[一起学BERT](一):BERT模型的原理基础
Self-Attention机制理论
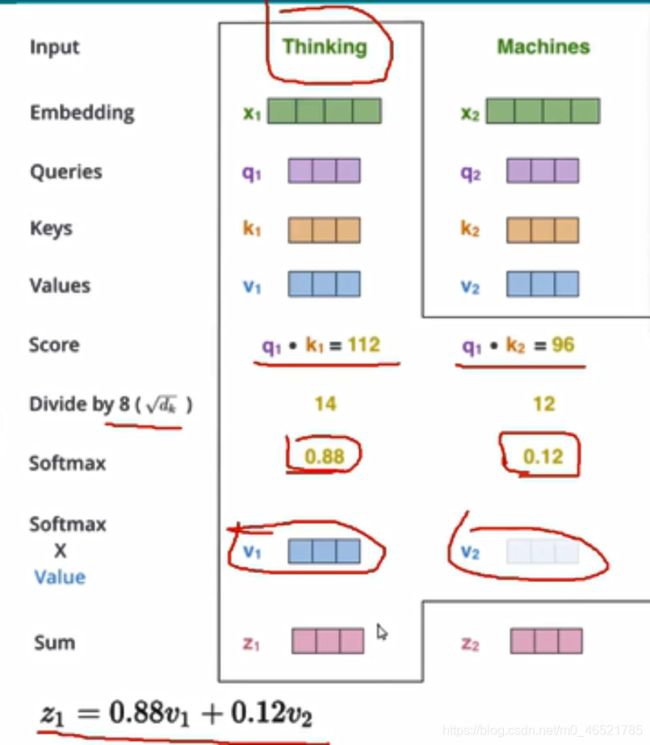
①首先将x1、x2两个词进行编码得到向量
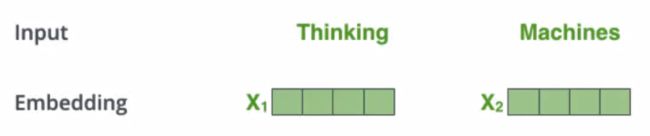
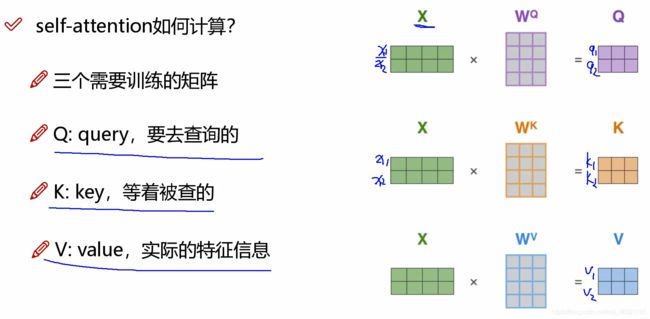
②编码后的向量乘以对应的权重矩阵,得到每个词的三个特征矩阵Q、K、V
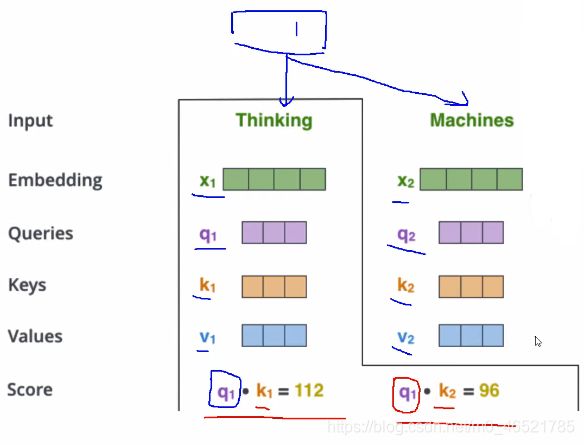
③计算第一个词的时候通过q1*k1、q1*k2、q1*k3…q1*kn得到当前次对于每个词的分值。因为两个词距离越近关系越大,点乘的结果也就越大
④最终的value计算
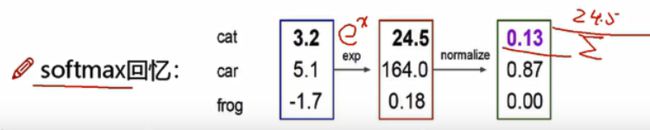
softmax计算流程
分值->e^x->归一化
归一化之后再乘以V矩阵,然后再相加:

为什么要除以根号d呢?如果不除以结果意思就是点乘结果越大就表示影响程度越大,明显是不合理的,应该是距离越近影响程度越大
⑤整体回顾
怎么做到并行化运算呢?因为全程运算都是基于矩阵的,原理如下,V矩阵乘以Q矩阵得到A矩阵,按后进行softmax,然后再和V矩阵做乘法
:BERT模型的原理基础_第1张图片](http://img.e-com-net.com/image/info8/3a8cc7f8feea42bf9af4cfd35f6b9bde.jpg)
:BERT模型的原理基础_第2张图片](http://img.e-com-net.com/image/info8/236b1e8227b745f790413ff53417c551.jpg)
Multi-head Self-Attention注意力机制
多头注意力机制就是多了几组Q、K、V,然后得到多个最后结果,最后通过全连接层对最后结果降维,得到最终结果。
多头一般是偶数个,一般最多为8个
:BERT模型的原理基础_第3张图片](http://img.e-com-net.com/image/info8/2add3733f87946798c932ef37b701491.jpg)
原理图如下
:BERT模型的原理基础_第4张图片](http://img.e-com-net.com/image/info8/bfb73c91c8194bb2a59502a3686d4ba3.jpg)
位置编码
在self-attention中每个词都会考虑整个序列的加权,所以其出现位置并不会对结果产生什么影响,相当于放哪都无所谓,
但是这跟实际就有些不符合了,我们希望模型能对位置有额外的认识,即位置不一样,词的重要程度也是不同的,因此要添加位置编码信息。
如下图的POSTRION ENCODING部分,添加位置编码方式很多,常用的就是Onehot,除此之外还可以使用正弦余弦
:BERT模型的原理基础_第5张图片](http://img.e-com-net.com/image/info8/ac3f7e0f92c0402aae1091afdc40d296.jpg)
Transformer理论
encoder-decoder attention,最后的值不光基于decoder,也基于编码器的信息

归一化
下图所示,self-attention之后呢,有一个LayerNorm归一化,但是,什么叫对层进行归一化??
LayerNorm就是没有Batch概念了,对他的一组数据,使得均值为0,平方差为1。

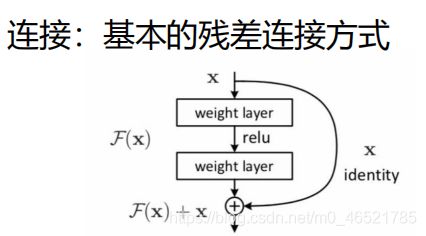
残差连接
虚线部分是连接,用的是基本的残差连接方式,得到两个数据,模型自己去选择,至少不比原来差
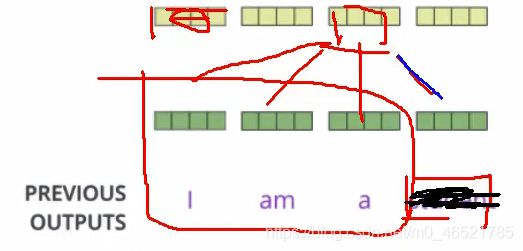
MASK机制
在encoder端,一个词在哪都能被知道,但是decoder一次只能得到一个结果,一个接一个出答案,后面词的信息无法得知
比如使用机器翻译,当前词无法使用后面词的信息,但是又不得不考虑,因此我们引入MASK机制,前面有的我们就能用,后面没有的我们就是当做黑盒子。
最终输出结果
就是得到一个分类,经过Softmax层即可

BERT理论
BERT是Bidirectional Encoder Representations from Transformers的首字母缩写,整体是自编码语言模型,相当于Transformer模型的Encoder部分
-
将文字送入BERT之后会出一个向量,我们直接拿来用就好了
-
在BERT后面接一个模型做分类任务
-
除此之外,经过BERT得到的结果也可以进行微调
-
每一个词的向量可以根据语义得到,而不是固定的,例如:我喜欢吃苹果和苹果公司很厉害中的苹果一词在两句话中的词向量就不应该相同
-
BERT限制了最长句子,为512长度
-
在BERT中激活函数使用的是
gelu而不是relu
:BERT模型的原理基础_第6张图片](http://img.e-com-net.com/image/info8/7bf2a50498b04914a2a6f9c47e698c60.jpg)
下面有一个代码demo将中文转为Tensor
先pip执行这段代码,再看少什么包再安装
pip install tqdm boto3 requests regex sentencepiece sacremoses
模型部分
根据torch版本不同,可能在return的时候需要微调
# 我的torch版本是1.4
import torch
import torch.nn as nn
# 导入bert的模型
model = torch.hub.load('huggingface/pytorch-transformers', 'model', 'bert-base-chinese')
# 导入字符映射器
tokenizer = torch.hub.load('huggingface/pytorch-transformers', 'tokenizer', 'bert-base-chinese')
def get_bert_encode_for_single(text):
"""
功能: 使用bert-chinese预训练模型对中文文本进行编码
text: 要进行编码的中文文本
return : 编码后的张量
"""
# 首先使用字符映射器对每个汉字进行映射
# bert中的tokenizer映射后会加入开始和结束的标记, 101, 102, 这两个标记对我们不需要,采用切片的方式去除
indexed_tokens = tokenizer.encode(text)[1:-1]
# 封装成tensor张量
tokens_tensor = torch.tensor([indexed_tokens])
# print(tokens_tensor)
# 预测部分需要使得模型不自动求导
with torch.no_grad():
data = model(tokens_tensor)
# _,encoded_layers = model(tokens_tensor)
# print(encoded_layers.shape)
# 模型的输出都是三维张量,第一维是1,使用[0]来进行降维,只提取我们需要的后两个维度的张量
# encoded_layers = encoded_layers[0]
# return encoded_layers
return data[0][0]
if __name__ == '__main__':
text = "你好,周杰伦"
outputs = get_bert_encode_for_single(text)
print(outputs)
print(outputs.shape)
最后输出的形式
tensor([[ 3.2731e-01, -1.4832e-01, -9.1618e-01, ..., -4.4088e-01,
-4.1074e-01, -7.5570e-01],
[-1.1287e-01, -7.6269e-01, -6.4861e-01, ..., -8.0478e-01,
-5.3600e-01, -3.1953e-01],
[-9.3013e-02, -4.4381e-01, -1.1985e+00, ..., -3.6624e-01,
-4.7467e-01, -2.6408e-01],
[-1.6896e-02, -4.3753e-01, -3.6060e-01, ..., -3.2451e-01,
-3.4205e-02, -1.7930e-01],
[-1.3159e-01, -3.0048e-01, -2.4193e-01, ..., -4.5756e-02,
-2.0958e-01, -1.0649e-01],
[-4.0006e-01, -3.4410e-01, -3.7454e-05, ..., 1.9081e-01,
1.7006e-01, -3.6221e-01]])
torch.Size([6, 768])