YOLOv5 ——极市平台:口罩识别
YOLOv5推理
001-模型导出
1)output修改
yolov5 6.1版本的 模型输出包含了 输入的部分,需要去掉(最新版本代码添加了 一个self.export 判断,去掉了export时输出x问题),

输出只需要output这一项:
# yolo.py
class Detect(nn.Module):
......
def forward(self, x):
......
# return x if self.training else (torch.cat(z, 1), x) 修改为:
return x if self.training else torch.cat(z, 1)
2)等价onnx-simplify操作
这部分不是必须的,可以直接使用onnx-simplify直接简化模型。这里只是我分析精度损失时,想直接从源码修改导出的模型时采用的方法。
- Unsqueeze节点:view操作时,使用int
# yolo.py
class Detect(nn.Module):
......
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
# bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
bs, _, ny, nx = map(int, x[i].shape) # 修改后的代码
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
- reshape 应该是只有batch是-1,其余维度是给定值。
# yolo.py
class Detect(nn.Module):
......
def forward(self, x):
......
# z.append(y.view(bs, -1, self.no))
z.append(y.view(-1, self.na*ny*nx, self.no)) # 修改后的代码
return x if self.training else (torch.cat(z, 1), x)
- Expand节点:make_grid造成的
def _make_grid(self, nx=20, ny=20, i=0):
d = self.anchors[i].device
yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)])
grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()
anchor_grid = (self.anchors[i].clone() * self.stride[i]) \
.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()
return grid, anchor_grid
make_grid 引用了 anchors、stride 这些常量,ONNX跟踪了这些常量, 直接存储成常量就行了嘛,不要去跟踪。
修改意见:
anchor_grid 必须让其断开连接,该怎么做呢???
# yolo.py
class Detect(nn.Module):
......
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = map(int, x[i].shape) # x(bs,255,20,20) to x(bs,3,20,20,85)
bs = -1
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
anchor_grid = (self.anchors[i].clone() * self.stride[i]).view(1, -1, 1, 1, 2) # 断开连接
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * anchor_grid # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * anchor_grid # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
#z.append(y.view(bs, -1, self.no))
z.append(y.view(bs, self.na * ny * nx, self.no))
#return x if self.training else (torch.cat(z, 1), x)
return x if self.training else torch.cat(z, 1)
002-推理代码修改
1)配置文件修改
"mark_text_en": ["front_wear","front_no_wear","front_under_nose_wear","front_under_mouth_wear","front_unknown","side_wear","side_no_wear","side_under_nose_wear","side_under_mouth_wear","side_unknown","side_back_head_wear","side_back_head_no_wear","back_head","mask_front_wear","mask_front_under_nose_wear","mask_front_under_mouth_wear","mask_side_wear","mask_side_under_nose_wear","mask_side_under_mouth_wear","strap"],
"mark_text_zh": ["正面佩戴口罩包住鼻子","正面未佩戴口罩","正面佩戴口罩在鼻子下且在嘴巴上面","正面佩戴口罩在嘴巴下面","不能很明确知道正面是否佩戴口罩","侧面佩戴口罩包住鼻子","侧面未佩戴口罩","侧面佩戴口罩在鼻子下且在嘴巴上面","侧面佩戴口罩在嘴巴下面","不能很明确知道侧面是否佩戴口罩","带了口罩","没有戴口罩","背面人头","口罩包住鼻子","口罩在鼻子下且在嘴巴上面","口罩在嘴巴下面","口罩包住鼻子","口罩在鼻子下且在嘴巴上面","口罩在嘴巴下面","口罩的带子"],
修改文件 ev_sdk/src/Configuration.hpp:

std::map > targetRectTextMap = {
{"en",{"front_wear","front_no_wear","front_under_nose_wear","front_under_mouth_wear","front_unknown","side_wear","side_no_wear","side_under_nose_wear","side_under_mouth_wear","side_unknown","side_back_head_wear","side_back_head_no_wear","back_head","mask_front_wear","mask_front_under_nose_wear","mask_front_under_mouth_wear","mask_side_wear","mask_side_under_nose_wear","mask_side_under_mouth_wear","strap"}},
{"zh",{"正面佩戴口罩包住鼻子","正面未佩戴口罩","正面佩戴口罩在鼻子下且在嘴巴上面","正面佩戴口罩在嘴巴下面","不能很明确知道正面是否佩戴口罩","侧面佩戴口罩包住鼻子","侧面未佩戴口罩","侧面佩戴口罩在鼻子下且在嘴巴上面","侧面佩戴口罩在嘴巴下面","不能很明确知道侧面是否佩戴口罩","带了口罩","没有戴口罩","背面人头","口罩包住鼻子","口罩在鼻子下且在嘴巴上面","口罩在嘴巴下面","口罩包住鼻子","口罩在鼻子下且在嘴巴上面","口罩在嘴巴下面","口罩的带子"}}};// 检测目标框顶部文字
2)修改定义报警类型
// 修改,定义报警类型
std::vector alarmType = {1,2,3,6,7,8};
数组即为 需要报警的类 对应的类别号。
3)修改模型路径
对应文件 ev_sdk/src/SampleAlgorithm.cpp

mDetector->Init("/usr/local/ev_sdk/model/exp/weights/best.onnx", mConfig.algoConfig.thresh);
4)置信度修改
对应文件 ev_sdk/src/SampleDetector.cpp
runNms(DetObjs, 0.45); # 0.45为nms阈值

修改置信度阈值:config/algo_config.json 和 src/Configuration.hpp 中的 thresh
5)修改模型推理
src/SampleAlgorithm.cpp
修改报警逻辑,过滤出需要报警的目标:
// 过滤出有效目标
for (auto &obj : detectedObjects)
{
for (auto &roiPolygon : mConfig.currentROIOrigPolygons)
{
int mid_x = (obj.x1 + obj.x2) / 2;
int mid_y = (obj.y1 + obj.y2) / 2;
// 当检测的目标的中心点在ROI内的话,就视为闯入ROI的有效目标
if (WKTParser::inPolygon(roiPolygon, cv::Point(mid_x, mid_y)) &&
(find(mConfig.alarmType.begin(), mConfig.alarmType.end(), obj.label) != mConfig.alarmType.end()))
{
validTargets.emplace_back(obj);
}
}
}
003-测试
输入单张图片,需要指定输入输出文件:
/usr/local/ev_sdk/bin/test-ji-api -f 1 -i /project/inputs/mask.jpg -o /project/outputsresult.jpg
004-算法提交精度过低的问题
1)第一次不通过:精度过低
问题分析:测试目标理解错误,我以为算法提交,需要过滤掉所有不是报警类别的目标。所以导致除了报警的6个类别外,precision和recall都是0。
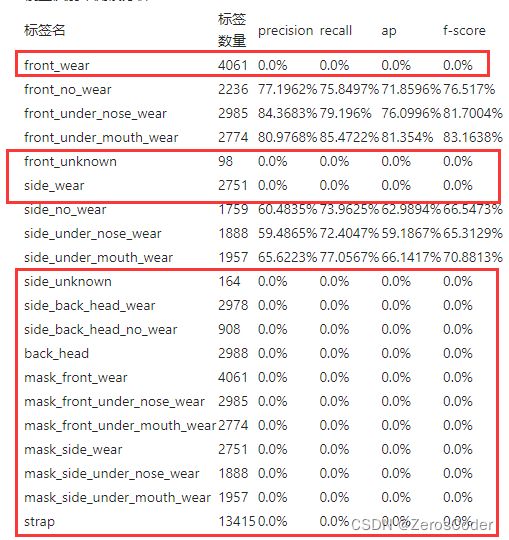
2)第二次不通过:精度过低

分析测试日志,可以看出算法精度低主要在两个方面:
-
front_unknown和side_unknown,这两类的precision和recall都是0。去查看了以下业务测试里的这两类的ap,发现也都是0 。那么这个问题就是模型训练的问题,统计了以下数据中各类别的个数,主要是这两个类别数目太少的问题,需要在模型训练中调整,这里就先暂且放下,待以后解决:
{'front_wear': 17064, 'front_no_wear': 9149, 'side_wear': 11476, 'back_head': 11713, 'mask_front_wear': 17064, 'mask_side_wear': 11476, 'strap': 54588, 'side_under_mouth_wear': 7893, 'side_back_head_wear': 10954, 'mask_side_under_mouth_wear': 7893, 'side_no_wear': 7540, 'front_under_nose_wear': 11130, 'mask_front_under_nose_wear': 11130, 'front_under_mouth_wear': 9555, 'mask_front_under_mouth_wear': 9555, 'side_under_nose_wear': 9081, 'mask_side_under_nose_wear': 9081, 'side_back_head_no_wear': 3466, 'side_unknown': 699, 'front_unknown': 250}

- mask_front_wear、mask_front_under_nose_wear、mask_front_under_mouth_wear、mask_side_wear、mask_side_under_nose_wear、mask_side_under_mouth_wear 这几类的recall较模型开发中测试结果严重偏低。
到了这个问题,我第一个考虑的出现的问题是:模型导出的问题??
- 对torch、onnx模型的输出结果进行比较,发现,两者输出结果之间 MSE 仅仅为 e-5 级别,那么就应该不是torch导出onnx的问题。
- 对onnx、tensorrt模型的输出结果进行比较,两者之间的 $MSE \in (5,8) $ ,虽说损失不小,但也不至于只有后面几个类别出现问题呀。
到了这里,已经是没辙了。仔细分析了下问题所在:只有这几类出现问题。那么我手动添加的参数中涉及了这几类的地方在哪呢?
想到这,我就想到了问题的真正所在:配置!!!
"mark_text_en": ["front_wear","front_no_wear","front_under_nose_wear","front_under_mouth_wear","front_unknown","side_wear","side_no_wear","side_under_nose_wear","side_under_mouth_wear","side_unknown","side_back_head_wear","side_back_head_no_wear","back_head","mask_front_wear","mask_front_under_nose_wear","mask_front_under_mouth_wear","mask_side_wear","mask_side_under_nose_wear","mask_side_under_mouth_wear","strap"],
"mark_text_zh": ["正面佩戴口罩包住鼻子","正面未佩戴口罩","正面佩戴口罩在鼻子下且在嘴巴上面","正面佩戴口罩在嘴巴下面","不能很明确知道正面是否佩戴口罩","侧面佩戴口罩包住鼻子","侧面未佩戴口罩","侧面佩戴口罩在鼻子下且在嘴巴上面","侧面佩戴口罩在嘴巴下面","不能很明确知道侧面是否佩戴口罩","带了口罩","没有戴口罩","背面人头","口罩包住鼻子","口罩在鼻子下且在嘴巴上面","口罩在嘴巴下面","口罩包住鼻子","口罩在鼻子下且在嘴巴上面","口罩在嘴巴下面","口罩的带子"],
"draw_warning_text": true,
问题就出现在这里了,class name 有几个填写错误了,真是被自己蠢死了。将这几类重新仔仔细细的填写了一遍,再提交测试,竟然过了 !!!!!