【数据集的制作】VOC2007数据集格式的转换(voc2yolo)与划分
文章目录
- 安装labelImg
- 将数据集为划分训练集和验证集
-
- 下载VOC2007数据集并挑选我们需要的
- 数据集格式转化 voc2yolo
- 运行结果:
- 数据集划分为测试集和验证集:
- 运行结果:
- 更简单的方法,转化数据格式的同时分割数据
-
- 将代码与数据集放在同一级目录下
- 更改classes并运行程序
- 运行结果:
参考博客:
【目标检测】YOLOv5跑通VOC2007数据集(修复版)
安装labelImg
在Anaconda Prompt中直接安装,依次执行以下命令
pip install PyQt5 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install pyqt5-tools -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install labelImg -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装完成后,直接在Anaconda Prompt输入labelImg
打开一张图片。
左侧工具栏没什么好介绍的。主要是YOLO那一栏,点击可以切换不同的数据格式。
| 标签格式 | 文件格式 |
|---|---|
| yolo | txt |
| VOC | xml |
| createML | json |
将数据集为划分训练集和验证集
下载VOC2007数据集并挑选我们需要的
利用VOC2007 data训练我们的Yolo-v5网络。 下面将介绍如何下载、转化和分割数据集。
The PASCAL Visual Object Classes Challenge 2007

下载这两个数据集,直接解压就会生成一个合并的文件。

一般目标检测只需用到Annotations、ImageSets、JPEGImages这3个文件夹,剩下的可以删掉。

ImageSets:文件夹下有3个子文件夹:Layout、Main、Segmentation,我们只用到Main文件夹,其他可以删掉。下面看一下Main文件夹下的内容:
VOC数据集共包含:训练集(5011幅),测试集(4952幅),共计9963幅图,共包含20个种类。
Annotations: 存放所有图片的标注xml文件;
JPEGImages:9963张图片 .jpg
ImageSets:数据集划分文件,类别标签
数据集格式转化 voc2yolo
在用Yolo训练voc数据集时,需要将xml格式的标签转换为txt格式的标签。
使用前应注意:
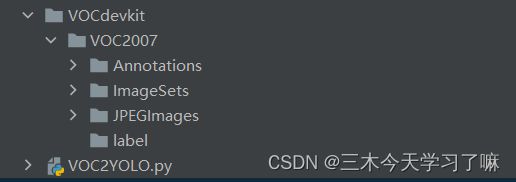
├── voc2yolo.py
└── VOCdevkit
└── VOC2007
├── Annotations
├── ImageSets
├── JPEGImages
└── labels
Annotations用来存放xml格式的标注文件;
JPEGImages存放图片数据集;
labels存放转换后的txt标注文件,目前是空文件夹。
将classes=[“class1”,“class2”]改成你要转换的数据集对应的类别即可 (注意类别顺序),其他的默认即可。
运行下面的代码(voc2yolo),之后会在labels文件夹生成转换成功的txt文件,同时会在根目录下生成train.txt test.txt。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
classes=["aeroplane", 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] # class names
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' %image_id)
out_file = open('VOCdevkit/VOC2007/labels/%s.txt' %image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
work_sapce_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
work_sapce_dir = os.path.join(work_sapce_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
VOC_file_dir = os.path.join(work_sapce_dir, "ImageSets/")
if not os.path.isdir(VOC_file_dir):
os.mkdir(VOC_file_dir)
VOC_file_dir = os.path.join(VOC_file_dir, "Main/")
if not os.path.isdir(VOC_file_dir):
os.mkdir(VOC_file_dir)
train_file = open(os.path.join(wd, "2007_train.txt"), 'w')
test_file = open(os.path.join(wd, "2007_test.txt"), 'w')
train_file.close()
test_file.close()
VOC_train_file = open(os.path.join(work_sapce_dir, "ImageSets/Main/train.txt"), 'w')
VOC_test_file = open(os.path.join(work_sapce_dir, "ImageSets/Main/test.txt"), 'w')
VOC_train_file.close()
VOC_test_file.close()
if not os.path.exists('VOCdevkit/VOC2007/labels'):
os.makedirs('VOCdevkit/VOC2007/labels')
train_file = open(os.path.join(wd, "2007_train.txt"), 'a')
test_file = open(os.path.join(wd, "2007_test.txt"), 'a')
VOC_train_file = open(os.path.join(work_sapce_dir, "ImageSets/Main/train.txt"), 'a')
VOC_test_file = open(os.path.join(work_sapce_dir, "ImageSets/Main/test.txt"), 'a')
list = os.listdir(image_dir) # list image files
probo = random.randint(1, 100)
print("Probobility: %d" % probo)
for i in range(0,len(list)):
path = os.path.join(image_dir,list[i])
if os.path.isfile(path):
image_path = image_dir + list[i]
voc_path = list[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
probo = random.randint(1, 100)
print("Probobility: %d" % probo)
if(probo < 75):
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
VOC_train_file.write(voc_nameWithoutExtention + '\n')
convert_annotation(nameWithoutExtention)
else:
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
VOC_test_file.write(voc_nameWithoutExtention + '\n')
convert_annotation(nameWithoutExtention)
train_file.close()
test_file.close()
VOC_train_file.close()
VOC_test_file.close()
运行结果:

数据集划分为测试集和验证集:
首先在原有数据集下新建val并建立images和labels。

修改下列代码中你的文件目录,运行。
import os, random, shutil
def moveimg(fileDir, tarDir):
pathDir = os.listdir(fileDir) # 取图片的原始路径
filenumber = len(pathDir)
rate = 0.1 # 自定义抽取图片的比例,比方说100张抽10张,那就是0.1
picknumber = int(filenumber * rate) # 按照rate比例从文件夹中取一定数量图片
sample = random.sample(pathDir, picknumber) # 随机选取picknumber数量的样本图片
print(sample)
for name in sample:
shutil.move(fileDir + name, tarDir + "\\" + name)
return
def movelabel(file_list, file_label_train, file_label_val):
for i in file_list:
if i.endswith('.jpg'):
# filename = file_label_train + "\\" + i[:-4] + '.xml' # 可以改成xml文件将’.txt‘改成'.xml'就可以了
filename = file_label_train + "\\" + i[:-4] + '.txt' # 可以改成xml文件将’.txt‘改成'.xml'就可以了
if os.path.exists(filename):
shutil.move(filename, file_label_val)
print(i + "处理成功!")
if __name__ == '__main__':
fileDir = r"C:\Users\三木今天学习了吗\Desktop\数据集小技巧\VOCdevkit\VOC2007\JPEGImages" + "\\" # 源图片文件夹路径
tarDir = r'C:\Users\三木今天学习了吗\Desktop\数据集小技巧\VOCdevkit\VOC2007\val\images' # 图片移动到新的文件夹路径
moveimg(fileDir, tarDir)
file_list = os.listdir(tarDir)
file_label_train = r"C:\Users\三木今天学习了吗\Desktop\数据集小技巧\VOCdevkit\VOC2007\labels" # 源图片标签路径
file_label_val = r"C:\Users\三木今天学习了吗\Desktop\数据集小技巧\VOCdevkit\VOC2007\val\labels" # 标签
# 移动到新的文件路径
movelabel(file_list, file_label_train, file_label_val)
运行结果:

更简单的方法,转化数据格式的同时分割数据
VOC标签格式转yolo格式并划分训练集和测试集
将代码与数据集放在同一级目录下

更改classes并运行程序
classes=["aeroplane", 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat',
'chair', 'cow', 'diningtable', 'dog','horse', 'motorbike', 'person',
'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] # class names
运行结果:
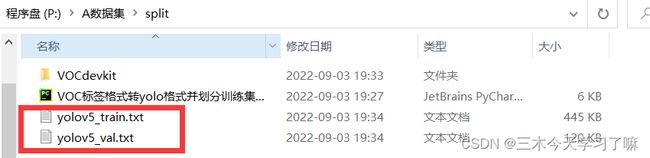
首先,在同级目录下得到了yolov5训练和验证的目录文件。

其次,得到训练和验证下的图片和标签。
在VOC2007中得到yolo的数据集格式。方便了我们后续的使用。


后续,将在Yolo-V5网络中训练这个数据集,并进行预测。
挖个坑:
传送门: 【目标检测算法】YOLO-V5实战检测VOC2007数据集