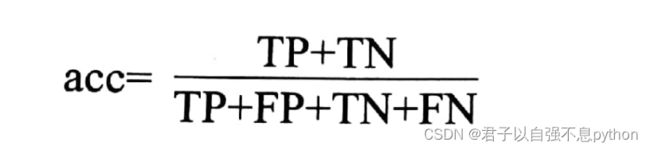
这个公式和混淆矩阵有关,有空的话后面我会讲讲,TP(True Positive)表示模型预测正确的正样本数量、FP(False Positive)表示模型预测正确的负样本数量,FP(False Positive)表示原本是负样本,却被模型预测为正样本的数量,FN(False Negative)表示原本是正样本,却被预测为负样本的数量。
在回归任务中,.score()方法返回的是模型的R^2,R^2是描述模型预测数值与真实值的差距的指标。计算公式如下:
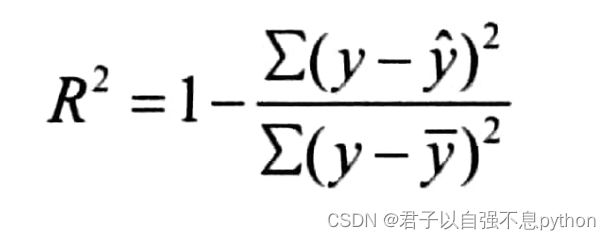
这个公式中小三角y代表模型对于样本的估计值,小横线y代表样本真实值的均值。也就是说R^2是样本真实值减去模型估计值,再进行平方求和,除以样本真实值减去样本平均值的平方和,最后用1减去这个结果。R^2取值为0-1,并且越接近1,说明模型的性能越好。
好啦,今天就分享到这里!