技术原理|Hologres Binlog技术原理揭秘
作者:张高迪(花名杳天),Hologres研发。
同传统MySQL数据库,Hologres支持Hologres binlog,记录数据库中所有数据的变化事件日志。通过Hologres binlog,可以非常方便灵活的实现数据之间的复制、同步。同时在大数据场景上,支持Flink直接消费Hologres Binlog,相较于传统数仓分层,Flink+Hologres Binlog可以实现完整的事件驱动,完成ODS向DWD,DWD向DWS等的全实时加工作业,满足分层治理的前提下统一存储,提升数据复用能力,并且大大缩短数据加工端到端延迟,为用户提供一站式的实时数据仓库解决方案。在本文中,我们将会介绍Hologres Binlog技术实现原理以及使用最佳实践。
Hologres Binlog介绍
1、什么是Binlog?
Binlog即二进制日志(Binary Log),这个概念常见于MySQL数据库,是用来记录数据库所有可能引起数据变化事件的日志,比如表结构变更(例如CREATE、ALTER TABLE…)以及表数据修改(INSERT、UPDATE、DELETE…)事件。
MySQL Binlog最初有两个主要用途:
- 主从复制:主服务器将其Binlog文件中包含的事件发送到从服务器,从服务器执行这些事件以进行与主服务器相同的数据更改,从而保证主从服务器之间的数据一致性。
- 数据恢复:通过重新执行Binlog文件中记录的事件,使数据库恢复到发生问题之前最新的状态。
Binlog也被用作流式的数据源。用户常常通过Debezium或者阿里开源的 Canal等数据采集工具,采集Binlog作为流式的数据源,从而实现数据从MySQL到其他类型数据库的数据同步,一般先将采集的数据输出到消息中间件如Kafka等,然后通过Flink引擎去消费数据并进行相应计算,最终写入到目的端。目的端可以是各种 DB,数据湖,实时数仓和离线数仓等。
2、Hologres Binlog与传统数据库Binlog的区别
Hologres Binlog与传统数据库Binlog的主要区别在于,前者一般只用于数据同步,而后者还应用于主从实例同步和数据恢复等高可用场景。因此两者的实现也有了一定的差别,主要体现在以下方面:
Hologres的高可用通过基于WAL log复制实现的物理Replication来保证,详见技术揭秘:从双11看实时数仓Hologres高可用设计与实践。
- Hologres Binlog不会记录DDL操作。
Hologres的Binlog主要面向数据消费,不支持记录表结构变更(如CREATE TABLE、ALTER TABLE 等DDL)操作,只记录数据变更记录(INSERT、UPDATE、DELETE),记录方式类似MySQL Binlog的 ROW(row-based replication)模式,会完整的记录每行数据的变更情况。
- Hologres Binlog较为灵活,是表级别的,可以按需打开和关闭,且可以为不同的表设置不同的TTL。
MySQL 开启Binlog是实例级别的,一般会占用比较多的存储,并且打开Binlog往往需要重启集群;而Hologres 的Binlog更加细粒度,可以在使用中按需对某张表进行开启和关闭,并为不同的表设置不同的Binlog存活时间,完全不影响实例中的其他数据库和数据表,打开Binlog只会多出一份表级别的存储。
- Hologres Binlog可以非常方便的进行查询。
在使用中,用户可以通过在query中添加 hg_binlog_lsn,hg_binlog_event_type,hg_binlog_timetsamp_us 这三个字段来查询表的Binlog。如果查询的字段包含了上述三个字段之一,如select hg_binlog_lsn, * from test_message_src;便会自动路由到Binlog表进行查询。相对而言,用户在MySQL想要查看Binlog则不够直观,需要通过show binlog events命令或者MySQL Binlog工具去解析Binlog文件。需要注意的是,Hologres Binlog底层采用行存表存储,因此在查询时,推荐过滤条件中包含hg_binlog_lsn字段来保证查询效率,按照其他业务字段查询会演变为全表扫描,表数据量大时查询会比较慢,应该尽量避免。
- Hologres作为分布式的实时数仓,Binlog同样也是分布式的。
Hologres Binlog与普通的Hologres表数据一样,分布在不同的shard上,读取Binlog等操作也以shard分片,类似kafka的partition,详细可以看下方的实现原理。
总的来说,Hologres Binlog可以简单的定义为:可以按需开关的,以行为单位记录Hologres某张表数据变更记录(INSERT、UPDATE、DELETE)的二进制日志。可以看到,Hologres Binlog自设计起便是为实时消费和用户使用而生的,相比MySQL Binlog拥有的历史包袱,更加易用和灵活。
3、Hologres Binlog格式
Hologres 的Binlog包含如下字段。

字段说明:

说明:
- UPDATE操作会产生两条Binlog记录,分别为更新前和更新后的记录。订阅Binlog功能会保证这两条记录是连续的且更新前的Binlog记录在前,更新后的Binlog记录在后。
- 用户字段的顺序与DDL定义的顺序一致。
Hologres Binlog使用场景
1、数据实时复制、同步
Hologres通过Binlog实现了逻辑Replication,从而可以订阅Binlog进行数据的复制和同步。

典型的逻辑复制使用场景有:
1、把一张Hologres的行存表复制成一张列存表,行存支持点查点写,列存支持多维分析型需求。
比如在阿里CCO的使用场景中,写入Hologres行存表的数据,会通过Hologres Connector Binlog订阅,将公共层明细数据有选择的进行二次计算,并写入回Hologres列存应用层明细表中,提供给不同的应用层分析和汇总场景。Hologres 1.1版本开始支持了同一张表行列共存的模式,需要通过Binlog手动完成行存转列存的场景更少了。
2、局部更新之后通过Binlog驱动整行计算
一些场景中,DWD层的数据更新之后,用户下游的计算逻辑需要完整的表字段,但传统数据仓库可能支持的不够完善。比如阿里CCO在之前的架构中使用Lindorm,想要拿到完整的表字段,就需要通过Hlog订阅,触发流任务反查事实表,将宽表字段对齐之后再输出到下游。而Hologres的Binlog,即使只更新部分字段,也会生成一条包含整行数据的Binlog。根据这种特性,局部更新也可以驱动整行数据的计算,无需反查便可以供应用层消费。

3、实时数据打宽。
在某些场景下,用户数据被分隔成面向主题、维度的多张表,而最终分析时需要将不同的表进行关联,便可以通过Hologres Binlog作为驱动进行双流join、维表关联等操作进行实时数据打宽,进而使用大宽表进行数据分析。
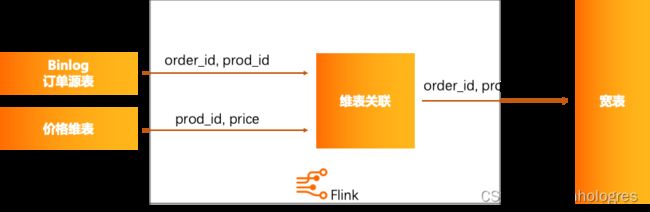
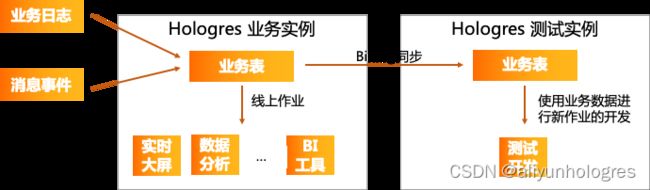
4、用于Hologres不同版本或不同实例之间的数据迁移。
在开发中,很多用户都会有测试实例和业务实例,这个时候通过Binlog将部分业务数据实时的同步到测试实例进行新业务的开发就非常方便;有些用户在跨大版本升级时,也可以通过Binlog逻辑复制在高版本实例进行完整的业务流程验证,保证实例升级版本之后稳定可用。
2、实时数仓分层
Hologres Binlog结合Flink CDC,可以实现事件驱动的加工开发,完成ODS向DWD,DWD向DWS等的全实时加工作业。满足分层治理的前提下统一存储,并且大大缩短数据加工端到端延迟,为用户提供一站式的实时数据仓库解决方案。
以下是传统的数仓分层架构。
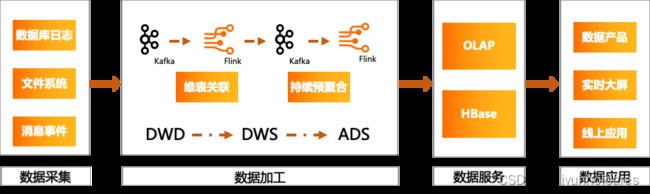
传统数仓分层架构通过Kafka驱动Flink,Flink 在计算过程中查询一些KeyValue 系统(如HBase)做一些维表的关联,实现数据的拉宽。拉宽之后还会把这个结果重新写到 Kafka 另外一个 Topic 里面,然后做二次的聚合、汇总,生成一些DWS 或者ADS,最后把结果存在 OLAP/HBase 系统。其中结果之所以需要存在KV和数仓两种系统中,是因为查询和分析业务的需求不同,一份数据可能需要存在多处,所以传统数仓分层架构经常会存在一定的数据冗余。
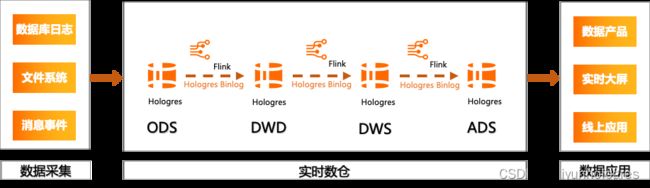
上图是使用Flink结合Hologres实现的分析服务一体化的实时数仓架构。 此架构不仅实现了分析服务的融合,减少了数据的割裂,而且精简了数据加工链路,通过Hologres Binlog来实现事件驱动,替换各个阶段的消息队列服务(Kafka)。可以看到,分析服务一体化的数仓分层架构,不但可以有效的降低成本,而且简化了业务逻辑,从而大大提高开发效率,降低运维成本。
3、数据变化监控
在数据库使用尤其在新业务的开发中,可能会有想要知道数据变更情况的场景,判断自身的业务逻辑是否准确,这种情况下也可以通过打开Binlog来方便的进行数据变化监控。
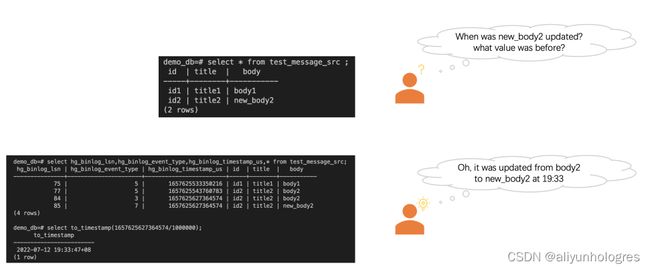
Hologres Binlog实现原理
1、Binlog表
需要提前了解的知识是,Hologres表存储结构主要分为行存和列存以及1.1版本引入的行列共存。列存表适用于OLAP场景,适合各种复杂查询、数据关联、扫描、过滤和统计;行存表适用于 KV(key-value)场景 ,适合基于primary key的点查和扫描;行列共存则可以看作同时创建了一张行存表和一张列存表,holo会保证数据的一致性,从而达到既支持高效点查也支持OLAP分析的效果。
Binlog表可以看作一张特殊的行存表
下面以一个行存表为例,讲述Binlog的实现原理。
一个普通的行存表如下,可以看到是KV形式的, key 为表的主键,value 为表的其他字段。
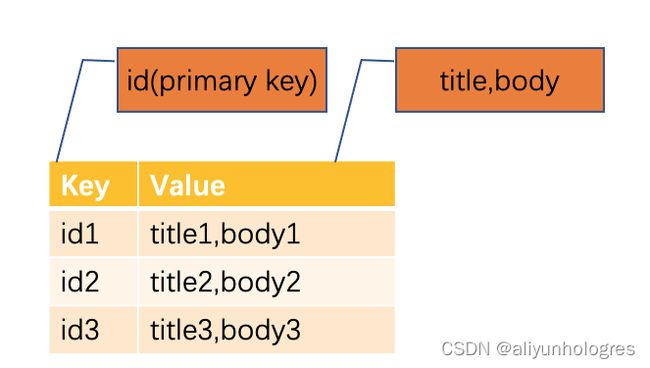
为某张表打开Binlog,可以理解为是新创建了一张以hg_binlog_lsn为key, 业务表原有字段、hg_binlog_event_type以及hg_binlog_timestamp_us字段则组合起来作为value的行存表, 可以看到Binlog表的字段是固定的,也可以说是强Schema的,顺序与业务表DDL定义的顺序一致。
下图是一张打开Binlog的行存表,注意不是在原有表的基础上加列,而是新建了一张内部特殊表(在holo中表现为原表的一个特殊index,所以对原表和Binlog表进行写入等操作都是原子的),两者同时存在。因此开启Binlog会占用更多的存储空间。

Binlog如何保证正确性
在首次揭秘云原生Hologres存储引擎一文中,介绍了Hologres的存储引擎,这里简单复习一下存储引擎架构以及单分片写入的过程。
- 存储引擎架构
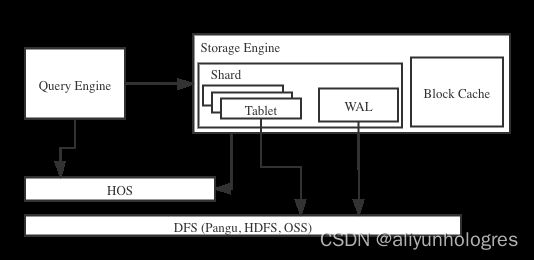
Hologres存储引擎的基本抽象是分布式的表,为了让系统可扩展,我们把表切分为分片(Table Group Shard,简称Shard)。每个分片(Shard)构成了一个存储管理和恢复的单元 (Recovery Unit)。上图显示了一个分片的基本架构。一个分片由多个tablet组成,这些tablet会共享一个预写式日志(Write-Ahead Log,WAL)。
Hologres存储引擎用WAL来保证数据的原子性和持久性。当INSERT、UPDATE、DELETE操作发生时,存储引擎先写WAL,再写到对应tablet的MemTable中,等到MemTable积累到一定的规模或者到了一定的时间,就会把这个MemTable切换为不可更改的flushing MemTable, 并新开一个 MemTable接收新的写入请求。 而这个不可更改的flushing MemTable就可以刷磁盘,变成不可更改的文件; 当不可更改的文件生成后,数据就可以算持久化。 当系统发生错误崩溃后,系统重启时会去WAL读日志,恢复还没有持久化的数据。
- 单分片写入

上图展示了Hologres单分片写入的过程,这里我们只关注前两个步骤:WAL管理器在接收到单分片写请求后,(1)为写请求分配一条Log Sequence Number (LSN,在holo表中可以通过隐藏字段hg_sequence_number查询),这个LSN是由时间戳和递增的序号组成,并且(2)创建一条新的日志,并在文件系统中的持久化这条日志。这条日志包含了恢复写操作所需的信息,在完全保留这条日志后,才向tablet提交写入。
- Binlog生成时间
Binlog 数据生成在写WAL之前,即上方介绍的单分片写入中的第一步。其中hg_binlog_lsn直接复用了Log Sequence Number(在Binlog表中查询hg_sequence_number和hg_binlog_lsn两个字段,可以发现这两个字段完全相同)。在生成Log Sequence Number时使用系统时间作为hg_binlog_timestamp_us。判断写入类型之后才创建WAL日志完成写入。在holo中Binlog表表现为原表的一个特殊index,原表和Binlog表数据变更是同时发生的,从而保证了binlog数据和表原始数据一定是完全一致的。
2、表Binlog的生成过程
下面分别以行存表和列存表为例,演示Binlog的生成过程。
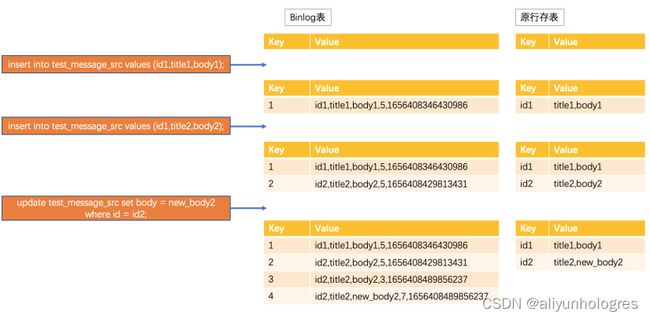
开启Binlog的行存表的变更过程
图中进行了三次操作:
- 插入主键为id1的数据,生成相应的Binlog,evnet_type为5
- 插入主键为id2的数据,生成相应的Binlog,evnet_type为5
- 更新主键为id2的数据,可以看到更新操作会生成两条Binlog, 其event_type分别为3和7,并且有相同的timestamp_us
开启Binlog的列存表的更新过程
一个普通的列存表如下,可以看到与行存表有明显区别,数据是按照列来进行存储的。
下图展示了对一个已有3条数据的行存表进行更新生成Binlog的过程,与行存表类似,更新操作会生成两条Binlog, 其event_type分别为3和7,并且有相同的timestamp_us。需要注意的是,这次的update操作只更新了body这个字段,但由于Binlog记录的是整行所有字段的数据,因此在生成Binlog的过程中,需要通过id去点查列存表这行数据各个字段的值,这并非列存表擅长的操作,相对行存表会消耗更多的资源,因此一般推荐使用行存表开启Binlog。

3、Binlog更多实现细节
- Binlog TTL
与表的TTL(time_to_live_in_seconds)不同,Binlog 有单独的ttl,可以看作是Binlog表的TTL。通过以下DDL语句为表单独设置Binlog TTL。Binlog会在生存时间到期后被清理,建议不要少于7天。
call set_table_property('test_message_src', 'binlog.ttl', '86400');--binlog.ttl,Binlog的TTL,单位为秒
- Binlog 数据分布
Binlog表的shard数与原表的shard数相同,并且也有相同的Distribution key ,就是说一条数据和其Binlog数据一定分布在同一个shard上。
- Binlog 有序性
Binlog是单shard保序,单个shard上的hg_binlog_lsn单调递增,不同shard之间的hg_binlog_lsn可能相同。除了更新操作生成的两条hg_binlog_timestamp_us完全相同外,单个shard上hg_binlog_timestamp_us也是递增的。
- Binlog的数据量和表的更新频率成正比
Hologres Binlog的最佳实践
在了解了Binlog的实现原理后,我们来看看使用Binlog的最佳实践。
1、建表并开启Binlog
推荐建表语句如下:
begin;
create table test_message_src(
id int primary key,
title text not null,
body text);
call set_table_property('test_message_src', 'orientation', 'row');--创建行存表test_message_src
call set_table_property('test_message_src', 'binlog.level', 'replica');--设置表属性开启Binlog功能
call set_table_property('test_message_src', 'binlog.ttl', '864000');--binlog.ttl,Binlog的TTL,单位为秒,这里是7天
commit;
上方的DDL中有几个需要注意的细节:
- 推荐使用行存表。相对行存表,列存表生成Binlog会消耗更多的资源,因此推荐使用行存表来开启BInlog进行使用。
- 支持按需打开。
binlog.level设置为replica即表示为此表打开Binlog,1.1版本之后无需重新建表,可以为已有表打开Binlog,对于无需打开Binlog的表,也可以通过设置此参数为none进行关闭。 - 按需设置Binlog TTL。
binlog.ttl默认值为1个月,推荐不少于7天,用户可以按照业务需求设置,合理的TTL可以有效降低存储使用量。
2、消费Hologres Binlog
目前Hologres Binlog支持两种消费方式。
1)Flink消费Hologres Binlog
实时计算Flink版有丰富的消费Hologres的Binlog的能力。以下是FLink定义Hologres Binlog源表的DDL。
create table binlog_source_table(
hg_binlog_lsn BIGINT,
hg_binlog_event_type BIGINT,
hg_binlog_timestamp_us BIGINT,
id INTEGER,
title VARCHAR,
body VARCHAR
) with (
'connector'='hologres',
'dbname'='',
'tablename'='',
'username'='',
'password'='',
'endpoint'='',
'binlog' = 'true', -- 开启binlog消费
'cdcMode' = 'true', -- cdc模式
'binlogStartUpMode' = 'initial', -- 先读取历史全量数据,再增量消费Binlog。
);
Flink消费Binog有以下特性和使用细节:
1)支持CDC模式
CDC模式下消费的Binlog数据,将根据hg_binlog_event_type自动为每行数据设置准确的Flink RowKind类型(INTERT、DELETE、UPDATE_BEFORE、UPDATE_AFTER),这样就能完成表的数据的镜像同步,类似MySQL和Postgres的CDC功能。
2)支持全增量一体化消费
全增量一体的消费会先读取数据库的历史全量数据,并平滑切换到Binlog读取增量数据。
3)推荐根据表shard数调整源表并发
Hologres的Binlog是Shard级别保序的,在使用实时计算消费Binlog时,推荐调整源表的并发数与Binlog表的Shard数相同,从而可以每个Shard对应一个并发,保证数据的有序性。
2)JDBC消费Hologres Binlog
Hologres一定程度上兼容了PostgreSQL的logical replication接口,可以通过相应接口使用JDBC消费Hologres的Binlog,玩转更多的场景。以下是一个简单的使用示例,权限以及清理创建的组件等详见JDBC消费Hologres Binlog。
使用之前的准备步骤:
- 首先准备一张打开Binlog的表,可以参考上方最佳实践。
- 打开Binlog的extension,extension是DB级别的,一个数据库只需要创建一次。
create extension hg_binlog;
- 为表创建Publication,与表是一对一的关系
create publication hg_publication_test_1 for table test_message_src;
- 创建Replication Slot并绑定到Publication上,一个publication可以绑定多个replication_slot
一个Replication Slot表示一个数据的更改流,该Replication Slot也与当前消费进度绑定,会维护Binlog消费的点位信息,使得消费端Failover之后可以从之前已经Commit的点位进行恢复,实现断点续传。
call hg_create_logical_replication_slot('replication_slot_name', 'hgoutput', 'publication_name');
使用JDBC按照以下方式消费Binlog:
// 创建PGReplicationStream并绑定至Replicaiton slot
PGReplicationStream pgReplicationStream = pgConnection.getReplicationAPI().replicationStream()
.logical()
.withSlotName("hg_replication_slot_1") //指定Replication Slot的名称
.withSlotOption("parallel_index", "0") //并发序列号,对应表的shard id
.withSlotOption("batch_size", "1024") //单次获取的Binlog最大批大小
.withSlotOption("start_time", "2021-01-01 00:00:00") //从某个时间点位开始消费
.withSlotOption("start_lsn","0") //从某个lsn之后开始消费,优先级高于start_time
.start();
// 创建holo-client
HoloConfig holoConfig = new HoloConfig();
holoConfig.setJdbcUrl(url);
holoConfig.setUsername(username);
holoConfig.setPassword(password);
HoloClient client = new HoloClient(holoConfig);
// 创建Binlog decoder用于Decode binary数据,schema需要通过HoloClient获取
TableSchema schema = client.getTableSchema("test_message_src", true);
HoloBinlogDecoder decoder = new HoloBinlogDecoder(schema);
// 消费数据
ByteBuffer byteBuffer = pgReplicationStream.readPending();
while (true) {
if (byteBuffer != null) {
List records = decoder.decode(byteBuffer);
Long latestLsn = 0L;
for (BinlogRecord record : records) {
latestLsn = record.getBinlogLsn();
// Do Something
System.out.println( "lsn: " + latestLsn + ", record: " + Arrays.toString(record.getValues()));
}
// Commit Binlog 点位信息
pgReplicationStream.setFlushedLSN(LogSequenceNumber.valueOf(latestLsn));
pgReplicationStream.forceUpdateStatus();
}
byteBuffer = pgReplicationStream.readPending();
}
3)使用Holo-Client消费Binlog
Holo-Client将JDBC消费Binlog能力进行了集成,可以方便的通过指定消费开始的时间进行整表Binlog的消费,同时也支持为每个Shard单独设置启动位点,推荐使用Holo-client来消费Binlog。
建表等准备操作与JDBC消费Hologres Binlog相同,客户端消费示例如下。
import com.alibaba.hologres.client.BinlogShardGroupReader;
import com.alibaba.hologres.client.HoloConfig;
import com.alibaba.hologres.client.HoloClient;
import com.alibaba.hologres.client.model.Record;
import com.alibaba.hologres.client.model.TableSchema;
import java.util.Arrays;
public class HoloBinlogExample {
public static void main(String[] args) throws Exception {
String username = "";
String password = "";
String url = "jdbc:postgresql://ip:port/database";
String tableName = "test_message_src";
String slotName = "hg_replication_slot_1";
// 创建client的参数
HoloConfig holoConfig = new HoloConfig();
holoConfig.setJdbcUrl(url);
holoConfig.setUsername(username);
holoConfig.setPassword(password);
holoConfig.setBinlogReadBatchSize(128);
HoloClient client = new HoloClient(holoConfig);
// 消费binlog的请求,tableName和slotname为必要参数,Subscribe有StartTimeBuilder和OffsetBuilder两种,此处以前者为例
Subscribe subscribe = Subscribe.newStartTimeBuilder(tableName, slotName)
.setBinlogReadStartTime("2021-01-01 12:00:00+08")
.build();
// 创建binlog reader
BinlogShardGroupReader reader = client.binlogSubscribe(subscribe);
BinlogRecord record;
while ((record = reader.getBinlogRecord()) != null) {
//handle record
}
}
}
使用Holo Client消费Binlog时可以指定如下参数。
| 参数 | 是否必须 | 默认值 | 说明 |
|---|---|---|---|
| binlogReadBatchSize | 否 | 1024 | 从每个Shard单次获取的Binlog最大批次大小,单位为行。 |
| binlogHeartBeatIntervalMs | 否 | -1 | binlogRead 发送BinlogHeartBeatRecord的间隔。-1表示不发送。当binlog没有新数据,每间隔binlogHeartBeatIntervalMs会下发一条BinlogHeartBeatRecord,此record的。timestamp表示截止到这个时间的数据都已经消费完成。 |
| binlogIgnoreDelete | 否 | false | 是否忽略Delete类型的Binlog。 |
| binlogIgnoreBeforeUpdate | 否 | false | 是否忽略BeforeUpdate类型的Binlog。 |
| retryCount | 否 | 3 | 消费失败时的重试次数,成功消费时重试次数会被重置。 |
总结
Hologres的Binlog功能为消费而生,可以表粒度的按需开启,非常易用和灵活。Hologres Binlog结合Flink CDC,可以实现事件驱动的加工开发,完成ODS向DWD,DWD向DWS等的全实时加工作业。满足分层治理的前提下统一存储,并且大大缩短数据加工端到端延迟,降低学习成本,提升开发效率。
后续我们将会陆续推出有关Hologres的技术底层原理揭秘系列,敬请持续关注!往期精彩内容:
- 2020年VLDB的论文《 Alibaba Hologres: A cloud-Native Service for Hybrid Serving/Analytical Processing 》
- Hologres揭秘:首次揭秘云原生Hologres存储引擎
- Hologres揭秘:Hologres高效率分布式查询引擎
- Hologres揭秘:高性能原生加速MaxCompute核心原理
- Hologers揭秘:优化COPY,批量导入性能提升5倍+
- Hologres揭秘:如何支持超高QPS在线服务(点查)场景
- Hologres揭秘:从双11看实时数仓Hologres高可用设计与 实践
- Hologres揭秘:Hologres如何支持超大规模部署与运维
- Hologres揭秘:湖仓一体,Hologres加速云数据湖DLF技术原理解析
- Hologres揭秘:高性能写入与更新原理解析