数据分析之Numpy数据存取与函数学习笔记
数据分析之numpy数据存取与函数
前言
前面我们了解了如何用numpy去创建数据,可我们是否有曾想过数据的何去何从。如果不是学习这一招,我可能也想不到。
正如我们使用Word、Excel、PPT一样,我们先是写,然后CTRL+S。
我们一起来看看?
数据的CSV文件存取
CSV文件
什么是CSV文件,这个我好像有点印象。
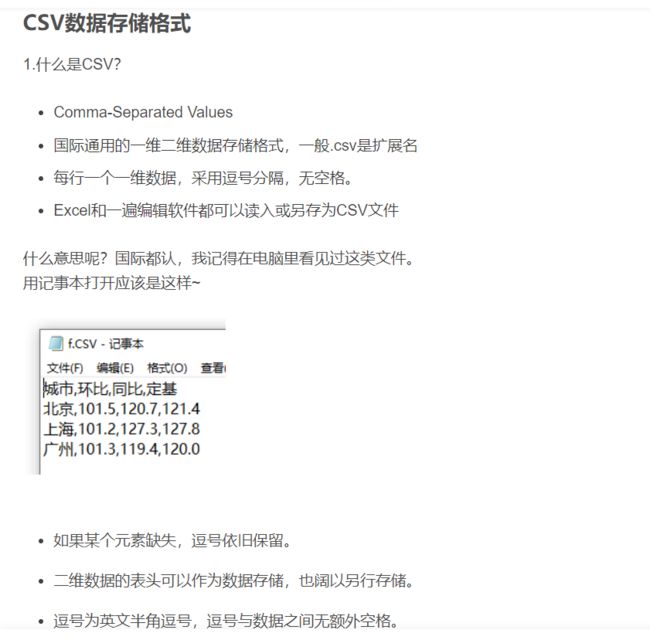
这还是出自我的博客,[地址]((27条消息) Python之文件和数据格式化学习笔记_骨Zi里的傲慢欢hhh的博客-CSDN博客)
我们说csv文件与numpy有什么关系呢,我们一起看看。
将数据存入csv文件
np.savetxt(frame, array, fmt='%.18e', delimiter=None)
参数介绍
- frame:文件、字符串或产生器,可以是
.gz或.bt2的压缩文件- array:存入文件的数组
- fmt:写入文件的格式,例如:
%d、%.2f、%.18e- delimiter:分割字符串,默认是任何空格
我们看这段代码
import numpy as np
a = np.arange(100).reshape(5, 20)
np.savetxt('a.csv', a, fmt='%d', delimiter=',')
生成二维数组,存放到a.csv文件里面。
我们看一下这个文件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1M05SE7D-1651289607773)(https://cdn.jsdelivr.net/gh/yanghuanh1314/MyPicture@master/20220423/image.png)]
修改这段代码
np.savetxt('a.csv', a, fmt='%.2f', delimiter=',')
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1oeiMUIm-1651289607774)(https://cdn.jsdelivr.net/gh/yanghuanh1314/MyPicture@master/20220423/a.csv小数形式.png)]
因此这个数组类型是小数形式,
注意delimiter 因此是CSV文件,特点是用逗号分隔,所以他的参数是delimiter=',' 。
将数据从CSV文件取出
有存数据,那么对应着就要取数据
np.loadtxt(frame, dtype=np.float, delimiter=None, unpack=False)
文件参数
- frame:文件、字符串或生成器,可以是
.gz或.bt2的压缩文件- dtype:数据类型,可选
- delimiter:分割字符串,默认是任何空格
- nupack:如果是
True,读入属性将分别写入不同变量。
我们看实例
import numpy as np
np.loadtxt('a.csv',delimiter=',')
array([[ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12.,
13., 14., 15., 16., 17., 18., 19.],
[20., 21., 22., 23., 24., 25., 26., 27., 28., 29., 30., 31., 32.,
33., 34., 35., 36., 37., 38., 39.],
[40., 41., 42., 43., 44., 45., 46., 47., 48., 49., 50., 51., 52.,
53., 54., 55., 56., 57., 58., 59.],
[60., 61., 62., 63., 64., 65., 66., 67., 68., 69., 70., 71., 72.,
73., 74., 75., 76., 77., 78., 79.],
[80., 81., 82., 83., 84., 85., 86., 87., 88., 89., 90., 91., 92.,
93., 94., 95., 96., 97., 98., 99.]])
用我们已经创建好的a.csv文件举例,读取里面的内容
np.loadtxt('a.csv',dtype=np.int, delimiter=',')
array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,
16, 17, 18, 19],
[20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35,
36, 37, 38, 39],
[40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55,
56, 57, 58, 59],
[60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75,
76, 77, 78, 79],
[80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95,
96, 97, 98, 99]])
这是什么呢,加入了参数dtype=np.int其返回数组的整数形式。
我们看无论是取文件还是取文件,都有一个frame参数,里面可以指定bt2压缩文件。这是为什么呢?因为我们现在举例的数据都是很简单的,往往在真正做数据分析的时候,数据量很大,压缩文件有什么好处呢,减少体积。这样优势就体现出来了。
CSV文件的局限性
我们说CSV文件只能存放一维、二维数组,所以对于高维数组来说就不方便了。
多维数据的存取
.tofile() 存数据
a.tofile(frame, sep=' ', formar='%s')
- frame:文件、字符串
- sep:数据分隔字符串,如果是空格,写入文件为二进制
- format:写入数据的格式
a = np.arange(100).reshape(5, 10, 2)
a.tofile('b.dat', sep=',', format='%d')
执行这段代码,会生成一个b.dat文件。.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U2Mnp682-1651289607774)(https://cdn.jsdelivr.net/gh/yanghuanh1314/MyPicture@master/20220426/b.bat.39lkonmds6g0.webp)]
这个文件怎么看呢?好像是一个一维数组,但又不像数组。它是把这100个数据全部存放进了这个文件。不显示任何维度信息
如果修改这段代码
a.tofile('b.dat', format='%d')
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2vQdxWOG-1651289607774)(https://cdn.jsdelivr.net/gh/yanghuanh1314/MyPicture@master/20220426/b.bat(2)].5djixup98mg0.webp)
这是一个二进制文件。记事本读取不了。
.fromfile() 取数据
有没有思考一个问题,一个三维数组存进这个文件,那么它的数据有效性就已经失效了。那我们该怎么取出这个数据
np.fromfile(frame, dtype=float, count=-1, sep='')
- frame:文件、字符串
- dtype:读取的数据类型
- count:读入元素个数,-1表示读入整个文件
- sep:数据分隔字符串,如果是空格,写入文件为二进制
numpy的便捷文件处理
存数据
-
np.save(fname, array)和np.savez(fname, sarray)- fname:文件名,以
.npy为扩展名.npz - array:数组变量
执行这段代码
np.save('a.npy', a)生成一个
a.npy文件。咋一看和.dat二进制形式 文件很相似,实则不然。他的第一行有一串源信息,我们可以中的关注一个这个
'shape': (5, 10, 2),已经说明了文件的形状。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bULywCHT-1651289607775)(https://cdn.jsdelivr.net/gh/yanghuanh1314/MyPicture@master/20220426/.npy文件.536g2103c7c0.webp)]`
- fname:文件名,以
取数据
-
np.load(fname)- fname:文件名,以
.npy为扩展名.npz
a = np.arange(45).reshape(3, 3, 5) c = np.load('a.npy')array([[[ 0 1 2 3 4] [ 5 6 7 8 9] [10 11 12 13 14]] [[15 16 17 18 19] [20 21 22 23 24] [25 26 27 28 29]] [[30 31 32 33 34] [35 36 37 38 39] [40 41 42 43 44]]])文件被读取出来
- fname:文件名,以
、## 总结
首先我们要清楚一点,为了不让数据失效,.tofile()和.fromfile() 要搭配使用。
之后会有没有这种疑问,.dat 文件与.npy 文件什么时候使用最恰当。
如果要让数据在多个程序之间做交互或者对接,就要用.dat 文件
如果只是单纯的做数据缓存,那么npy 即可。
numpy的随机函数
numpy的随机数函数子库
numpy的random子库
np.random.*
np.random.rand()、np.random.randn()、np.random.randint()
我们知道在python里面random库,是个标准库。而这里的这个random是numpy的字库,可以理解为库中库。
np.random的随机函数(1)
| 函数 | 说明 |
|---|---|
rand(d0, d1, … , dn) |
根据d0~dn 创建随机数组、浮点数,[0, 1) ,均匀分布 |
randn.(d0, d1, … , dn) |
根据d0~dn 创建随机数组、标准正态分布 |
randint(low[,high, shape]) |
根据shape创建随机整数或整数数组、范围是[low, high] |
seed(s) |
随机数种子,s是给定的种子值。 |
rand.(d0, d1, … , dn)
import numpy as np
a = np.random.rand(3, 4, 5)
a
array([[[0.28120548, 0.07821319, 0.44237155, 0.46073144, 0.27635178],
[0.19112944, 0.20085897, 0.35864972, 0.25263117, 0.01381603],
[0.53563111, 0.45500863, 0.68260678, 0.65261373, 0.62576019],
[0.3243867 , 0.94297831, 0.22114477, 0.15614309, 0.91795989]],
[[0.79345406, 0.9368354 , 0.52808067, 0.54034955, 0.4907499 ],
[0.94313656, 0.97562827, 0.41526498, 0.8724932 , 0.92514247],
[0.79185845, 0.55518663, 0.40708864, 0.41844115, 0.10119587],
[0.53671976, 0.9652397 , 0.28140939, 0.63912694, 0.84117078]],
[[0.91628621, 0.51093022, 0.29871787, 0.84014553, 0.99344278],
[0.93990551, 0.78198762, 0.15380773, 0.42575666, 0.970223 ],
[0.7140835 , 0.9466832 , 0.43669868, 0.39364669, 0.81995545],
[0.56506186, 0.90586015, 0.13676182, 0.68084602, 0.90321536]]])
随机生成一个(3,4,5)形状数组,每个元素都是[0, 1)之间的浮点数,均匀分布
randn(d0, d1, … , dn)
sn = np.random.randn(3, 4, 5)
sn
array([[[-0.31813714, 1.05449176, -0.00519512, 1.42775137,
-0.63852312],
[ 0.18894468, 0.75159632, -0.09577638, -1.02576066,
-0.27474 ],
[ 0.85596856, 2.46885376, 0.29822448, 2.42315726,
0.05838074],
[-1.17473348, -0.28269463, -1.87283383, -0.38024649,
-2.0380075 ]],
[[-0.75552108, -2.43733116, 1.20040429, -1.18910215,
0.07705722],
[-0.39519484, -0.5354917 , 1.79086577, 1.06665923,
0.05177091],
[-0.8237564 , -1.5275015 , -0.756546 , -1.25804629,
0.01846354],
[ 0.13309902, -0.03644387, -0.06736569, 0.48546655,
0.32402595]],
[[ 0.5921534 , 0.13702059, 1.66632111, 0.7843765 ,
-0.14725969],
[ 0.44033381, -0.88838864, -1.03321404, -1.77343827,
-0.09930781],
[-0.55767601, 1.39327197, -1.81791732, 0.86758631,
0.06348396],
[ 0.59161316, -0.41562369, -0.74737637, -0.17497282,
-0.6699793 ]]])
随机生成一个(3,4,5)形状数组,正态分布
randint(low[,high, shape])
b = np.random.randint(100, 200, (3, 4))
b
array([[123, 166, 129, 116],
[174, 167, 189, 145],
[152, 158, 139, 168]])
每一个元素都在100到200之间,并且他们抽取的概率相同。
seed()
np.random.seed(10)
np.random.randint(100, 200, (3, 4))
array([[109, 115, 164, 128],
[189, 193, 129, 108],
[173, 100, 140, 136]])
指定一个种子
np.random.seed(10)
np.random.randint(100, 200, (3, 4))
array([[109, 115, 164, 128],
[189, 193, 129, 108],
[173, 100, 140, 136]])
我们就可以随便使用这组数据了
np.random.randint(100, 200, (3, 4))
array([[116, 111, 154, 188],
[162, 133, 172, 178],
[149, 151, 154, 177]])
如果不指定种子,数组改变
np.random.seed(10)
np.random.randint(100, 200, (3, 4))
array([[109, 115, 164, 128],
[189, 193, 129, 108],
[173, 100, 140, 136]])
np.random的随机函数(2)
| 函数 | 说明 |
|---|---|
shuffle(a) |
根据数组a的第一轴进行排列,改变数组x |
permutation(a) |
根据数组a的第一轴产生一个新的乱序数组,不改变数组x |
choice(a[,size,replace,p]) |
从一维数组a中以概率p抽取元素,形成size形状新数组,raplace表示是否可以重用元素,默认为False |
shuffle(a)
import numpy as np
np.random.seed(10)
a = np.random.randint(100, 200, (3, 4))
a
array([[109, 115, 164, 128],
[189, 193, 129, 108],
[173, 100, 140, 136]])
np.random.shuffle(a)
a
array([[189, 193, 129, 108],
[173, 100, 140, 136],
[109, 115, 164, 128]])
最外层数组发生变化。我们说的第1轴就是第0轴。可以看作一维数组之间发生了变化,但是一维数组的内容没有改变。
np.random.shuffle(a)
a
array([[173, 100, 140, 136],
[189, 193, 129, 108],
[109, 115, 164, 128]])
又发生了变化
a
array([[173, 100, 140, 136],
[189, 193, 129, 108],
[109, 115, 164, 128]])
数组a也发生了变化。
permutation(a)
np.random.seed(10)
b= np.random.randint(100, 200, (3, 4))
b
array([[109, 115, 164, 128],
[189, 193, 129, 108],
[173, 100, 140, 136]])
np.random.permutation(b)
array([[189, 193, 129, 108],
[173, 100, 140, 136],
[109, 115, 164, 128]])
与shuffle(a) 功能一致,但是不改变原数组。
b
array([[109, 115, 164, 128],
[189, 193, 129, 108],
[173, 100, 140, 136]])
原数组b没有改变
choice(a[,size,replace,p])
np.random.seed(10)
c = np.random.randint(100, 200, (8))
c
array([109, 115, 164, 128, 189, 193, 129, 108])
np.random.choice(c,(3,2))
array([[115, 109],
[164, 109],
[129, 189]])
从c里面抽取元素形成一个新的(3,2)形状数组,但会发现里面有重复元素。并且每个元素抽取的概率相同。
np.random.choice(c, (3,2), replace=False)
array([[128, 193],
[108, 189],
[109, 115]])
设置replace参数,后发现抽取过的元素 不在抽取。
np.random.choice(c, (3,2), p= c/np.sum(c))
array([[108, 193],
[189, 115],
[128, 193]])
指定概率p= c/np.sum(c))对原始进行抽取,
p= c/np.sum(c)):元素的值越大,抽取概率越高。也能看出来189,193都被抽取出来。
np.random的随机函数(3)
| 函数 | 说明 |
|---|---|
uniform(low,high,size) |
产生具有均匀分布的数组,low起始值,high结束值,size形状 |
normal(loc,scale,size) |
产生具有正态分布的数组,loc均值,scale标准差,size形状 |
poisson(lam,size) |
产生具有泊松分布的数组,lam随机事件发生率,size形状 |
uniform()
import numpy as np
np.random.uniform(0, 10, (3,4))
array([[2.86050411, 0.38601258, 3.48695575, 8.3409914 ],
[6.45087789, 6.281301 , 1.02711847, 2.88548945],
[1.17391211, 5.93571687, 3.54687994, 8.54863869]])
均匀分布
normal()
np.random.normal(10, 5, (3,4))
array([[11.73416368, 10.25136196, 4.83384487, 3.65160503],
[13.46616076, 1.99036596, 9.90649987, 22.88018767],
[ 6.68440983, 6.91881734, 12.04215061, 10.25645173]])
正态分布
poisson()
np.random.poisson(5, (3,4))
array([[7, 6, 5, 6],
[5, 3, 4, 5],
[6, 5, 5, 4]])
泊松分布
numpy的统计函数
numpy直接提供的统计类函数
np.*
顾名思义,这就是统计数组的函数。
numpy的统计函数(1)
| 函数 | 说明 |
|---|---|
sum(a, axis=None) |
根据给定轴axis计算数组a相关元素之和,axis整数或元组 |
mean(a, axis=None) |
根据给定轴axis计算数组a相关元素的期望,axis整数或元组 |
average(a, axis=None, weights=None) |
根据给定轴axis计算数组a相关元素的加权平均 |
std(a, axis=None) |
根据给定轴axis计算数组a相关元素的标准差 |
var(a, axis=None) |
根据给定轴axis计算数组a相关元素的方差 |
axis=None是统计函数的标准参数,如果不给定,则对a中每一个元素进行累加计算;如果给定轴,则对轴上元素进行累计算
import numpy as np
a = np.arange(15).reshape(3, 5)
a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
np.sum(a) # 求和
105
对数组所有元素进行求和,不关心维度,应该是吧两个轴都计算了一遍。
np.sum(a,0) # 第0轴求和
array([15, 18, 21, 24, 27])
np.sum(a, 1) # 第1轴求和
array([10, 35, 60])
np.mean(a, 0) # 第0轴平均数运算
array([5., 6., 7., 8., 9.])
np.mean(a, 1) # 第1轴平均数运算
array([ 2., 7., 12.])
np.average(a , 0, [10, 5, 1]) # 加权平均
array([2.1875, 3.1875, 4.1875, 5.1875, 6.1875])
4.1875 = 2*10+7*5+12*1/(10+5+1)
np.std(a) # 标准差
4.320493798938574
np.var(a) # 方差
18.666666666666668
numpy的统计函数(2)
| 函数 | 说明 |
|---|---|
min(a) max(a) |
计算数组啊a中元素的最小值、最大值 |
argmin(a) argmax(a) |
计算数组啊a中元素的最小值、最大值的降一维后下标 |
unravel_index(index, shape) |
根据shape将一维下标index转换成多维下标 |
ptp(a) |
计算数组a元素最大值与最小值的差 |
median(a) |
计算数组a元素的中位值(中值) |
import numpy as np
b = np.random.randint(100, 200, (3, 5))
b
array([[198, 110, 171, 118, 186],
[156, 152, 184, 125, 132],
[176, 188, 139, 106, 192]])
np.min(b) # 最小值
106
np.max(b)
198
np.argmin(b) # 最小值的位置
13
第13+1个元素是106,为什么+1,因为从0开始索引。
np.unravel_index(np.argmin(b), (3,5))
(2, 3)
返回最小值的坐标.
np.ptp(b) # 极差
92
198-106
92
np.median(b) # 中位数
156.0
numpy的梯度函数
| 函数 | 说明 |
|---|---|
np.gradient(f) |
计算数组f中元素的梯度,当f为多维时,返回每个梯度, |
梯度:连续值直接的变化率,即斜率。
xy坐标轴连续三个x坐标对应的y轴值:a, b, c,其中b的梯度是:(c-a)/2,b后一个值减b前一个值除他的后一个值和他前一个值的距离。
import numpy as np
c = np.random.randint(0, 20, (5))
c
array([ 0, 18, 19, 12, 4])
np.gradient(c)
array([18. , 9.5, -3. , -7.5, -8. ])
我们看-3是怎么来的。先清楚-3是19的梯度值,因此有(12-18)/2
(12-18)/2
-3.0
19后一个值是12,前一个值是18,因此有公式(13-18)/2=-3
最后一个元素的梯度值:(他自己-他的前一个值)/1:因为距离是1
(4-12)/1
-8.0
第一个元素的梯度值:(他的前一个值-他自己)/1:因为距离是1
(18-0)/1
18.0
d = np.random.randint(0, 20, (5))
d
array([11, 17, 18, 0, 4])
np.gradient(d)
array([ 6. , 3.5, -8.5, -7. , 4. ])
(17-11)/1
6.0
那么二维数组呢?
f = np.random.randint(0, 50, (3,5))
f
array([[37, 5, 3, 23, 27],
[ 4, 0, 31, 24, 48],
[16, 36, 39, 14, 32]])
np.gradient(f)
[array([[-33. , -5. , 28. , 1. , 21. ],
[-10.5, 15.5, 18. , -4.5, 2.5],
[ 12. , 36. , 8. , -10. , -16. ]]),
array([[-32. , -17. , 9. , 12. , 4. ],
[ -4. , 13.5, 12. , 8.5, 24. ],
[ 20. , 11.5, -11. , -3.5, 18. ]])]
因为是二维数组,所以每一个元素值存在两个方向。返回两个数组。
第一个数组是最外层维度的梯度值
第二个数组是第二层维度的梯度值
我们试着计算最大值的梯度
np.unravel_index(np.argmax(f), (3,5)) # 找最大值
(1, 4)
最大值的位置是(1,4)是48
np.max(f)
48
先求48的最外层梯度
(32-27)/2
2.5
48的第二层层梯度
(48-24)/1
24.0
如果是个n维数组,那就会返回n个数组。
梯度有什么用呢?反映了元素的变化率,尤其是在图像、声音等批量数据处理的时候,梯度有助于发现图像或声音的边缘,不是变化很平缓的地方,通过梯度很容易发现。所以在我们进行图像处理、声音处理、多媒体运算的时候,
gradient()函数就会发生很大的作用
总结
数据处理,这里我学会了怎么保存数据或者取出数据。然后我们用统计函数做一些简单的统计。
这部分内容还算比较简单,但是函数贼多,不过没关系,我可以从我这里复制。
好了,我的学习笔记到此结束。
里面肯定有许许多多的bug,欢迎大家指出!毕竟这样成长更快。
也感谢大家可以看到这样,如果帮到了你,是我的荣幸。
谢谢大家!
[ 4, 0, 31, 24, 48],
[16, 36, 39, 14, 32]])
np.gradient(f)
[array([[-33. , -5. , 28. , 1. , 21. ],
[-10.5, 15.5, 18. , -4.5, 2.5],
[ 12. , 36. , 8. , -10. , -16. ]]),
array([[-32. , -17. , 9. , 12. , 4. ],
[ -4. , 13.5, 12. , 8.5, 24. ],
[ 20. , 11.5, -11. , -3.5, 18. ]])]
因为是二维数组,所以每一个元素值存在两个方向。返回两个数组。
第一个数组是最外层维度的梯度值
第二个数组是第二层维度的梯度值
我们试着计算最大值的梯度
np.unravel_index(np.argmax(f), (3,5)) # 找最大值
(1, 4)
最大值的位置是(1,4)是48
np.max(f)
48
先求48的最外层梯度
(32-27)/2
2.5
48的第二层层梯度
(48-24)/1
24.0
如果是个n维数组,那就会返回n个数组。
梯度有什么用呢?反映了元素的变化率,尤其是在图像、声音等批量数据处理的时候,梯度有助于发现图像或声音的边缘,不是变化很平缓的地方,通过梯度很容易发现。所以在我们进行图像处理、声音处理、多媒体运算的时候,
gradient()函数就会发生很大的作用
总结
数据处理,这里我学会了怎么保存数据或者取出数据。然后我们用统计函数做一些简单的统计。
这部分内容还算比较简单,但是函数贼多,不过没关系,我可以从我这里复制。
好了,我的学习笔记到此结束。
里面肯定有许许多多的bug,欢迎大家指出!毕竟这样成长更快。
也感谢大家可以看到这样,如果帮到了你,是我的荣幸。
谢谢大家!