OS内核(xv6)探究-系统调用
内核态和用户态
计算机在加载操作系统之后,再继续执行任何指令的时候,都会处在某种特权级下(privilege)。例如在Linux下,可能会有ring0,ring1,ring2,ring3等几种状态,这些状态可以简单的分成用户态和内核态两种。我们写的上层应用的代码大多数情况运行在用户态,当我们的程序需要执行一些特殊的任务的时候,例如:访问文件,发起网络请求,向屏幕输出文字,fork一个子进程等等,我们的用户态程序是不具备这些权限的,只能把这些任务委托给操作系统(通过系统调用),因为只有运行在内核态的操作系统才有权限做这些事情。
为什么要区分用户态和内核态呢?最重要的原因还是要对计算机进行保护。内核态的代码往往要操作文件,网络,屏幕,外设,还有一些非常关键的指令,如设置中断向量表、全局描述符表等,这些资源和操作都是高度重要的,如果操作不当就会导致计算机完全崩溃、宕机,所以必须保证执行这些操作的代码是最可靠的代码。上层应用代码往往是不太可靠的,或因为程序bug,甚至可能有恶意程序,所以操作系统觉不能把这些操作交给用户程序去执行。这就像在我们家中电源、电器、刀具等器件只能由大人来使用,不能让小孩子使用,并且要尽量锁起来或者放在小孩子够不到的地方来加以保护。
一般用用户态陷入内核态的方式有三种:
- 中断:例如时钟中断,外设中断
- 异常:例如CPU除零操作,段错误
- 系统调用:上层应用通过指令主动调起,例如int80,int3

什么是系统调用
了解了用户态和内核态我们也就基本理解了系统调用。系统调用就是操作系统为用户程序提供的一系列API接口,来帮助用户程序完成一些操作。这些API接口基本都封装在标准库中,例如C语言的libc库,C语言中常见的系统调用例如:open(打开文件),print,fork,getpid等等。从用户程序的角度来看,系统调用是用户程序和操作系统的唯一接口,用户程序只能通过系统调用感知操作系统的存在。其他的操作系统功能,例如进程切换,页机制等机制对于用户程序来说则是完全透明。
系统调用一方面保护了计算机,另一方面也帮助用户程序封装了底层功能的实现,这些实现往往都是非常复杂的,系统调用帮助用户程序提高了开发效率。
同时如果能提供一套标准的系统调用API接口就可能大大增强上层应用软件的可移植性,比较常见的标准就是POSIX标准。
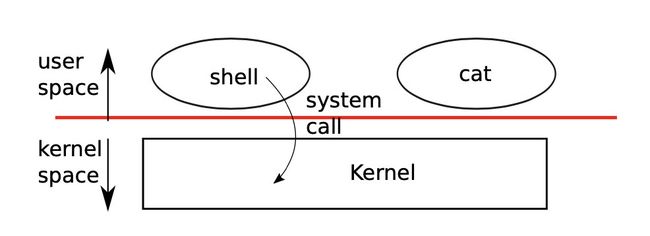
系统调用和过程调用的区别
主要区别:
- 执行的指令:系统调用是从用户程序代码跳转到操作系统代码(内核地址空间);过程调用是用户程序在执行过程中跳转到自己的代码或者动态库的代码(用户地址空间)。
- 特权级的改变:系统调用要从用户态切换到内核态;过程调用不用切换,全部在用户态完成。
- 函数栈:系统调用发生时,要从用户栈切换到内核栈;过程调用不切换,在当前栈完成。
- 传参:系统调用基本使用寄存器传参;过程调用使用栈或者寄存器传参。
一个典型的系统调用过程大概如下:用户程序->调用标准库->切换到内核态->通过系统调用号跳转到对应的系统调用实现->系统调用执行完成->结果返回给用户程序并切换回用户态。
一个典型的过程调用的过程可以参考之前的博客:x86_64汇编下的函数调用过程
xv6系统调用的过程分析
系统调用过程当中有几个关键技术点:
- 系统调用号:用户程序通过指定一个系统调用号来告诉操作系统应该执行哪个系统调用。xv6中使用a7寄存器来传递这个调用号。
- 系统调用指令:指定系统调用号以后,用户程序执行系统调用指令,该指令会提升特权级只内核态,保存用户程序执行的上下文,然后跳到内核的处理系统调用的代码去执行。xv6这条指令是ecall,x86里是int80。
- trapframe:trapframe是一小段内存,主要负责在内核态和用户态转换时保存一些执行现场。
- 用户栈,内核栈:执行系统调用前,用户程序使用用户栈,跳转到系统调用后,内核代码使用独立的内核栈。
- 传参:系统调用使用寄存器传参,如果寄存器不够用,那么可以让寄存器指向一块内存,在这块内存里在存放多个参数。
我们剖析一下xv6中系统调用过程的实现,我们以echo程序为例,echo程序是一个shell程序,它是一个上层应用程序。
在echo中,write和exit是系统调用,只有它们是执行在内核态的。其余的代码是执行在用户态的。
int
main(int argc, char *argv[])
{
int i;
// write 和 exit 都是系统调用,只有这两条语句是执行在内核态的,其余的代码是执行在用户态的
for(i = 1; i < argc; i++){
write(1, argv[i], strlen(argv[i]));
if(i + 1 < argc){
write(1, " ", 1);
} else {
write(1, "\n", 1);
}
}
exit(0);
}
那么write和exit是怎么实现的呢?其实它们的实现代码是一样的,只不过是传了不同的系统调用号。
// 不同系统调用的系统调用号
#define SYS_fork 1
#define SYS_exit 2
#define SYS_wait 3
#define SYS_pipe 4
#define SYS_read 5
#define SYS_kill 6
#define SYS_exec 7
#define SYS_fstat 8
#define SYS_chdir 9
#define SYS_dup 10
#define SYS_getpid 11
#define SYS_sbrk 12
#define SYS_sleep 13
#define SYS_uptime 14
#define SYS_open 15
#define SYS_write 16
#define SYS_mknod 17
#define SYS_unlink 18
#define SYS_link 19
#define SYS_mkdir 20
#define SYS_close 21
#define SYS_sysinfo 22
// 不同的系统调用使用不同的系统调用号(传给a7寄存器),然后统一调用ecall指令。
.global fork
fork:
li a7, SYS_fork
ecall
ret
.global exit
exit:
li a7, SYS_exit
ecall
ret
.global read
read:
li a7, SYS_read
ecall
ret
.global write
write:
li a7, SYS_write
ecall
ret
sysinfo:
li a7, SYS_sysinfo
ecall
ret
......
......
......
系统调用进入到内核代码后,内核主要逻辑就是一个分发逻辑,根据系统调用号分发到不同的系统调用实现,并把执行的结果返回给用户程序,这个结果通过a0寄存器传递。
// syscalls是一个函数指针数组,下标是系统调用号,值是系统调用函数实现的指针
static uint64 (*syscalls[])(void) = {
[SYS_fork] sys_fork,
[SYS_exit] sys_exit,
[SYS_wait] sys_wait,
[SYS_pipe] sys_pipe,
[SYS_read] sys_read,
[SYS_kill] sys_kill,
[SYS_exec] sys_exec,
[SYS_fstat] sys_fstat,
[SYS_chdir] sys_chdir,
[SYS_dup] sys_dup,
[SYS_getpid] sys_getpid,
[SYS_sbrk] sys_sbrk,
[SYS_sleep] sys_sleep,
[SYS_uptime] sys_uptime,
[SYS_open] sys_open,
[SYS_write] sys_write,
[SYS_mknod] sys_mknod,
[SYS_unlink] sys_unlink,
[SYS_link] sys_link,
[SYS_mkdir] sys_mkdir,
[SYS_close] sys_close,
[SYS_sysinfo] sys_sysinfo,
};
// 内核处理分发系统调用,并返回执行结果
void
syscall(void)
{
int num;
struct proc *p = myproc();
// 通过a7寄存器取出系统调用号
num = p->trapframe->a7;
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
// 根据系统调用号,找到对应的系统调用实现并执行,执行结果通过a0寄存器返回给用户程序
p->trapframe->a0 = syscalls[num]();
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
// 用户程序调用系统调用是,通过a0~a5这6个寄存器来传递入参
static uint64
argraw(int n)
{
struct proc *p = myproc();
switch (n) {
case 0:
return p->trapframe->a0;
case 1:
return p->trapframe->a1;
case 2:
return p->trapframe->a2;
case 3:
return p->trapframe->a3;
case 4:
return p->trapframe->a4;
case 5:
return p->trapframe->a5;
}
panic("argraw");
return -1;
}
可以看到系统调用的用户端实现和系统端实现都是比较简单的。复杂的地方在用户态和内核态两种状态相互转换的地方,也就是ecall(从用户态到内核态)和sret(从内核态到用户态)两条指令。实现这两条指令有两个关键点:
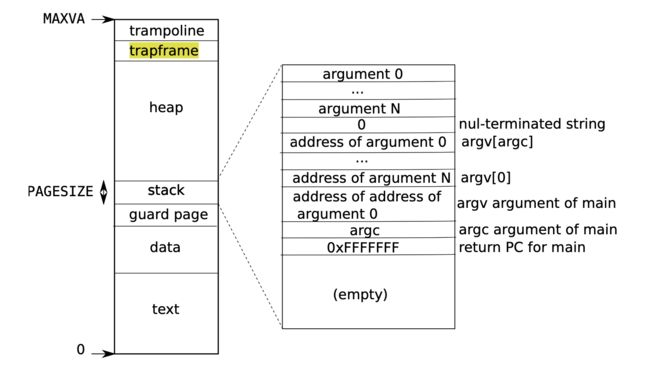
- trampoline:是一段汇编代码,有两段实现uservec和userret
1.1 uservec对应ecall,主要任务是把寄存器状态存在trapframe中,然后跳转到内核syscall函数
1.2 userret对应sret,主要任务是把寄存器状态从trapframe中恢复,然后跳转到之前用户程序的指令(应该值保存指令的下一条指令)并继续执行 - trapframe:一小段内存,用于保存执行现场(寄存器状态)
可以看出状态转换的重点主要是特权级变化和保存/恢复现场。
.globl trampoline
trampoline:
.globl uservec
uservec:
# 执行ecall后会把特权级提升至内核态
# 其他的逻辑 balabala
.......
# 保存当前的用户态寄存器状态到 TRAPFRAME
sd ra, 40(a0)
sd sp, 48(a0)
sd gp, 56(a0)
sd tp, 64(a0)
sd t0, 72(a0)
sd t1, 80(a0)
sd t2, 88(a0)
sd s0, 96(a0)
sd s1, 104(a0)
sd a1, 120(a0)
sd a2, 128(a0)
sd a3, 136(a0)
sd a4, 144(a0)
sd a5, 152(a0)
sd a6, 160(a0)
sd a7, 168(a0)
sd s2, 176(a0)
sd s3, 184(a0)
sd s4, 192(a0)
sd s5, 200(a0)
sd s6, 208(a0)
sd s7, 216(a0)
sd s8, 224(a0)
sd s9, 232(a0)
sd s10, 240(a0)
sd s11, 248(a0)
sd t3, 256(a0)
sd t4, 264(a0)
sd t5, 272(a0)
sd t6, 280(a0)
# 其他的逻辑 balabala
.......
# 跳转到内核的系统调用处理程序
jr t0
.globl userret
userret:
# 其他的逻辑 balabala
......
# 从 RAPFRAME中恢复用户态的寄存器状态
ld ra, 40(a0)
ld sp, 48(a0)
ld gp, 56(a0)
ld tp, 64(a0)
ld t0, 72(a0)
ld t1, 80(a0)
ld t2, 88(a0)
ld s0, 96(a0)
ld s1, 104(a0)
ld a1, 120(a0)
ld a2, 128(a0)
ld a3, 136(a0)
ld a4, 144(a0)
ld a5, 152(a0)
ld a6, 160(a0)
ld a7, 168(a0)
ld s2, 176(a0)
ld s3, 184(a0)
ld s4, 192(a0)
ld s5, 200(a0)
ld s6, 208(a0)
ld s7, 216(a0)
ld s8, 224(a0)
ld s9, 232(a0)
ld s10, 240(a0)
ld s11, 248(a0)
ld t3, 256(a0)
ld t4, 264(a0)
ld t5, 272(a0)
ld t6, 280(a0)
# 其他的逻辑 balabala
.......
# 返回到用户程序继续执行
sret
这里指的注意的一点是trampoline和trapframe在内存中的位置。图中可以看到他们分布在用户虚拟地址空间的最高处,trampoline和trapframe这两块内存有一个特点:他们在用户地址空间和内存地址空间的内存映射页表是一样的,即无论从内核态还是用户态访问这两块内存是使用的逻辑地址一样,最终映射到的物理地址也一样。这样做是为了简化状态转换这部分的实现。关于内存映射页表,后面还会继续探究。
一些总结
- 系统调用是用户程序使用计算机底层资源的接口
- 系统调用是操作系统保护底层资源,保护计算机正常运行的一项重要机制
- 系统调用封装了底层实现,降低了上层应用程序开发的复杂度。但系统调用开销较大,应尽量减少、优化对系统调用的使用。
- 要理解系统调用一些相关技术细节:用户态和内核态的切换、参数传递,保存现场、系统调用号,中断处理等。