Temporal Segment Networks for Action Recognition in Videos 用于动作识别的时序分割网络
Temporal Segment Networks for Action Recognition in Videos 用于动作识别的时序分割网络
本文原创,欢迎转载 https://blog.csdn.net/Vincent_zbt/article/details/83062094
这篇博客主要记录对这篇论文的阅读和一些理解,算是一个整理吧,把关键问题找出来,方便学习文章,文章是在2016年曾经被发表过,在2018年的时候入选了TPAMI 2018,
文章地址为 https://arxiv.org/pdf/1705.02953.pdf
文章源码可以在github上找到:https://github.com/yjxiong/temporal-segment-networks
文章主要解决问题目标和贡献:
1、如何有效的捕获long-range时序结构来学习视频表示(文章提出TSN)
2、如何利用学习到的CNN模型再未经过修剪的视频上识别动作(文章提出M-TWI)
3、如何通过有限的样本学习CNN模型并且将其运用到更大的数据上。
TSN框架工作原理
1、首先将一段长序列分成固定数量的短序列,并且再短序列中随机采样一个片段snippet
2、利用分段一致性函数来聚合来自采样片段的信息(通过这种方式,TSN网络可以建模整个视频的long-range结构,起计算成本与视频持续时间无关)
文章研究提出了5种分段一致性聚合函数,三种基本形式:average-pooling, max pooling,weighted average,两种高级方案:top-k pooling 和adaptive attention weighting。
为了将学习到的TSN用于未经修剪过的视频,提出了分层聚合策略Multi-scale Temporal Window Intergration(M-TWI)
延续TSN的思想,该策略的原理为:首先将未修剪的视频分成一系列具有固定持续时间的短窗口,然后,对每个窗口进行独立的动作识别,对这些片段级的动作识别分数用max pooling操作 ,最后根据TSN网络框架的聚合功能,采用top-k或者adaptive attention weighting来聚合这些窗口的预测,从而产生视频级的预测结果。由于该聚合模块具有隐式地选择具有区分动作实例的区间,同时抑制噪声背景干扰的能力,所以对于非约束视频识别是有效的。
文章在四个数据集HMDB51, UCF101, THUMOS, and ActivityNet上验证文章提出的方法。另外通过引入最新的深层模型架构ResNet和InceptionV3,以及将音频作为互补信道,进一步改进了动作识别方法。
架构与公式
对于给定的视屏V,将其划分为等持续时间的K个部分{S1,S2,S3,…,Sk},一个片段Tk是从对应的Sk种随机采样得到的。对于一系列的片段(T1,T2,T3…,Tk),TSN网络对其渐离如下模型(不好编辑,还是看文章吧):
TSN(T1,T2,T3,…,Tk)=H(g(F(T1,W),F(T2,W), …,F(Tk,W),)),
其中F(Tj,W)是用参数W表示的卷积网络的函数,这个函数作用于片段Tk,产生可能属于某一类的的所有分类分数,这将得到一个向量(第 i 维的值表示,在 Tj 片段下,判断为第 i 类的概率分数)。
分段一致性函数g()对所有片段的分类输出进行组合,以得到其中类假设的一致性,g() 同样得到一个向量(第 i 维表示这个视频被分为第 i 类的概率分数)。根据这个一致性,预测函数H()对整个视频进行分类。H()一般采用Softmax
在时段网络框架中,一致性函数G的形式非常重要,因为它应该具有高的建模能力,同时仍然可以微分或至少具有次梯度。高建模能力是指能够有效地将片段级别的预测聚合到视频级别的分数,而可微性允许使用反向传播来容易地优化时间段网络框架。

如图所示:一个视频被分成了3段,从每一段中随机选取一个片段进行卷积,可以用RGB,光流等特征表示这个片段。三个片段的评分经过分段一致性函数结合,得到视频级分类结果预测。
原理如下:将分段一致性函数G=g(F(T1,W),F(T2,W), …,F(Tk,W)) 和标准交叉熵损失函数结合在一起,得到如下损失函数
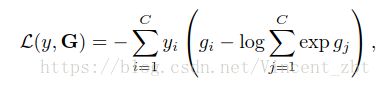
其中C是分类数,yi是类别 i 的groundtruth标签(yi是一个向量),gj是G的第 j 维(对应于G中被分为第 j 类的实际输出结果, gi 是G中被分类为第 i 类的实际输出结果)权重W可以通过如下公式计算:

其中k 表示一段视频被划分为 k 段相同长度的小段,利用SGD来优化时,文章说充分利用了每个部分学习到一致性函数G,所以能够利用整个是视频来学习参数,并且由于是分段之后随机采样,还大大减少了网络的计算量。
**
聚集函数和分析
**
文章提出了聚合函数的类型:最大池、平均池、top-k池、加权平均和注意加权。即g()函数的表现方式
Max pooling:即 g()采用max pooling来得到最后的视频级分类结果,对于被划分为k 个片段的视频,会得到k个片段级的分类结果向量F=F(), 对于g()中的 gi ,gi的取值就是这k个向量中第 i 类结果最大的值。gi = maxk∈{1,2,··· ,K} fik, 其中 fik是 Fk = F(Tk; W)的一维.
导数可表达为

max pooling的基本思想是为每个动作类寻找单个的、最有区别的片段,并利用这个最强的激活作为该类别的视频级响应。直观地说,它把重点放在单个段上,而完全忽略其他段的响应。因此,该聚合函数鼓励时态段网络从每个动作类的最有区别的片段中学习,但是缺乏对视频级动作理解的多个片段的联合建模的能力。
Average pooling:同样是对片段级分类结果的处理,gi 的取值不在是所有分为 第 i 类结果中最好的那个,而是对所有结果求平均。gi = 1/k* SUM(fik)k∈{1,2,··· ,K}.平均池是利用所有片段的响应进行动作识别,并将其平均激活用作视频级别预测。从这个意义上说,平均池能够联合建模多个片段,并从整个视频捕获视觉信息。另一方面,特别是对于具有复杂背景的嘈杂视频,一些片段可能与动作无关,对这些背景片段进行平均可能损害最终的v识别性能。
Top-K pooling:文章自己设计的方法,即选取一些最具区分性的片段的分类结果,将这些结果求平均,最为gi 的值, max 和 average相当于它的特殊情况。![]() ,αk是选择标识,选中为1,否则为0.直观地说,该聚合函数能够自适应地为不同的视频确定区分片段的子集。结果,它共享了最大池和平均池的优点,具有联合建模多个相关段的能力,同时避免了背景段的干扰。
,αk是选择标识,选中为1,否则为0.直观地说,该聚合函数能够自适应地为不同的视频确定区分片段的子集。结果,它共享了最大池和平均池的优点,具有联合建模多个相关段的能力,同时避免了背景段的干扰。
Linear weighting:为每个片段级的识别结果分配权重,加权求和得到 gi 的值![]() ,模型计算参数公式如下:
,模型计算参数公式如下: 文章称,在实际应用中,利用该方程对网络权值W和组合权值ω进行交替更新。这个聚合函数的基本假设是动作可以被分解成几个阶段,这些不同的阶段在识别动作类中可能扮演不同的角色。期望该聚合函数学习动作类的不同阶段的重要权重。与以前的基于汇集的聚合函数相比,这种线性加权充当片段选择的软版本。
文章称,在实际应用中,利用该方程对网络权值W和组合权值ω进行交替更新。这个聚合函数的基本假设是动作可以被分解成几个阶段,这些不同的阶段在识别动作类中可能扮演不同的角色。期望该聚合函数学习动作类的不同阶段的重要权重。与以前的基于汇集的聚合函数相比,这种线性加权充当片段选择的软版本。
Attention weighting:类似于线性加权,这里的权重是一个函数,对于每一个片段,根据视频内容,自适应的得到一个权值,![]() ,其中A(Tk)就是对于片段Tk的权重。该模型下的参数表达为:
,其中A(Tk)就是对于片段Tk的权重。该模型下的参数表达为:

在这个方案中,主要是函数A()怎么得到,文章给出了如下方法:首先对每一个片段,经过同样的卷积网络得到视觉特征R=R(Tk),然后通过如下计算方式得到权重:

其中ωatt是注意力加权函数的参数,它将会和网络权重W一起学习(训练的时候吧)。这里的R(Tk)是第k个片段的视觉特征。
对于参数ωatt的变化率可以表示为

其中 可以这样表示。
可以这样表示。
根据这个公式就可以在ωatt 神经网络中和W一起学习得到。由于A()函数的引入,最初的BP公式变为
 。总的来说,引入注意模型A(Tk)的优势来自两个方面:(1)注意模型通过基于视频内容自动估计每个片段的重要度权重,增强了我们的时段网络框架的建模能力。(2)由于注意模型是基于ConvNet表示R()的,它利用了额外的反向传播信息来指导ConvNet参数W的学习过程,可以加速训练的收敛。
。总的来说,引入注意模型A(Tk)的优势来自两个方面:(1)注意模型通过基于视频内容自动估计每个片段的重要度权重,增强了我们的时段网络框架的建模能力。(2)由于注意模型是基于ConvNet表示R()的,它利用了额外的反向传播信息来指导ConvNet参数W的学习过程,可以加速训练的收敛。
TSN结构框架
网络结构选择的是具有批量规范化(initionv2)[59]的Inception体系结构,因为它在准确性和效率之间具有良好的平衡,在ActivtyNet挑战2016中,作者研究了更强大的体系结构,包括Inception V3[30]和ResNet-152[29],以充分释放TSN框架在视频分类中的潜力
TSN输入
与静态图像不同,视频的附加时间维度为动作理解提供了另一个重要线索,即运动。在这项工作中,文章扩展了这两个方面,即精度和速度。如图2所示,除了RGB和光流的原始输入模式之外,还研究了另外两种模式:扭曲光流和RGB差异。

1)扭曲的光流。受改进稠密轨迹工作的启发,文章研究了用翘扭曲光流域作为运动建模源。扭曲光流域是已知的鲁棒性相机运动,并有助于集中在人体运动。文章希望这有助于提高运动感知的准确性,从而提高动作识别性能。
2)RGB差异。尽管具有优越的识别精度,但阻碍基于双流的方法应用的一个问题是光流提取的巨大时间成本。为了解决这一问题,文章构建了一个没有光学光的运动表示。受运动建模中帧体积和运动向量的成功的启发,重新审视了表观运动感知的最简单线索:连续帧之间RGB像素强度的叠加差异。回顾文献_60_中关于稠密光流的奠基性工作,像素强度相对于时间的偏导数在计算光流中起到关键作用。可以合理地假设,光流在表示运动方面的能力可以从RGB差异的简单线索中学习。这促使我们使用RGB差异作为时间流的输入,从而大大节省了光流提取的时间。
**
TSN训练
**
如前面所讨论的,现有的用于动作识别的人类注释数据集在大小方面是有限的。在实践中,在这些数据集上训练深对流网络容易出现过度现象。为了缓解这一问题,文章设计了几种策略来改进时时序络框架中的训练。
1)跨模态初始化。
当目标数据集没有足够的训练样本时,对大规模图像识别数据集(如ImageNet[18])的网络参数进行预训练已被证明是一种有效的补救方法。由于空间网络将RGB图像作为输入,所以很自然地利用在IMANET上训练的模型作为初始化。对于其它输入方式,如光路和RGB差异,文章提出了一种跨模态初始化策略。特别地,用线性变换将光流域离散到0到255的区间内。然后,在第一层对RGB通道上的预训练RGB模型的权重进行平均,并根据时序网络输入的通道数来复制平均。最后,将时间网络的剩余层的权重直接从预训练的RGB网络中复制。
2)正则化。
在用预训练模型初始化后,选择冻结除了第一层之外的所有批量标准化层的均值和方差参数。由于光流分布与RGB图像不同,卷积层的激活值会呈现出明显的分布,因此需要重新估计其均值和方差。文章称这个策略为 部分标准化。同时,为了进一步降低过拟合的影响,文章在全局汇聚层之后增加一个高dropout率的额外漏失层(实验设定为0.8)。
3)数据增强。在原来的两个流道(1)中,采用随机裁剪和水平迭代来增加训练样本。文章利用两个新的数据增强技术:角裁剪和规模抖动。在角点裁剪技术中,所提取的区域仅从图像的角点或中心选择,以避免隐式地更多地聚焦在中心区域。在多尺度裁剪技术中,将图像网分类中使用的尺度抖动技术[8]应用于动作识别。提出了一种有效的尺度抖动实现方法。将输入大小设为256×340,从{256,224,192,168}中随机选择裁剪区域的宽度和高度。最后,将这些裁剪区域调整为224×224,用于网络训练。事实上,这种实现不仅包含规模抖动,而且牵涉到纵横比抖动。
动作识别
识别未修剪的视频,即动作可能发生在视频中的任何位置,持续的时间长短不确定。
为了应对这些挑战,文章开发了一种基于检测的方法来应用动作模型到未修剪的视频。首先,为了覆盖动作实例可以驻留的任何位置,以固定的采样率(例如,1FPS)从输入视频中采样片段。然后在这些采样片段上评估训练的TSN模型。然后,为了覆盖动作剪辑的高度变化的持续时间,在帧分数上应用一系列具有不同大小的时间滑动窗口。窗口内的类的最大分数用来表示它。为了减轻背景内容的干扰,使用top-K池方案对具有相同长度的窗口进行聚合。聚合结果来自不同窗口大小,然后投票表决整个视频的预测。
形式上,对于m秒长度的视频,将获得m个片段{t1,.…,TM}。应用TSN模型,将获得片段分数TM的类分数F(TM)。然后,建立时序滑动窗口的大小 L ={ 1, 2, 4,8, 16 }。视窗会以0.8×l 的步幅滑过整个视频时间。对于从第s秒开始的视窗位置,一系列的片段将被覆盖为{Ts+1,.…,Ts+L},其类得分{f(Ts + 1),。…F(Ts+L)}。这个窗口 Fs,l 的类分数可以通过以下来计算:
![]()
这样,将得到Nl个大小为L的窗口,Nl=⌊M/0.8l ⌋. 然后运用top-k 方法得到 这Nl 个大小为l的窗口的一致性结果 Gl(即函数g()的结果).其中参数k=max(15, ⌈Nl/4⌉).对应于设置的5种窗口大小(即L ={ 1, 2, 4,8, 16 } )。
最后的分数计算为P = 1/5 *SUM(Gl),l∈{1,2,4,8,16} ,为5个尺寸窗口分数的平均值。这就是 前面提到的M-TWI.
实验部分
1)修剪过的视频数据集。
文章在剪裁视频的两个标准动作识别数据集上进行了实验,即HMGB51〔28〕和UCF101〔27〕。UCF101数据集包含101个动作类和13, 320个视频剪辑。我们遵循TROMPOS13挑战(61)的评估方案,并采用三个训练/测试分叉进行评估。HMGB51数据集是来自各种来源的真实视频的大量集合,例如电影和网络视频。该数据集由51个动作类别的6, 766个视频剪辑组成。我们的实验遵循原始的评估方案,使用三个训练/测试分割,并报告这些分割的平均精度。
2)未修剪过的视频数据集
文章在两个公开可用的大规模数据集上进行未修剪的视频动作识别实验。第一个是THUMOS14。它有101类人类行为。该数据集由训练集、验证集、测试集和背景集组成。使用训练集(UCF101)和验证集(1,010个视频)进行TSN训练,并在其测试集(1,575个视频)上评估学习模型。未修剪视频的第二个数据集是ActuviyNet [ 26 ]数据集。使用它的发布版本1.2,称为AcvivyNETV1.2。ActuviyNet V1.2数据集有100类人类活动。它包括4, 819个视频培训,2, 383个视频验证,和2, 480个视频测试。遵循标准分裂来训练和评估TSN框架。在未裁剪视频的两个数据集上,评价度量是用于动作识别的平均平均精度(MAP)。
实现细节
使用小批量随机梯度下降法学习网络参数,批量大小batch size 为128 ,动量设为0.9.采用ImageNet的与训练模型初始化网络权值。并且设置了较小的学习率。在数据集UCF101上空间网络的学习率初始化为0.001,每迭代1500次变为原来的1/10. 时序网络的初始学习率为0.005,在12000和18000次迭代后,将为原来的1/10. 最大迭代次数设置为20000.为了加快训练速度,采用多GPU数据并行策略。继承于作者修改过的Caffe和OpenMPI。在8个 TITANX GPU下,整个在该数据集上的训练时间,空间TSNs花费0.6小时,时序TSNs花费8小时。在ActivityNet等其他数据集上的过程和这个类似,但是迭代次数根据数据大小进行了调整。 考虑数据增强,文章采用了位置抖动技术。为了提取光流和扭曲光流,文章选择了继承于带CUDA的Opencv的TVL1光流算法。
文章比较了表格中的集中训练策略,选择了表现最好的带丢弃率的部分标准化策略(+ Partial BN with dropout )

对于输入模态,仍然是双流组合,文章组合比较了不同的组合得到的识别精度和速度,如下表所示
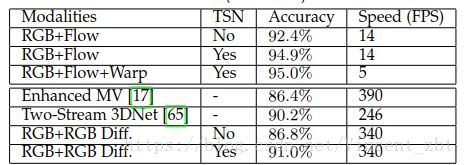
文章提出了两种新的模态叫RGB差异和扭曲光流,在这里也被组合用来实验了,表中可以看到,RGB+Flow + Warp得到了最好的精度,但是却也是最慢的速度。文章发现RGB+RGB Diff能够得到不错的精度以及非常好的速度。因此用这个组合和其他现有方法进行了比较。结果显示TSN确实有提升效果,并且速度同样很快。
文章为了验证TSN的有效性,在UCF101 和ActivityNet数据集上评估了TSN中提出的关键的两个组件:稀疏片段采样策略和分段一致性函数。在这个过程中,采用的是RGB图像和光流域作为输入。
视频分段数K的设置
在稀疏片段采样策略中,最重要的是对视频分段的K数,如何分段数k=1,则TSN就变成了基本的双流卷积网络。 文章中分别对k从1到9进行了取值,结果显示当k的数越大时,性能越好,但是大于7时,性能饱和,因此文章最后选择k=7。

评估聚合函数
在文章中提到了5中聚合函数,在裁剪过的数据集UCF101上,平均函数显示出了最好的性能,而权重平均和注意力加权获得了差不多的性能。但在更为复杂的数据集ActivityNet上,top-k和注意力加权函数取得了相似的优良性能。因此文章认为,对于越复杂和时间结构多样化的视频,更加高级的聚合函数将会得到更加好的识别精度。在以后的实验中,文章默认对短视频(HMDB51和UCF101)进行平均池,对复杂视频(ActivityNet)进行top-K池。

确定网络结构选择
文章将k设置为1,在四个比较典型的结构网络BN-Inception、GoogLeNet、VGGNet-16和ResNet-152上比较了这些结构的性能,结果显示BN-Inception的性能最好,因此文章在该结构框架之上运用了提出的TSN,如表结果显示出性能得到很大提升。

比较提出的动作识别方法
文章在四个数据集上和其他方法进行了比较,为了公平起见,文章采用的是和其他文章一样的RGB+光流两种模态作为输入。
文章将数据集分为了剪裁过的和未剪裁的数据集,结果展示在下表中,由前面提到的,文章在修剪过的数据集上采用的分段一致性聚合函数是平均值函数,这里在为修剪的数据集上采用的是top-k函数。需要提一下的是,文章在对空间流和时间流进行融合的时候,在修剪过的数据及上采用的是1:1的权重,而对于未修剪的数据集识别,采用的是1:0.5.
