利用谱聚类和随机分块(SBM)来做网络模型中的社区发现
项目如下:
【1】项目背景
在过去的几十年里, 网络数据的数量和对相关统计推断工具的需求在快速增长. 网络数据分析的主要研究课题之一是从单一的观察网络中找出隐藏的社区. 简单地讲, 网络社区指的是相互靠近的个体更容易连接的现象, 因此边缘密度在同一个社区内和社区之间都是不同的. 当前人们的生活中充满了各种各样的网络, 包括社会网络、生物网络、通信网络等. 研究者希望通过网络社区划分加深对复杂网络的了解. 例如, 将社区检测用于了解社会行为、蛋白质与蛋白质的相互作用、基因表达、 个性化产品推荐、网页排序等. 社区检测或图聚类的最基本目标是将图的节点划分为几个内部连接更紧密的簇. 自 20 世纪 80 年代以来, 对社区检测方法的研究已有极大的发展, 在机器学习、网络科学、社会科学和统计物理学等不同领域, 学者提出了各种不同的网络社区检测的方法. 本项目给出几个基于网络社区检测方法的应用.
【2】案例实战
1. 政治博客数据集(见附件Pol_Blogs_CSV文件)
数据集网址一: Political blogs
数据集网址二: http://www.casos.cs.cmu.edu/computational_tools/datasets/external/polblogs/index11.php
政治博客数据是由Adamic和Glance于2005年收集并分析的. 该数据集包含了2004年美国总统选举前不久的1000多个网络日志的快照, 其中节点是网络日志, 边是超链接. 节点被标记为自由派或保守派, 这可以被视为两个定义明确的社区. 请尝试使用随机分块模型对这一数据集进行建模, 使用谱聚类算法对该数据集进行社区聚类, 并对所建模型及聚类结果给出合理的解释.
这里介绍几个与题目相关的文章供大家参考:
谱聚类(spectral clustering)及其实现详解_杨铖的博客-CSDN博客_spectral clustering
NetworkX画图:nx.draw_networkx(函数详解)_橙子啵啵的博客-CSDN博客_nx.draw()
NetworkX画图:nx.draw_networkx(函数详解)_橙子啵啵的博客-CSDN博客_nx.draw()
以下是案例代码:
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import warnings
warnings.filterwarnings("ignore") # 忽略警告
G = nx.read_gml('D:\\薇尔希丝\\博客.gml') # 读取GML文件
node_attr = nx.get_node_attributes(G, 'value') # 获取所有节点属性值value
a = len(set(node_attr.values())) # 计算社区的数量,共2个
print("社区的数量", a)
community_array = [0, 0] # 根据社区数量建立一个一维数组,元素值为0
for i in node_attr.values(): # 计算两个社区的节点数
if i == 0:
community_array[0] += 1 # 统计value为0的节点数
else:
community_array[1] += 1 # 统计value为1的节点数
print("value为0和1结点数组成的数组", community_array) # 输出value为0和1结点数组成的数组
edge_matrix = np.zeros((a, a)) # 创建一个全为0的二阶矩阵,用于存储边的数量
for edge in G.edges(): # 遍历每条边
node1, node2 = edge # 获取边的两个端点对应的结点
A = node_attr[node1] # 获取这两个节点所属的社区
B = node_attr[node2]
edge_matrix[A][B] += 1 # 对应类型边的数量叠加(有0-0,0-1,1-0,1-1四种)
print("已存储完毕的边矩阵", edge_matrix) # 输出最终的边矩阵
probability = np.zeros((a, a)) # 创建一个全为0的概率矩阵,用于存储社区之间的连接概率
probability[0][0] = edge_matrix[0][0] / (community_array[0] * (community_array[0] - 1)) # 计算value为0的社区内部之间的连接概率
probability[1][1] = edge_matrix[1][1] / (community_array[1] * (community_array[1] - 1)) # 计算value为1的社区内部之间的连接概率
probability[0][1] = edge_matrix[0][1] / (community_array[0] * community_array[1]) # 计算0指向1社区之间的连接概率
probability[1][0] = edge_matrix[1][0] / (community_array[1] * community_array[0]) # 计算1指向0社区之间的连接概率
print("概率矩阵", probability) # 输出概率矩阵
model = nx.stochastic_block_model(sizes=community_array, p=probability, seed=100, directed=True) # 随机分块模型
nx.draw(model, with_labels=True) # 在节点上绘制标签
plt.show() # 绘制出分块模型
L = nx.directed_laplacian_matrix(model).A # 获得拉普拉斯矩阵
cha_values, cha_vector = np.linalg.eig(L) # 计算拉普拉斯矩阵的特征值和特征向量
D = cha_vector[:, :2] # 取前两个特征向量创建特征矩阵D
D = (D - D.mean(axis=0)) / D.std(axis=0) # 对特征矩阵D进行标准化处理
# 构建kmeans聚类模型
kmeans = KMeans(init="k-means++", n_clusters=2) # 应用k-means++进行聚类加速,设置为2个簇
kmeans.fit(D) # 利用特征矩阵D来拟合kmeans模型
kmeans_labels = kmeans.labels_ # 获取每个节点的聚类标签
colors = ["b" if label == 0 else "g" for label in kmeans_labels] # 创建colors数组储存两个颜色(聚类标签为0的蓝色,1的绿色)
nx.draw_networkx(model, pos=D, node_color=colors) # 以随机分块后的model为图,以D为字典,colors为节点的颜色
plt.show() # 绘制聚类结果
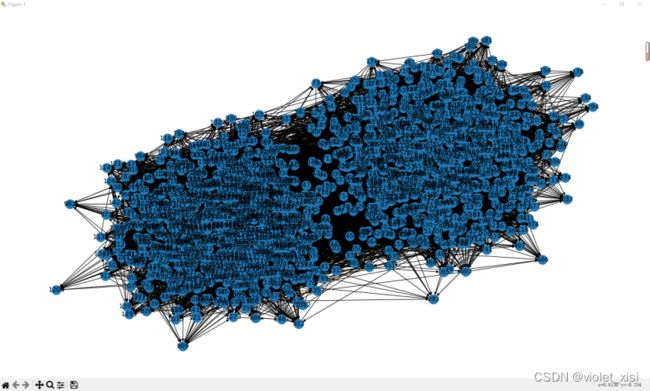
下图是随机分块后的模型
下图是kmeans聚类后的模型

结果分析:先用SBM进行随机分块得到初步模型,这个模型内所有的结点聚在一起,能够大概看出这些结点是分为两个社区的(value为0或1),但是并不能完全区分开来,节点的颜色都一样,两个社区的交界处并不是很清晰,中间的结点不知道属于哪个社区。经过kmeans聚类后,在对两个社区的结点换上不同的颜色,两者间的区别就显而易见了,中间的分界线也非常清晰。可以观测到有几个结点与其他节点不太一样,最为明显的是173这个结点,它和两个社区距离都比较远,说明它和两个社区的紧密度都不太高,相比之下更靠近聚类标签为0的社区,因此也被划分到了该社区。其次就是556,272等结点,比173与社区紧密度更高,和其他结点比相对较低。整体的聚类效果还是很不错的。
以上仅供参考,若有不足请多包含。