3.设计模式之分层思维:为什么要做代码分层架构?
一、代码分层架构是什么
软件程序通常有两个层面的需求:
-
功能性需求,简单来说,就是一个程序能为用户做些什么,比如,文件上传、查询数据等;
-
非功能性需求,这个是指除功能性需求以外的其他必要需求,比如,性能、安全性、容错与恢复、本地化、国际化等。
事实上,非功能性需求所构建起来的正是我们所熟知的软件架构。什么是软件架构?简单来说,就是软件的基本结构,包括三要素:代码、代码之间的关系和两者各自的属性。
我们都知道,软件架构非常重要,为什么重要呢?如果把软件比作一座高楼,那么软件架构就是那个钢筋混凝土的框架,代码就是那个框架里的砖石,正是因为有了那个框架,才能让每一个代码都能很好地运行起来。
其中,最为经典的软件架构就是分层架构,也就是将软件系统进行分层,现在几乎已经成为每个程序员最熟悉的思考模式之一。不过,分层架构越是流行,我们的设计越容易僵化。这背后到底有哪些值得我们深思的地方呢?
所以,今天我就从架构角度来聊聊为什么代码要做分层、主要用于解决什么问题,以及存在优势和劣势有哪些。
要想彻底理解代码分层架构,就得从软件部署分层架构说起。首先我们来看一下常见的互联网软件部署分层架构,如下图所示:

由图可以看到,软件部署分层架构主要包括以下四个核心部分。
-
客户端层(Client):调用方,比如浏览器或 App。
-
应用服务层的网页服务器(Web Server):实现程序的运行逻辑,并从下层获取数据,返回给上层的客户端层。
-
应用服务层的缓存(Cache):加速访问存储的数据。
-
数据层(DB):存储数据。
通过上面的分析,现在你应该知道什么是软件分层架构了吧?软件分层架构是通过层来隔离不同的关注点(变化相似的地方),以此来解决不同需求变化的问题,使得这种变化可以被控制在一个层里。
作为软件开发者,我们更关心的其实是应用程序里的分层架构。比如,下图展示的现在流行的一种 MVC 分层架构:

我们能明显看到,MVC 分层架构是作用于程序本身的,程序作为一个整体被发布在服务器上运行使用。而类似 DB 里也有自己的分层架构,这里我们重点介绍应用程序中的代码分层架构,其他架构就不展开讨论了。
那么问题来了,什么是代码分层架构呢?
代码分层架构就是将软件“元素”(代码)按照“层”(代码关系)的方式组织起来的一种结构。
分层架构核心的原则是:当请求或数据从外部传递过来后,必须是从上一层传递给下一层。如下图,一个来自 View 层的数据,必须先通过 Controller 层、Model 层后,才能最终到达数据库层。
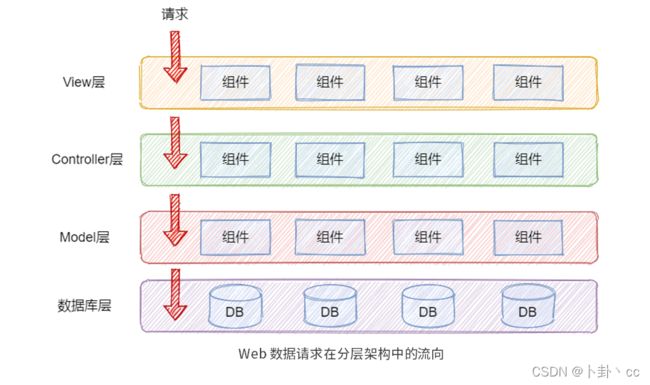
那么你可能会问:“为什么不让 View 层的请求直接到达数据库呢?”这是因为会造成新的代码耦合,增加代码的复杂度。比如说,View 层直接调用 Model 层的组件,当 Model 层上的组件有变化时(比如, SQL 或逻辑修改),既会影响 Controller 层组件的使用,也会影响 View 层组件的使用(可参考下面的示意图)。

所以,分层的本质就是为了让相似变化在各自的层内变化,而不造成层与层之间的相互影响。
二、代码分层架构解决什么问题
代码分层架构主要是为了解决两个问题:
-
如何快速拆解功能问题?
-
如何提升代码的可扩展性?
下面我们就来分别解释下。
1. 通过分层来拆解问题
在软件开发中,一个功能需求问题通常都是笼统的复杂问题,我们一般都会将这个笼统的复杂问题拆分为多个层次的子问题来解决。
这里来看一个简单的例子,假定你正在编写一段“通过 HTTP 向服务器发送字符串”的代码,如下所示:
//创建HTTP连接
URL url = new URL("http://xxx.test.com/sayHello");
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.connect();
//发送数据
OutputStream os = connection.getOutputStream();
os.write("Hello World!".getBytes("UTF-8"));
//接收响应
InputStream is = connection.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8"));
//……
br.close();
is.close();
os.close();
//关闭连接
connection.disconnect();
我们将这段代码简单地抽象成一个流程图,如下所示:

这个流程图代表了我们对最初始问题的分层拆分:先创建 HTTP 连接,然后向服务器发送一串字符串,最后关闭 HTTP 连接。
于是,原先的“如何通过 HTTP 向服务器发送字符串”的问题就变成了三个新层次的子问题:
-
如何创建 HTTP 连接?
-
如何发送字符串?
-
如何关闭连接?
首先,在思考如何创建 HTTP 连接这个问题的过程中,你会发现,要想通过 HTTP 发送消息,至少得打开 HTTP 连接,建立 HTTP 会话,并使用 TCP 协议,这样才能通过网络发送数据。
接着,你又发现,当成功解决了这个问题后,发送字符串和关闭 HTTP 连接还有更多的问题需要解决,于是,你开始一步一步地去分解……最后的分解结果如下图所示:

当所有子问题都被成功解决以后,最初通过 HTTP 向服务器发送字符串的总问题也就得以解决了。
你发现没有,在不知不觉中你就通过分层将一个复杂的大问题分解为多个容易解决的子层问题。而实际上,有的子层问题已经被前人解决过了,比如,如何使用 HTTP 协议来进行网络数据的通信。也就是说,最后真正需要关注的问题其实变少了。
所以说,从功能性需求角度来看,代码分层本身就是一种拆解复杂问题的好方法。
2. 通过分层来提升代码可扩展性
分层架构的出现,除了解决拆分复杂问题的困境外,还解决了代码可扩展性的问题。
为什么要提升代码可扩展性?因为真实的系统数据一直在不断增加。比如说,一个电商网站的用户访问数会从一万个并发增长到十万个并发,或者从一百万增长到一千万。过去的单体架构之所以很难承载,是因为当我们需要扩展服务器和数据库功能时,一处的代码修改就会影响所有的功能。
分层架构可以将复杂的逻辑切分为多个层,这样大问题就变成了多个小问题,而我们可以很方便地解决每个小问题。每个小问题更容易被抽象为一个组件,当组件功能需要扩充或替换时,修改代码的影响也被有效地控制在有限的范围内,这样组件自身的复用性也就提高了。
除了提高代码组件之间的复用性外,分层架构还让我们更容易做服务的横向扩展。
什么是横向扩展?简单来说,就是用多台配置较低的服务器共同提供服务,也就是我们熟知的集群部署服务方式。比如说,将 Model 层抽取出来作为通用的数据服务部署,这样既不影响其他业务层,也能在负载增加时,快速扩展服务的承载能力。
三、代码分层架构的优势和劣势
到这里,代码分层结构的优势体现在哪儿就很清楚了,大致可总结为如下:
-
只用关注整个结构中的其中某一层的具体实现;
-
降低层与层之间的依赖;
-
很容易用新的实现来替换原有层次的实现;
-
有利于标准化的统一;
-
各层逻辑方便复用。
总结来说,代码分层架构设计主要为了实现责任分离、解耦、组件复用和标准制定。
如果不使用分层架构的话,我们的代码逻辑一定会紧紧依赖在一起,修改某一处必定影响其他很多处。从软件项目的角度看,这样会造成非常严重的影响。比如,一个上传功能需要存入下载链接到数据库,如果没有分层,那么当修改存储的路径或类型时,还得修改存储数据库的业务逻辑,想想就很麻烦。
另外,层与层之间进行划分后,也提高了组件之间的复用性,层本身就是一种组件形式,通过统一的接口来与外界进行交互,而不再是按照功能上的依赖来进行交互。而统一的接口是模块之间相互约定的统一标准,只要按照标准来进行代码实现,就不会因为代码改动而影响接口的使用。
虽然代码分层有很多好处,但不可避免地也会有一些劣势。
-
开发成本变高:因为不同层分别承担各自的责任,如果是高层次新增功能,则需要多个低层增加代码,这样难免会增加开发成本。
-
性能降低:请求数据因为经过多层代码的处理,执行时长加长,性能会有所消耗。
-
代码复杂度增加:因为层与层之间存在强耦合,所以对于一些组合功能的调用,则需要增加很多层之间的调用。
四、总结
软件分层架构是通过层来隔离不同的关注点(变化相似的地方),以此来解决不同需求变化的问题,使得这种变化可以被控制在一个层里。
代码分层架构的核心作用有两个:
-
对于功能性需求,将复杂问题分解为多个容易解决的子层问题;
-
对于非功能性需求,可以提升代码可扩展性。
总结来说,代码分层架构是一种软件架构设计方法。
-
从软件的功能性需求角度看,分层是为了把较大的复杂问题拆分为多个较小的问题,在分散问题风险的同时,让问题更容易被解决,也就是我们常说的解耦。
-
从架构(非功能性需求)角度看,分层能提升代码可扩展性,帮助开发人员在相似的变化中修改代码。
其实,复杂的设计概念和简单的代码之间存在一种平衡,这就是分层架构。
-
代码分层架构设计的思维模型是简化思维,本质是抽象与拆解。
-
代码分层架构设计的目的是将复杂问题拆分为更容易解决的小问题,降低实现难度。
-
代码分层架构设计的原则和方法是通用方法,可以应用到其他需要分层设计的地方。
所以,分层架构从来不是目的,只是让我们的软件变得更好的其中一种思维方法而已。
五、课后思考
除了分层架构外,你还熟悉哪些其他架构设计模式?有哪些优势和劣势?