【xv6 RISC-V】xv6操作系统原理解析与源代码阅读报告
目录
-
- 导言
- 1.系统调用(syscall)
-
- (1)基本原理
- (2)源代码分析
-
- i)用户代码
- ii)内核代码
- 2.陷阱(trap)
-
- (1)基本原理
- (2)源代码分析
- 3.内存管理(memory management)
-
- (1)基本原理
-
- i)页表与地址转换
- ii)地址空间
- (2)源代码分析
- 4.多线程(multithreading)
-
- (1)基本原理
- (2)源代码分析
- 5.锁(lock)
-
- (1)基本原理
- (2)源代码分析
- 6.文件系统(file system)
-
- (1)基本原理
- (2)源代码分析
- 结语
-
- 参考资料
导言
本文具体分析了基于RISC-V多核处理器的xv6操作系统的基本理论与具体实现,通过阅读对应源代码,研究了包括系统调用、陷阱、内存管理、多线程、锁与文件系统等操作系统的重要组成部分,结合mit的lab对其中某些具体实现进行了部分改进。下面将会结合重点核心代码对各部分进行具体阐述。
1.系统调用(syscall)
(1)基本原理
为了实现不同的系统功能,xv6系统定义了一系列系统调用号与对应的内核处理程序。当应用程序需要使用某一项功能时,可以首先将系统调用号送入a7寄存器,然后执行ecall指令,该指令导致系统陷入内核并执行相应的系统调用处理程序,处理完成后将控制权还给用户程序。
(2)源代码分析
i)用户代码
- user/user.h:该头文件为用户空间的代码提供了系统调用API的显式声明,这样不论是用户程序还是库代码都可以直接调用这些API:
// system calls
int fork(void);
int exit(int) __attribute__((noreturn));
int wait(int*);
int pipe(int*);
int write(int, const void*, int);
int read(int, void*, int);
int close(int);
int kill(int);
int exec(char*, char**);
int open(const char*, int);
int mknod(const char*, short, short);
int unlink(const char*);
int fstat(int fd, struct stat*);
int link(const char*, const char*);
int mkdir(const char*);
int chdir(const char*);
int dup(int);
int getpid(void);
char* sbrk(int);
int sleep(int);
int uptime(void);
int trace(int);
int sysinfo(struct sysinfo *);
- user/usys.pl:该文件用于生成汇编代码“usys.S”,即系统调用的用户汇编入口,其代码清晰地展现了用户程序将系统调用号放入a7寄存器并执行ecall指令的过程:
sub entry {
my $name = shift;
print ".global $name\n";
print "${name}:\n";
print " li a7, SYS_${name}\n";
print " ecall\n";
print " ret\n";
}
ii)内核代码
- kernel/syscall.h:该文件为每一个系统调用分配了系统调用号,原始共23个。
- kernel/syscall.c:该文件定义了重要的数组“syscalls”,该数组以函数地址为内容,将系统调用号映射到对应的系统调用入口。此外,syscall()函数根据用户进程a7寄存器传入的系统调用号,通过查数组进行对应的系统调用,并将函数返回值存入用户进程的a0寄存器。
- kernel/sysproc.c:该文件包含进程相关系统调用的具体定义。
- kernel/proc.h:该文件定义了进程相关的重要数据结构,包括PCB结构proc,上下文结构context,逻辑处理器结构cpu,以及每个进程独有的trapframe结构。其中比较重要的proc结构包含了进程的pid,状态,上下文,页表,打开文件表等信息,是操作系统控制与管理进程的核心:
// Per-process state
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state
struct proc *parent; // Parent process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
struct trapframe *trapframe; // data page for trampoline.S
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
int tmask; // Trace mask as args of sys_trace
};
- kernel/proc.c:该c文件包含了操作系统进程管理的相关具体实现,包括fork(),exec(),sleep(),wait()等重要函数。
2.陷阱(trap)
(1)基本原理
引发操作系统trap的通常有以下几种情况:一种是系统调用,当用户程序执行ecall指令要求内核为其做某事时;另一种情况是异常:一条指令(用户或内核)做了一些非法的事情,如除以零或使用无效的虚拟地址;第三种情况是设备中断,当一个设备发出需要注意的信号时,例如当磁盘硬件完成一个读写请求时。Xv6 trap 处理分为四个阶段:trap迫使控制权转移到内核;内核保存寄存器和其他状态,以便恢复执行;内核执行适当的处理程序代码(例如,系统调用实现或设备驱动程序);内核恢复保存的状态,并从trap中返回,代码从原来的地方恢复执行。
每个RISC-V CPU都有一组控制寄存器,内核写入这些寄存器来告诉CPU如何处理trap,内核可以通过读取这些寄存器来发现已经发生的trap,以下是一些重要的寄存器:
-
stvec:内核在这里写下trap处理程序的地址;RISC-V跳转到这里来处理trap。
-
sepc:当trap发生时,RISC-V会将程序计数器保存在这里(因为PC会被stvec覆盖)。sret(从trap中返回)指令将sepc复制到pc中。内核可以写sepc来控制sret的返回到哪里。
-
scause:RISC -V在这里放了一个数字,描述了trap的原因。
-
sscratch:内核在这里放置了一个值,在trap处理程序开始时可以方便地使用。
-
sstatus:sstatus中的SIE位控制设备中断是否被启用,如果内核清除SIE,RISC-V将推迟设备中断,直到内核设置SIE。SPP位表示trap是来自用户模式还是supervisor模式,并控制sret返回到什么模式。
当需要执行trap时,RISC-V硬件对所有的trap类型(除定时器中断外)进行以下操作:
- 如果该trap是设备中断,且sstatus SIE位为0,则不执行以下任何操作。
- 通过清除SIE来禁用中断。
- 复制pc到sepc。
- 将当前模式(用户态或特权态)保存在sstatus的SPP位。
- 在scause设置该次trap的原因。
- 将模式转换为特权态。
- 将stvec复制到pc。
- 从新的pc开始执行。
(2)源代码分析
- kernel/trampoline.S:该汇编代码定义了用户空间陷入内核与离开内核的汇编接口,包含两个重要的汇编过程:uservec与userret。其中uservec首先通过sscratch获取用户空间trapframe的地址,将寄存器值存储在用户进程的trapframe中,并从该结构中恢复内核栈与页表,然后跳转到usertrap()执行相应的处理程序。而userret则相应地恢复了之前存储的寄存器值并执行sret指令返回到用户空间。
- kernel/trap.c:该文件分别定义了从用户态陷入与从内核态陷入的中断处理程序,其中usertrap()函数根据scause寄存器的值判断当前系统中断的原因并进行相应的处理。特别地,当该中断为时钟中断时,系统会强制该进程放弃cpu。最后,usertrap()调用usertrapret(),该函数将内核栈等信息保存在进程trapframe中,将PSW设置为用户态并调用userret返回。
3.内存管理(memory management)
(1)基本原理
i)页表与地址转换
xv6操作系统使用基于页表的虚拟内存管理方式,一个RISC-V页表在逻辑上是一个由 2 27 2^{27} 227(134,217,728)个页表项(Page Table Entry, PTE)组成的数组。每个PTE包含一个44位的物理页号(Physical Page Number, PPN)和一些标志位。分页硬件通过利用39位中的高27位索引到页表中找到一个PTE来转换一个虚拟地址,并计算出一个56位的物理地址,它的前44位来自于PTE中的PPN,而它的后12位则是从原来的虚拟地址复制过来的。如图所示,在逻辑上可以把页表看成是一个简单的PTE数组,操作系统通过页表来控制虚拟地址到物理地址的转换,其粒度为4096( 2 12 2^{12} 212)字节的对齐块,即内存页。
一个页表以三层树的形式存储在物理内存中。树的根部是一个 4096 字节的页表页,它包含 512 个 PTE,这些 PTE 包含树的下一级页表页的物理地址。每一页都包含 512 个 PTE,用于指向下一个页表或物理地址。分页硬件用 27 位中的高 9 位选择根页表页中的 PTE,用中间 9 位选择树中下一级页表页中的 PTE,用低 9 位选择最后的 PTE。
每个 PTE 都包含标志位,用于告诉分页硬件相关的虚拟地址被允许怎样使用。PTE_V 表示 PTE 是否存在:如果没有设置,对该页的引用会引起异常(即不允许)。PTE_R 控制是否允许指令读取该页。PTE_W 控制是否允许指令向该页写入。PTE_X 控制 CPU 是否可以将页面的内容解释为指令并执行。PTE_U 控制是否允许用户态下的指令访问页面;如果不设置 PTE_U, 对应 PTE 只能在内核态下使用。
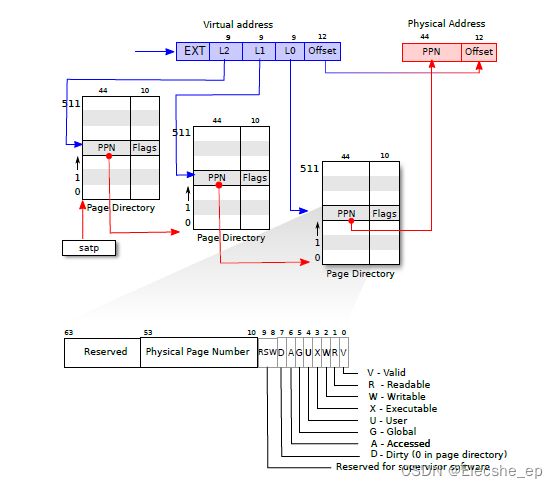
要告诉硬件使用一个页表,内核必须将对应根页表页的物理地址写入 satp 寄存器中。每个 CPU 都有自己的 satp 寄存器。一个 CPU 将使用自己的 satp 所指向的页表来翻译后续指令产生的所有地址。每个 CPU 都有自己的 satp,这样不同的 CPU 可以运行不同的进程,每个进程都有自己的页表所描述的私有地址空间。
ii)地址空间
- 内核地址空间:如图所示,QEMU 模拟的计算机包含 RAM( 物理内存),从物理地址 0x80000000 开始, 至少到 0x86400000,xv6 称之为 PHYSTOP。QEMU 模拟还包括 I/O 设备,如磁盘接口。QEMU 将设备接口作为内存映射(memory-mapped)的控制寄存器暴露给软件,这些寄存器位于物理地址空间的 0x80000000 以下。内核可以通过读取/写入这些特殊的物理地址与设备进行交互;这种读取和写入与设备硬件而不是与 RAM 进行通信。内核对RAM和内存映射的设备寄存器使用“直接映射”,也就是将这些资源映射到和它们物理地址相同的虚拟地址上,然而trampoline 页与内核栈页则使用了间接映射。

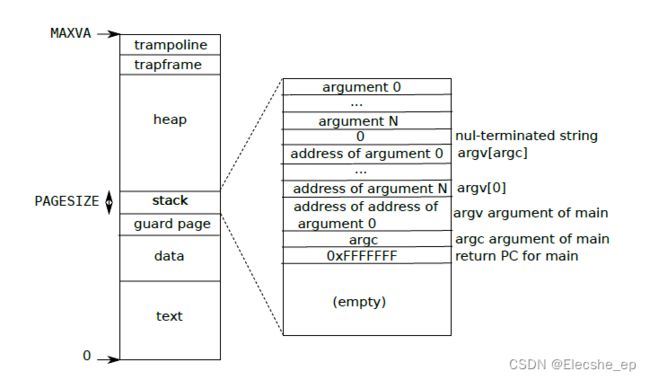
- 用户地址空间:如图所示,一个进程的用户内存从虚拟地址 0 开始,可以增长到 MAXVA(kernel/riscv.h:348),原则上允许一个进程寻址 256GB 的内存。当一个进程要求 xv6 提供更多的用户内存时,xv6 首先使用 kalloc 来分配物理页,然后将指向新物理页的 PTE 添加到进程的页表中。Xv6 设置这些 PTE 的 PTE_W、PTE_X、PTE_R、PTE_U 和 PTE_V 标志。大多数进程不使用整个用户地址空间;xv6 将不使用的 PTE 的 PTE_V 位保持为清除状态。首先,不同的进程页表将用户地址转化为物理内存的不同页,这样每个进程都有私有的用户内存。第二,每个进程都认为自己的内存具有从零开始的连续的虚拟地址,而进程的物理内存可以是不连续的。第三,内核会映射带有 trampoline 代码的页到用户地址空间顶端,因此,有一物理内存页在所有地址空间中都会出现。
(2)源代码分析
- kernel/memlayout.h:该头文件具体定义了riscv物理内存的布局,包括内核基址,物理内存上界trampoline页地址等:
// qemu -machine virt is set up like this,
// based on qemu's hw/riscv/virt.c:
//
// 00001000 -- boot ROM, provided by qemu
// 02000000 -- CLINT
// 0C000000 -- PLIC
// 10000000 -- uart0
// 10001000 -- virtio disk
// 80000000 -- boot ROM jumps here in machine mode
// -kernel loads the kernel here
// unused RAM after 80000000.
// the kernel uses physical memory thus:
// 80000000 -- entry.S, then kernel text and data
// end -- start of kernel page allocation area
// PHYSTOP -- end RAM used by the kernel
- kernel/kalloc.c:该文件用于进行物理内存分配,其核心结构是线程安全的空闲内存空间列表kmem:
struct run {
struct run *next;
};
struct {
struct spinlock lock;
struct run *freelist;
} kmem;
与此相关的是两个核心函数:kalloc()与kfree(),其中kalloc()函数从空闲链表头去除一个空闲页,清理后返回其指针,而kfree()函数则将参数指针指向的内存页清理后重新插入空闲链表,等待下一次分配。
- kernel/vm.c:该文件是xv6进行虚拟内存管理的核心代码,其维护了内核页表kernel_pagetable,下面对一些重要的函数进行分析:
kvminit()函数按照memlayout.h规定的内存布局为内核初始化页表,通过这种方式初始化内核地址空间。与此对应,uvmcreate()与uvminit()用于初始化用户空间页表。
mappages()函数则是用来进行内存映射的主要功能函数,给定页表,虚拟地址va与物理地址pa,该函数在页表中建立对应虚拟地址的PTE表项,将PTE_V位置为1。
walk()函数根据上文提到的页表三层树结构进行逐层遍历,最终返回给定虚拟地址对应的PTE表项,该函数可以根据给定的alloc参数,在页表项不存在时进行分配。
uvmalloc()用于为用户进程页表分配新的空间,uvmdealloc()则用来释放多余的用户空间。uvmcopy()函数用来完成父进程到子进程页表的复制,在原始的实现中,该函数在完成页表项复制的同时也会进行物理内存的完全复制,这种方式显然带来了过多的拷贝开销。在改进的写时复制(COW)实现方式中,我们不再进行实际物理内存的复制,取而代之的是将父子进程对应的页表项标记为只读的写时复制页,这样当且仅当进程企图进行写操作时,这些页才真正完成复制,成为进程的私有页,大大减少了内存拷贝开销,改进了fork()的效率。
除此之外,copyout()与copyin()用于在内核与用户空间之间完成内存拷贝。
4.多线程(multithreading)
(1)基本原理
多线程并发一直是多处理器操作系统关心的问题,特别地,xv6为我们用户级多线程的解决方案(在这里我们讨论的是mit提供的lab:multithreading)。在该实现中,每个用户级线程都拥有自己的上下文,线程栈与线程状态。管理程序通过维护全局的线程控制数组与运行线程指针来完成用户级的线程调度。
(2)源代码分析
- user/uthread_switch.S:该文件定义了线程切换的汇编过程thread_switch,其中包括保存旧线程的callee_saved寄存器,栈指针寄存器sp,返回地址寄存器ra,以及恢复新线程的对应寄存器值。
- user/uthread.c:该文件定义了用户线程的抽象数据结构,包括线程上下文tcontext,线程控制块thread,控制块数组all_thread,以及当前运行线程的控制块指针current_thread:
/* Possible states of a thread: */
#define FREE 0x0
#define RUNNING 0x1
#define RUNNABLE 0x2
#define STACK_SIZE 8192
#define MAX_THREAD 4
struct tcontext {
uint64 ra;
uint64 sp;
// callee-saved
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
};
struct thread {
char stack[STACK_SIZE]; /* the thread's stack */
int state; /* FREE, RUNNING, RUNNABLE */
struct tcontext context; /* thread context */
};
struct thread all_thread[MAX_THREAD];
struct thread *current_thread;
比较重要的线程管理函数有线程创建函数thread_create(),线程调度函数thread_schedule(),其中thread_create()遍历线程控制块数组,找到当前空闲的控制块,将其返回地址寄存器ra设置为给定的函数地址并将状态设置为RUNNABLE以完成一个新线程的插入。thread_schedule()函数从当前运行线程的控制块开始循环遍历线程控制块数组,找到下一个可运行的线程,一旦找到就进行线程切换,开始运行新线程。
5.锁(lock)
(1)基本原理
线程安全问题是基于并发的多处理器操作系统面临的核心挑战。为了解决这类问题,锁的创建与使用显得至关重要。锁提供了互斥的功能,确保一次只有一个CPU可以持有一个特定的锁。如果程序员为每个共享数据项关联一个锁,并且代码在使用某项时总是持有关联的锁,那么该项每次只能由一个CPU使用。在这种情况下,我们说锁保护了数据项。虽然锁是一种简单易懂的并发控制机制,但其也带来了性能降低的缺点,因为锁将并发操作串行化了。
xv6提供了两种类型的锁:自旋锁(spinlock)和睡眠锁(sleeplock)。自旋锁会让CPU在锁上自旋等待,可能会浪费大量CPU时间,而睡眠锁则会在锁被占用时主动让出CPU,允许其他线程运行并进入阻塞态等待唤醒。因此自旋锁最适合于短的关键部分,而睡眠锁对长的操作很有效。
xv6对锁的使用有粗粒度与细粒度两种方式:作为粗粒度锁的一个例子,xv6的kalloc.c分配器有一个单一的空闲列表,由一个单一的锁构成。如果不同CPU上的多个进程试图同时分配页面,那么每个进程都必须通过在acquire中旋转来等待轮到自己。旋转会降低性能,因为这不是有用的工作。如果争夺锁浪费了相当一部分CPU时间,也许可以通过改变分配器的设计来提高性能,使其拥有多个空闲列表,每个列表都有自己的锁,从而实现真正的并行分配。
作为细粒度锁的一个例子,xv6为每个文件都有一个单独的锁,这样操作不同文件的进程往往可以不用等待对方的锁就可以进行。如果想让进程模拟写入同一文件的不同区域,文件锁方案可以做得更细。最终,锁的粒度决定需要由性能测量以及复杂性考虑来驱动。
(2)源代码分析
- kernel/spinlock.h:定义了自旋锁数据结构,其中locked字段用来区分锁是否被占用:
// Mutual exclusion lock.
struct spinlock {
uint locked; // Is the lock held?
// For debugging:
char *name; // Name of lock.
struct cpu *cpu; // The cpu holding the lock.
#ifdef LAB_LOCK
int nts;
int n;
#endif
};
- kernel/sleeplock.h:定义了睡眠锁数据结构,其中含有一个spinlock用于保护对临界变量的访问:
// Long-term locks for processes
struct sleeplock {
uint locked; // Is the lock held?
struct spinlock lk; // spinlock protecting this sleep lock
// For debugging:
char *name; // Name of lock.
int pid; // Process holding lock
};
- kernel/spinlock.c:该文件定义了自旋锁相关操作,其中acquire()使用了可移植的C库调用__sync_lock_test_and_set,它本质上为amoswap指令;返回值是lk->locked的旧(被交换出来的)内容。acquire函数循环交换,重试(旋转)直到获取了锁。每一次迭代都会将1交换到lk->locked中,并检查之前的值;如果之前的值为0,那么我们已经获得了锁,并且交换将lk->locked设置为1。如果之前的值是1,那么其他CPU持有该锁,而我们原子地将1换成lk->locked并没有改变它的值。
// Acquire the lock.
// Loops (spins) until the lock is acquired.
void
acquire(struct spinlock *lk)
{
push_off(); // disable interrupts to avoid deadlock.
if(holding(lk))
panic("acquire");
#ifdef LAB_LOCK
__sync_fetch_and_add(&(lk->n), 1);
#endif
// On RISC-V, sync_lock_test_and_set turns into an atomic swap:
// a5 = 1
// s1 = &lk->locked
// amoswap.w.aq a5, a5, (s1)
while(__sync_lock_test_and_set(&lk->locked, 1) != 0) {
#ifdef LAB_LOCK
__sync_fetch_and_add(&(lk->nts), 1);
#else
;
#endif
}
// Tell the C compiler and the processor to not move loads or stores
// past this point, to ensure that the critical section's memory
// references happen strictly after the lock is acquired.
// On RISC-V, this emits a fence instruction.
__sync_synchronize();
// Record info about lock acquisition for holding() and debugging.
lk->cpu = mycpu();
}
- kernel/sleeplock.c:该文件定义了睡眠锁的相关操作,其中acquiresleep()在发现当前锁被占用时调用sleep()主动放弃CPU,为其他线程提供运行机会,在整个过程中我们使用自旋锁lk保护对临界字段locked的访问:
void
acquiresleep(struct sleeplock *lk)
{
acquire(&lk->lk);
while (lk->locked) {
sleep(lk, &lk->lk);
}
lk->locked = 1;
lk->pid = myproc()->pid;
release(&lk->lk);
}
- kernel/kalloc.c:由于全局的空闲链表上只有一把大锁,因此如果不同CPU上的多个进程试图同时分配页面,那么每个进程都必须通过在acquire中旋转来等待轮到自己。为此,我们可以改进该结构,为每个CPU单独分配一个空闲链表与对应的自旋锁,这样不同CPU的内存分配就不会再互相干扰:
struct {
struct spinlock lock;
struct run *freelist;
} kmem[NCPU];
void *
kalloc(void)
{
struct run *r;
push_off();//turn interrupts off
int id = cpuid();
pop_off();//turn interrupts on
acquire(&kmem[id].lock);
r = kmem[id].freelist;
if(r)
kmem[id].freelist = r->next;
else{// steal mem from other cpus
for(int i=0; i<NCPU; i++)
{
if(i == id) continue;
acquire(&(kmem[i].lock));
r = kmem[i].freelist;
if(r)
{
kmem[i].freelist = r->next;
release(&(kmem[i].lock));
break;
}
release(&(kmem[i].lock));
}
}
release(&kmem[id].lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
- kernel/bio.c:该文件是磁盘块缓存的管理单元,其中核心数据结构bcache使用一个大自旋锁保护:
struct {
struct spinlock lock;
struct buf buf[NBUF];
// Linked list of all buffers, through prev/next.
// Sorted by how recently the buffer was used.
// head.next is most recent, head.prev is least.
struct buf head;
} bcache;
为了提高并行效率,我们可以改进该结构,使用基于哈希表的细粒度多自旋锁:
struct {
struct spinlock lock[NBUCKET];
struct buf buf[NBUF];
struct buf head[NBUCKET]; // hash buckets of linked list
} bcache;
这样在bget()中为特定标号的磁盘块寻找缓存块时,首先将其哈希到对应的桶中,在对应的桶中完成查找空闲的buffer,如果没找到则从其他桶中“窃取”,这种方式大大提高了磁盘块缓存的并行性能。
6.文件系统(file system)
(1)基本原理

如图所示,xv6文件系统的实现分为七层。disk层在virtio磁盘上读写块。Buffer cache缓存磁盘块,并同步访问它们,确保一个块只能同时被内核中的一个进程访问。日志层允许上层通过事务更新多个磁盘块,并确保在崩溃时,磁盘块是原子更新的(即全部更新或不更新)。inode层将一个文件都表示为一个inode,每个文件包含一个唯一的i-number和一些存放文件数据的块。目录层将实现了一种特殊的inode,被称为目录,其包含一个目录项序列,每个目录项由文件名称和i-number组成。路径名层提供了层次化的路径名,如/usr/rtm/xv6/fs.c,可以用递归查找解析他们。文件描述符层用文件系统接口抽象了许多Unix资源(如管道、设备、文件等),使程序员的生产力得到大大的提高。

文件系统必须安排好磁盘存储inode和内容块的位置。为此,xv6将磁盘分为几个部分,如图所示。文件系统不使用块0(它存放boot sector)。第1块称为superblock,它包含了文件系统的元数据(以块为单位的文件系统大小、数据块的数量、inode的数量和日志中的块数)。从块2开始存放着日志。日志之后是inodes,每个块会包含多个inode。在这些块之后是位图块(bitmap),记录哪些数据块在使用。其余的块是数据块,每个数据块要么在bitmap块中标记为空闲,要么持有文件或目录的内容。超级块由一个单独的程序mkfs写入,它建立了一个初始文件系统。
(2)源代码分析
- kernel/fs.h:该文件定义了磁盘上的文件系统格式,其中包括超级磁盘块superblock,磁盘inode结构dinode,目录项结构dirent:
// super block describes the disk layout:
struct superblock {
uint magic; // Must be FSMAGIC
uint size; // Size of file system image (blocks)
uint nblocks; // Number of data blocks
uint ninodes; // Number of inodes.
uint nlog; // Number of log blocks
uint logstart; // Block number of first log block
uint inodestart; // Block number of first inode block
uint bmapstart; // Block number of first free map block
};
// On-disk inode structure
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+1]; // Data block addresses
};
// Directory is a file containing a sequence of dirent structures.
struct dirent {
ushort inum;
char name[DIRSIZ];
};
在原始的实现中,dinode使用了直接映射与一级间接映射结合的方式,addrs数组前11项直接指向映射的磁盘块地址,而最后一项指向一级索引表的磁盘地址,这种方式最多支持 12 + B S I Z E / s i z e o f ( u i n t ) 12 + BSIZE / sizeof(uint) 12+BSIZE/sizeof(uint)个磁盘块大小的文件。
- kernel/fs.c:该文件是xv6文件系统的具体实现,包含许多低层次的文件操作接口。其中定义了用于缓存inode结构的cache:
struct {
struct spinlock lock;
struct inode inode[NINODE];
} icache;
ialloc()函数在磁盘上分配给定类型的dinode块并返回可用的inode结构,iget()函数用于获取给定序号的inode缓存,ilock()与iunlock()用于管理inode上的锁结构。bmap()函数基于上面提到的直接与一级索引结构,查找inode中给定块号的磁盘块地址,而readi()与writei()函数基于bmp()完成给定inode块对应文件的读写操作。
- kernel/file.h:该文件内存中的inode结构,其内容基本是磁盘上dinode块的拷贝,此外基于此定义了虚拟file结构:
struct file {
#ifdef LAB_NET
enum { FD_NONE, FD_PIPE, FD_INODE, FD_DEVICE, FD_SOCK } type;
#else
enum { FD_NONE, FD_PIPE, FD_INODE, FD_DEVICE } type;
#endif
int ref; // reference count
char readable;
char writable;
struct pipe *pipe; // FD_PIPE
struct inode *ip; // FD_INODE and FD_DEVICE
#ifdef LAB_NET
struct sock *sock; // FD_SOCK
#endif
uint off; // FD_INODE
short major; // FD_DEVICE
};
// in-memory copy of an inode
struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count
struct sleeplock lock; // protects everything below here
int valid; // inode has been read from disk?
short type; // copy of disk inode
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT+1];
};
- kernel/file.c:该文件定义了全局文件表ftable与操作系统管理文件结构的相关功能函数,包括读写文件的fileread()与filewrite(),获取文件元数据的filestat()等:
struct {
struct spinlock lock;
struct file file[NFILE];
} ftable;
- kernel/sysfile.c:该文件定义了文件系统相关的系统调用,包括打开关闭调用sys_open()与sys_close(),读写调用sys_read()与sys_write(),重定向调用sys_dup(),文件链接调用sys_link(),以及建立管道调用sys_pipe()与程序加载调用sys_exec()等。
结语
作为简化版Unix操作系统,xv6中包含了操作系统各项核心功能(进程调度,内存管理,文件系统等)简单而有效的实现。阅读源代码,结合相关资料进行对比分析,可以帮助我们更加深入而全面地了解操作系统的设计原则与核心精神。
参考资料
[1]xv6-riscv (https://github.com/mit-pdos/xv6-riscv)
[2]xv6-riscv-book (https://pdos.csail.mit.edu/6.S081/2020/xv6/book-riscv-rev1.pdf)
[2]xv6-riscv-labs (https://pdos.csail.mit.edu/6.828/2020/xv6.html)