Xavier初始化
文章题目:Understanding the difficulty of training deep feedforward neural networks
原文链接:
目录
- 补充几种初始化
-
- 全0初始化
- 固定值初始化
-
- BN层的初始化
- LSTM
- bias初始化
- 固定方差的初始化
-
- 高斯分布初始化
- 均匀分布初始化
- 方差缩放的参数初始化
-
- Xavier 初始化
- He初始化
- 摘要
- 深度神经网络
- 发现实验
-
- 实验设置
- 实验结果
- 理论思考
- 对比实验
- 参考文献
补充几种初始化
全0初始化
在线性回归,logistics回归的时候,基本上都是把参数初始化为0,模型也能够很好的工作。然后在神经网络中,把w初始化为0是不可以的。如果全部初始化为0,在神经网络第一遍前向传播所有隐层神经网络激活值相同,反向传播权重更新也相同,导致隐层神经元没有区分性,称为“对称权重”现象。如果所有的参数都是0,那么所有神经元的输出都将是相同的,那在back propagation的时候同一层内所有神经元的行为也是相同的 — gradient相同,weight update也相同。这显然是一个不可接受的结果。为打破这个平衡,比较好的方式是对每个参数进行随机初始化。
固定值初始化
固定值初始化适用于如下网络层:
BN层的初始化
BN层中的gamma初始化为1,beta初始化为0。
LSTM
LSTM遗忘门偏置通常为1或2,使时序上的梯度变大
bias初始化
对于偏置(bias)通常用0初始化对于ReLU神经元,偏置设为0.01,使得训练初期更容易激活。
固定方差的初始化
高斯分布初始化
均匀分布初始化
缺点:如何设置方差,如果太小或太大,信号经过sigmoid激活函数后会进入激活函数的饱和区,从而造成梯度消失等问题。
方差缩放的参数初始化
Xavier 初始化
也称为Glorot初始化,因为发明人为Xavier Glorot。Xavier initialization是 Glorot 等人为了解决随机初始化的问题提出来的另一种初始化方法,他们的思想就是尽可能的让输入和输出服从相同的分布,这样就能够避免后面层的激活函数的输出值趋向于0。
Xavier初始化在sigmoid和tanh激活函数上有很好的表现,但是在Relu激活函数上表现很差。
He初始化
也称为Kaiming初始化,这种初始化解决了Xavier初始化在Relu激活函数上性能差的问题,也是较为常用的初始化方法。He initialization的思想是:在ReLU网络中,假定每一层有一半的神经元被激活,另一半为0,所以,要保持variance不变,只需要在Xavier的基础上再除以2:

摘要
——介绍这篇论文的主要内容就是尝试更好的理解为什么使用“标准随机初始化”来计算使用标准梯度下降的网络效果通常来讲都不是很好。
——首先研究了不同的非线性激活函数的影响,发现 sigmoid 函数它的均值会导致在隐层中很容易到达函数的饱和区域,因此sigmoid 激活函数在随机初始化的深度网络中并不合适。但同时惊喜的发现,处于饱和的神经元能够自己“逃脱出”饱和状态。
—— 最后研究了激活值和梯度值如何在训练过程中的各层次里发生变化,其中,当与每个层相关联的雅可比矩阵的奇异值远远大于1时,训练可能会变得更加困难。基于这些考虑,提出了一种新的初始化方法,可以带来更快的收敛速度。
深度神经网络
—— 深度学习方法的目标是学习特征层次结构,其中较高层次的特征由较低层次特征组成。
——大多数具有深层结构的最新实验结果都是通过可转化为深层监督神经网络的模型获得的,但其初始化或训练方案不同于经典的前馈神经网络。为什么这些新算法比标准的随机初始化和基于梯度的有监督训练准则优化工作得更好?Erhan等人的工作表明无监督预训练初始化作为调节器,在优化程序的“更好”吸引区中初始化参数,对应于更好的通用化相关的明显局部最小值。
——本文的分析有调查性实验驱动,这些实验设计到跨层和跨训练迭代的监视器激活(观察隐藏单元的饱和)和梯度。我们还评估了激活函数(其可能影响饱和)和初始化程序(因为无监督的预训练是一种特殊的初始化形式,具有巨大的影响)的选择对这些的影响。
发现实验
实验设置
—— 无限数据集:
Shapeset-3*2:它的数据的大小是无穷多的,因为为不断地随机生成。使用的数据集中随机生成三个图形(平行四边形,椭圆,三角)中的两个,而且允许相互之间存在遮挡关系(不大于 50% 的遮挡),最后将图形全都 resize 成为 32×32 大小。
——有限数据集:
MNIST:手写数字数据集,50000张训练图片,10000张验证图片,10000张测试图片,每个图片是28*28的灰度数字图像。
CIFAR-10:是微小图像数据集的一个标记自己,包含50000个训练图像(作者从中选10000作为验证数据)和10000个测试图像。每个图像中的主要对象对应10类:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船或卡车。每张图像是彩色的,大小为32*32像素。
Small-ImageNet是一组微小37*37灰度图像数据集,有WordNet的名词结构标签。作者使用了90000个图像进行训练,10000个用于验证,10000用于测试。包含十个类:地砖、交通工具、鸟类、哺乳动物、鱼类、家具、仪器、工具、花卉和水果。
——网络的隐藏层选择1-5层,每一层的网络的神经单元数为1000个,输出层为一个softmax 逻辑回归。 代价函数为:负对数函数,即:-log P(y|x).
网络的优化方法为:梯度的反向传播算法, mini-batches的大小为10。权值更新过程中的学习率基于验证集误差来确定。
在隐含层选用分别试验三种不同的激活函数:sigmoid函数, 双曲正切函数, softsign函数,后面两个函数的是相似的,唯一的区别在于:双曲正切函数以指数型接近渐近线(速度快),softsign函数以二次型接近它的渐近线。Softsign公式为
f ( x ) = x / ( 1 + ∣ x ∣ ) f(x) = x/(1+|x|) f(x)=x/(1+∣x∣)
网络权值的确定为下面区间上的均匀分布,其中 n 为:前一层的单元数。
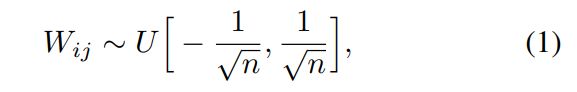
实验结果
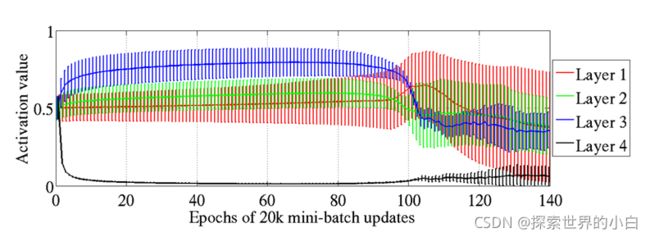
-该图显示深层结构中不同隐藏层的监督学习期间激活值(sigmoid)的平均值和标准差。
-顶部隐藏层在0处快速饱和,但在100轮左右失去饱和。
-作者发现,这种饱和在具有S型激活的深层网络中可以持续很长时间
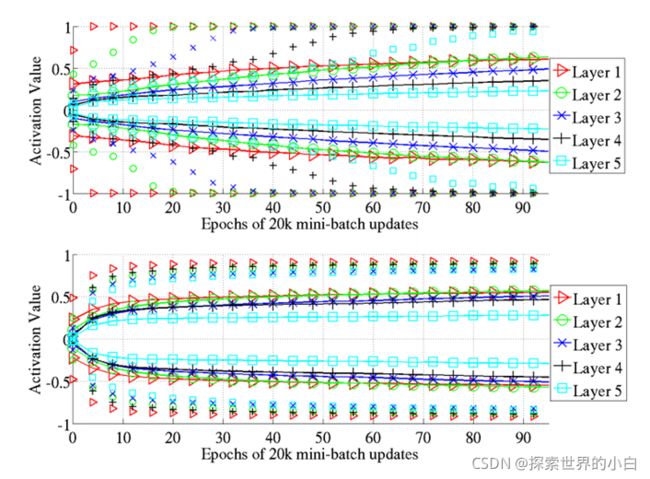
-学习过程中激活值分布的98个百分位(仅标记)和标准偏差(带标记的实现)。上图为双曲正切函数,下图为softsign。
-两图对比说明softsign激活函数的网络达到饱和比较慢,且层之间达到饱和状态没有先后差别。
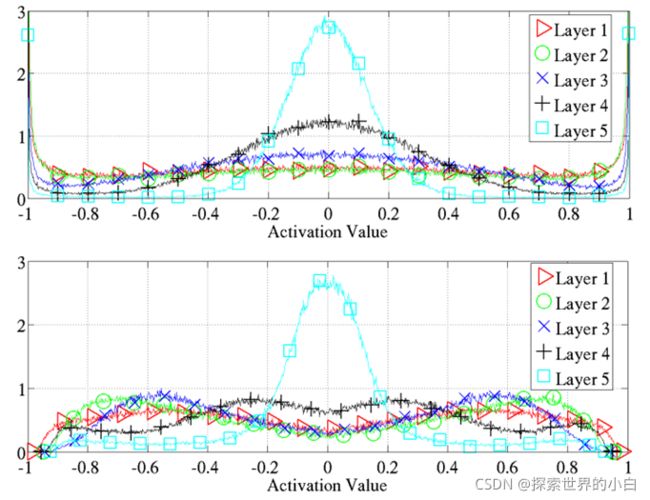
-学习结束时的激活值标准化直方图,在同一层的单元和300和测试示例中取平均值。上图是双曲正切,下图是softsign。
-上图的激活大多分布在极端(-1,1,0),而softsign在(0.6,0.8),(-0.6,-0.8)附近有激活值

-交叉熵(黑色)和二次损失(红色)一个有两个权重两层网络。
-作者发现,逻辑回归或条件对数cost函数比传统上用于训练前馈神经网络的二次cost工作得更好(对于分类问题)。
-把训练准则(criterion)画成随机输入和目标信号的两个权重的函数,从图中可看到二次cost有更多的平稳停滞状态。
理论思考
对于一个密集人工神经网络,使用对称激活函数f,且 f 满足 f ′ ( 0 ) = 1 f^{'}(0)=1 f′(0)=1是第 i i i层的激活向量, s i s^{i} si 是第 i i i层的参数向量(argument vector).有
s i = z i + w i + b i , z i + 1 = f ( s i ) s^{i} = z^{i} + w^{i} + b^{i}, z^{i+1}=f(s^{i}) si=zi+wi+bi,zi+1=f(si)
则有
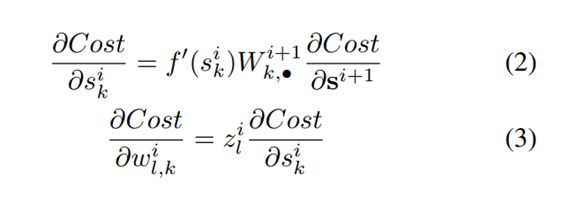
假设初始阶段处于线性状态,权重是独立初始化的,且输入向量的方法一样,则对于第 i i i层大小为 n i n_i ni, x x x为输入的网络
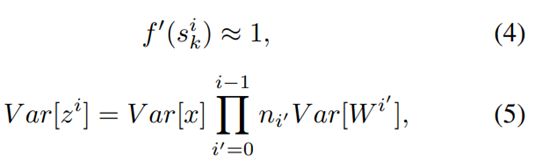
对于一个 d d d层的网络
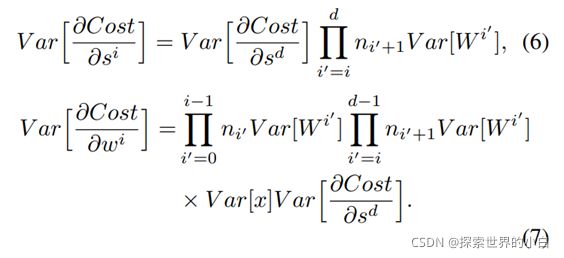
从前向传播角度,为保持信息流畅(information flowing),假设
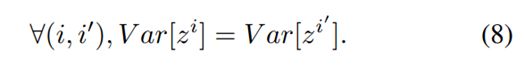
同样,反向传播时假设
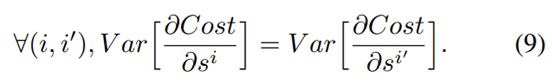
联系上两个条件,以及(6),(7)式,可以得到
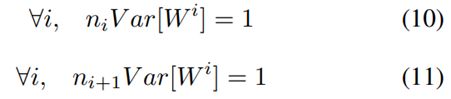
作为以上两个限制的比较,再有
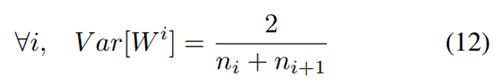
假设每层宽度和初始化参数相同,有
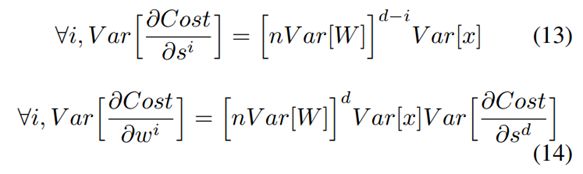
此处设置(1)中的标准初始化满足一下性质
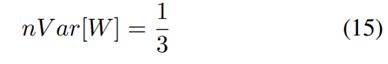



对比实验
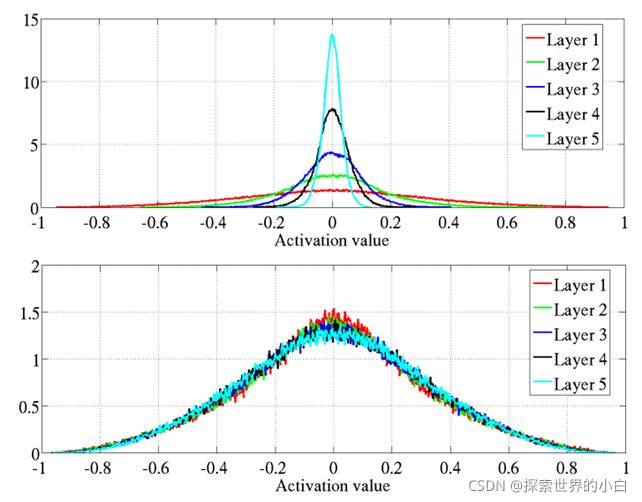
-双曲正切的激活值标准直方图。上图是原始的初始化,下图是正则初始化。
-正则初始化的网络的各层的激活值较为一致,且取值均比原始的标准初始化要小。
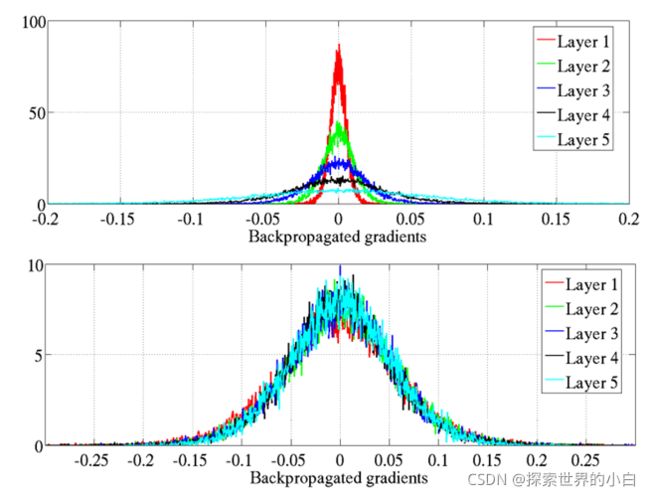
-双曲正切的反向传播梯度标准直方图。上图是原始的初始化,下图是正则初始化。
-正则初始化的网络的各层的梯度较为一致,且取值均比原始的标准初始化要小。
-作者怀疑不同层上具有不同的梯度可能会导致病态或训练较慢
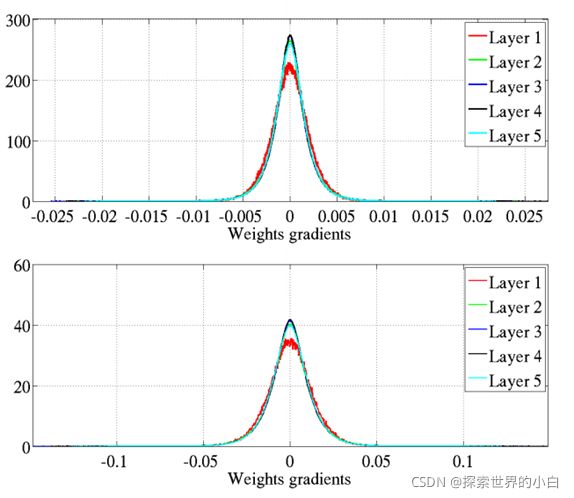
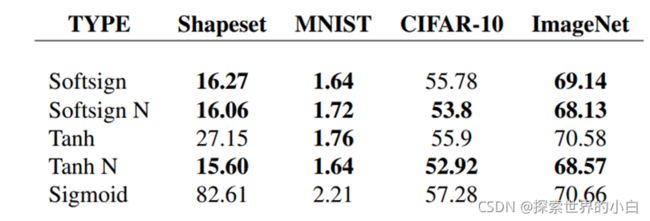
-不同层权重梯度标准直方图(***这张图其实没看懂,权重梯度这里是指什么?***)。上图是原始的初始化,下图是正则初始化。
-图中显示初始化后立刻激活,虽然使用正则初始化,反向传播梯度值减小,但权重梯度并没有减小。
-不使用新的初始化时,softsign的错误率更低。
-使用正则初始化明显降低了错误率
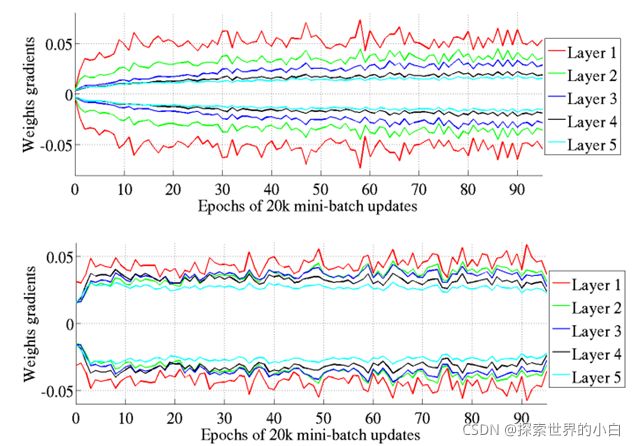
新的初始化权重梯度的方差比较一致。
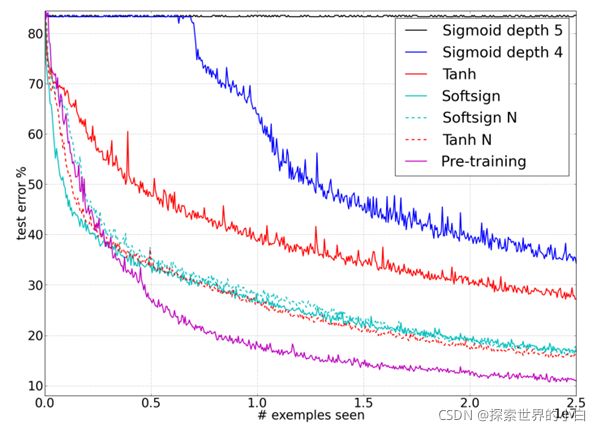
----Shapeset-2*3在线训练期间,各种激活函数和初始化方法测试错误率对比。
----未使用正则初始化时,Softsign错误率最低。
-使用正则初始化时,Tanh错误率最低。
----总的来说,都不如预训练的错误率低。
参考文献
- 聊一聊深度学习的weight initialization - 知乎 (zhihu.com)
- 深度学习中神经网络的几种权重初始化方法_天泽28的专栏-CSDN博客_神经网络初始化
- 神经网络参数初始化小结
- 卷积神经网络初始化方法总结
- 卷积神经网络的权值初始化方法