Pyramid Vision Transformer(PVT): 纯Transformer设计,用于密集预测的通用backbone
论文地址:https://arxiv.org/pdf/2102.12122.pdf
官方代码:https://github.com/whai362/PVT
目录
0、摘要
1、引言
2、相关工作
2.1、CV中的CNN backbone
2.2 密集预测任务
2.3、自注意力和视觉Transformer
3、金字塔视觉Transformer(PVT)
3.1、总体架构
3.2、Transformer特征金字塔
3.3、Transformer Encoder
3.4、更多细节
3.5、讨论
4、将PVT应用于下游任务
4.1、图像级预测
4.2、像素级密集预测
5、实验结果
6、总结
0、摘要
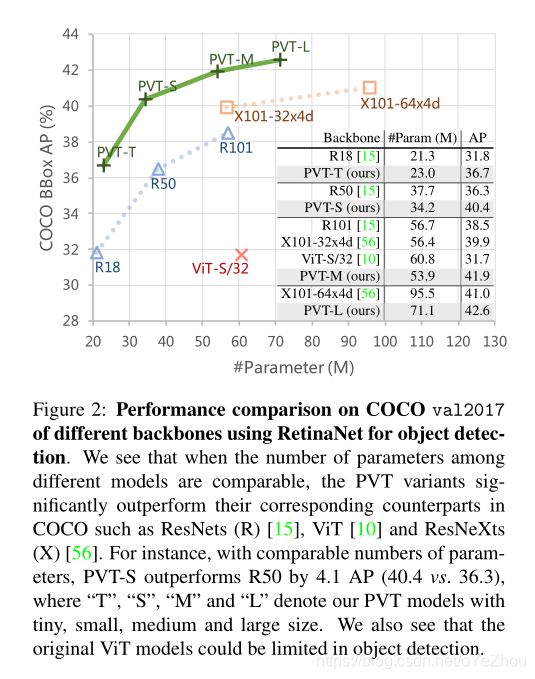
尽管基于CNNs的backbone在多种视觉任务中取得重大进展,但本文提出了一个用于密集预测任务的、无CNN的的简单backbone——Pyramid Vision Transformer(PVT)。相比于ViT专门用于图像分类的设计,PVT将金字塔结构引入到transformer,使得可以进行下游各种密集预测任务,如检测、分割等。与现有技术相比,PVT有如下优点:(1)相比于ViT的低分辨率输出、高计算复杂度、高内存占用,PVT不仅可以对图像进行密集划分训练以达到搞输出分辨率的效果(这对密集预测很重要),还可以使用一个逐渐缩小的金字塔来降低大feature maps的计算量;(2)PVT兼具了CNNs和Transformer的优点,使其成为一个通用的无卷积backbone,可以直接替换基于CNN的backbone;(3)大量实验表明,PVT可以提高多种下游任务的性能,如目标检测、语义/实例分割等。比如,参数量相当的情况下, RetinaNet+PVT可以在COCO上达到40.4AP,而RetinNet+ResNet50只有36.3AP。作者希望PVT能够成为像素级预测任务的一种可供选择的backbone,并促进后续的研究。
1、引言
一直以来,以CNNs作为backbone,使得各类计算机视觉任务得到长足发展。本文的目的是探索无CNN的通用backbone,为下游密集预测任务提供多一个选择。
受NLP领域的启发,一些研究尝试基于Transformer进行计算机视觉任务,如ViT、DETR、SETR、 Deformable detr、Transtrack等。
ViT是首次利用transformer替代CNNbackbone进行图像分类的工作,如图1(b)所示,其backbone为柱状结构,输入为一组粗糙的图像patchs。
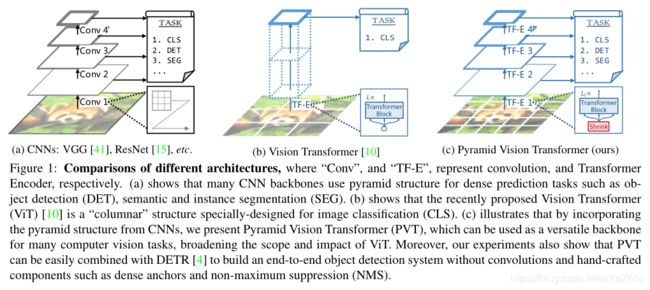
尽管ViT在图像分类上得以应用,但在密集的像素级预测任务(如目标检测、分割等)上却并不适合使用,主要原因有:
(1)其输出分辨率比较低,且只有一个单一尺度,输出步幅为32或者16;
(2)输入尺寸即使增大一点,也会造成计算复杂度和内存消耗的大幅增加。
为了解决ViT的上述缺陷,本文提出了金字塔视觉Transformer(Pyramid Vision Transformer,PVT),可以作为密集预测任务的backbone来使用,相比ViT,PVT主要克服了以下难点:
(1)使用了细粒度的图像patch(如:每个patch大小为4*4)作为输入,来学习高分辨率的特征表示,而这对密集预测任务来说比较重要;
(2)引入一种逐级收缩的金字塔,随着网络深度增加,逐渐减小Transformer的序列长度,显著降低了计算量;
(3)使用空间缩减注意力(SRA)层来进一步降低学习高分辨率表示的资源消耗。
总体来说,PVT的优点有:
(1)传统CNN backbone的感受野随着深度增加而逐渐增大,而PVT始终保持全局感受野(受益于Transformer中的自注意力机制,在所有patchs中执行注意力),这对检测、分割任务更为合适;
(2)相比ViT,引入了金字塔结构的PVT可以嵌入到很多经典的piplines中,如RetinaNet、Mask-RCNN等;
(3)可以和其他Transformer Decoder结合,组成无卷积的框架,如PVT+DETR进行端到端目标检测。
PVT和其他backbone的对比如图2所示:
2、相关工作
2.1、CV中的CNN backbone
众所周知,CV深度学习主要是靠着CNN撑起来的,其首次应用在LeNet手写数字识别上。卷积块使用一个具有一定感受野的卷积核捕获局部的上下文信息,而为了引入平移等变性,卷积核的参数是共享的。随着硬件(如:GPU)的快速发展,使得在大规模数据集ImageNet上进行训练成为了可能,各种CNN分类模型层出不穷:GoogleNet、Inception系列、ResNeXt、DPN、MixNet、SKNet、ResNet、DenseNet,这些网络也引入了一些新概念,如多卷积核路径、跳跃连接、密集连接等。
2.2 密集预测任务
密集预测任务的目的是在feature map上对每个像素进行分类或者回归,主要有两种:目标检测、语义分割。
目标检测:
在深度学习时代,目标检测框架已被各种CNN模型所垄断,如一阶段的SSD、RetinaNet、FCOS、GFL、PolarMask、OneNet等,以及多阶段的Faster RCNN、Mask RCNN、Cascade RCNN、Sparse RCNN等。这些检测器大多是通过构建高分辨率、多尺度的feature map来获取高性能,而近期的DETR和可变性DETR确实结合CNNbackbone和Transformer decoder来构建一个端到端的目标检测器。DERT与那些基于CNN的detector一样,都需要高分辨率或者多尺度的feature map进行精准检测。
语义分割:
CNN在语义分割领域同样举足轻重,从早期的FCN将CNN引入语义分割开始,U-Net利用Encoder-Decoder结构对高低级特征进行了融合,从而在医学图像分割上取得良好的效果。后面为了进一步获取丰富的全局上下文,PSPNet提出了金字塔池化模块PPM、DeepLab系列则使用空洞卷积来增大卷积的感受野。与目标检测相似,语义分割同样依赖于高分辨率的feature map或者多尺度。
2.3、自注意力和视觉Transformer
由于卷积核的权重在训练之后是固定不变的,所以它对输入的变化难以适应,因此有些基于自注意力的方法被提出来缓解这个问题。比如:经典的Non-local,其试图对时域、空域中的长距离依赖进行建模,对视频分类的准确率有所提升;CCNet提出的交叉注意力则是为了降低Non-local中的计算量;而stand-alone自注意力的提出则试图用局部自注意力单元替代卷积层;AAnet则结合了自注意力和卷积操作;DETR利用Transformer decoder将目标检测建模为端到端的字典查询问题,成功移除了NMS等后处理;基于DETR,deformable DETR进一步引入了可变形注意力层,专注于上下文元素的稀疏集,从而使得收敛更快且性能更优。近期,ViT使用纯Transformer构建了一个图像分类模型,其将一组patchs作为图像输入;DeiT通过一种新颖的蒸馏方法进一步扩展了ViT。与这些方法不同的是,PVT尝试将金字塔结构引入Transformer,并设计一个纯Transformer的backbone,用于密集预测任务。
3、金字塔视觉Transformer(PVT)
3.1、总体架构
PVT的整体网络结构如图3所示:

PVT的目的是在Transformer中引入特征金字塔,因此可以生成多尺度的feature maps用于密集预测任务。与CNN的backbone相似,PVT也有四个stage,每个stage生成不同尺度的feature maps,且每个stage结构相似,都由patch embedding 层和 个Transformer Encoder层组成。
个Transformer Encoder层组成。
在第一个stage,输入图像的尺寸为![]() ,首先将其分解为
,首先将其分解为![]() 个patchs,每个patch大小为4*4*3。然后,将这些patchs拉直,进行线性投影得到嵌入后的patchs,其尺寸为
个patchs,每个patch大小为4*4*3。然后,将这些patchs拉直,进行线性投影得到嵌入后的patchs,其尺寸为![]() 。接着,将嵌入后的patchs和位置嵌入一同送到一个
。接着,将嵌入后的patchs和位置嵌入一同送到一个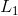 层的Transformer Encoder,将输出reshape后得到
层的Transformer Encoder,将输出reshape后得到 ,尺寸为
,尺寸为![]() 。
。
按照与第一个stage相似的方式,可以得到stage2~4的输出![]() ,其输出步幅分别为8,16,32。于是便得到了特征金字塔
,其输出步幅分别为8,16,32。于是便得到了特征金字塔![]() ,其可以轻松用于各种下游任务,如分类、检测、分割等。
,其可以轻松用于各种下游任务,如分类、检测、分割等。
3.2、Transformer特征金字塔
与CNN的backbone通过带有步长的卷积获取多尺度feature maps不同,PVT通过patch嵌入层使用渐进缩减策略来控制feature maps的尺寸。
定义第i个stage的patch尺寸为 。在stage i的起始阶段,首先将输入feature map
。在stage i的起始阶段,首先将输入feature map ![]() 分解为
分解为![]() 个patchs,然后将每个patch拉直并投影到
个patchs,然后将每个patch拉直并投影到 维。经过线性投影后,嵌入的patch尺寸为
维。经过线性投影后,嵌入的patch尺寸为![]() ,其中宽和高均比输入小倍。
,其中宽和高均比输入小倍。
按照这种方式,即可在每个stage灵活调整feature map的尺寸,使其可以构造Transformer的特征金字塔。
3.3、Transformer Encoder
针对stage i,其中的Transformer Encoder具有个Encoder层,每个Encoder层由注意力层和前馈层组成。由于所提出的PVT需要处理高分辨率的feature maps(如:4步长),因此提出了一个空间缩减注意力(SRA)层,替代传统的多头注意力(MHA)层。
与MHA相似,所提出的SRA同样接受query Q、key K、value V作为输入,不同之处在于SRA将K和V的宽高分别降低为原来的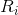 倍,如图4所示:
倍,如图4所示:

SRA的公式表示如下:
![]() (1)
(1)
![]() (2)
(2)
其中,为线性投影的参数,
 为stage i中Transformer Encoder的个数。因此,每个head
为stage i中Transformer Encoder的个数。因此,每个head ![]() 的维度为
的维度为![]() 。SR(·)是空间缩减操作,其定义为:
。SR(·)是空间缩减操作,其定义为:
![]() (3)
(3)
其中,代表stage i中注意力层的缩减率,![]() 操作用于将输入
操作用于将输入![]() reshape到
reshape到![]() ,
,![]() 为对输入进行降维的线性投影,Norm(·)为层归一化。Attention(·)则与Transformer一致,为:
为对输入进行降维的线性投影,Norm(·)为层归一化。Attention(·)则与Transformer一致,为:
![]() (4)
(4)
通过上述公式可以看出,Attention(·)模块的计算复杂度和内存消耗是NHA中的![]() ,因此就可以在有限的资源下处理更大的feature maps/sequences。
,因此就可以在有限的资源下处理更大的feature maps/sequences。
3.4、更多细节
PVT模型的超参主要有:
- :stage i中的patch大小;
- :stage i的输出通道数;
- :stage i中Encoder层数;
- :stage i中SRA的缩减率;
- :stage i中SRA的head个数;
 :stage i中前馈层的扩张率;
:stage i中前馈层的扩张率;
PVT遵循了ResNet的设计理念:(1)在浅层stage中的输出通道较小;(2)计算主要集中在中间stage。
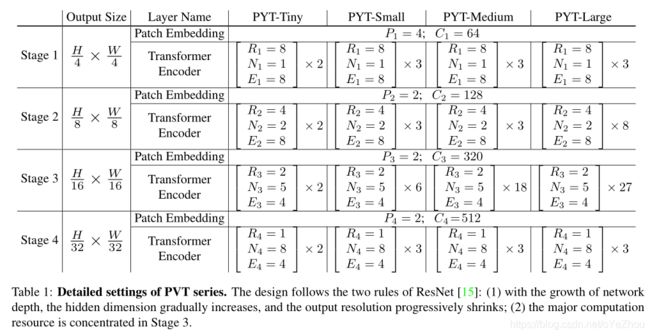
作者设计了一系列的PVT模型,分别为PVT-Tiny,PVT_Small,PVT_Large,详见表1:
3.5、讨论
与本作最为相关的工作是ViT,这里主要讨论下两者之间的异同。
PVT和ViT都是纯Transformer的模型,没有任何卷积操作,而两者主要的不同在于PVT引入了特征金字塔结构。在ViT中,使用的是传统Transformer,其输入与输出尺寸相同,就如图1(b)所示,为筒状结构。由于资源限制,ViT的输出只能是一个比较粗糙的feature map,如16*16、32*32,相应的其输出步幅也比较低,如16步长、32步长。结果就导致ViT很难直接用于那些对分辨率要求比较高的密集预测任务。
PVT通过引入渐进缩减金字塔打破了Transformer的这种限制,可以像传统CNN backbone那样生成多尺度feature map。此外,还设计了一个简单有效的注意力层——SRA,来处理高分辨率feature maps并减低计算复杂度和内存消耗。
因此,总的来说,PVT相比ViT有如下优势:
- (1)更加灵活:可以在不同的stage生成不同分辨率、通道的feature maps;
- (2)更加通用:可以轻松嵌入到大多下游任务的模型中;
- (3)对计算、内存更加友好:可以处理高分辨率的feature maps;
4、将PVT应用于下游任务
4.1、图像级预测
图像分类时图像级预测的代表任务。按照ViT和DeiT的做法,PVT给每个stage的输入额外增加了一个可学习的分类token,然后使用一个全连接层在分类token的顶部进行分类。
4.2、像素级密集预测
密集预测任务要求在feature map上执行像素级分类或者回归,这里主要讨论目标检测、语义分割。
目标检测:
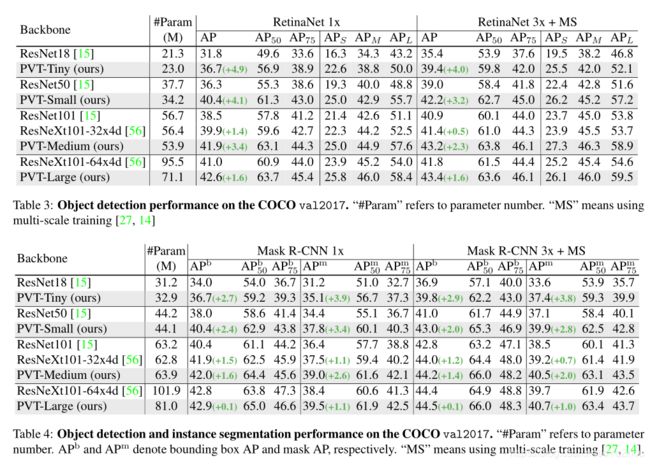
作者在两个目标检测框架上应用了PVT:RetinaNet、Mask RCNN,分别是常用的一阶段目标检测器、主流的两阶段实例分割框架。
实现细节包括:(1)类似与ResNet,这里直接使用PVT各stage的输出![]() 作为FPN的输入,然后将细化的feature maps送到后续的检测或者实例分割head中。(2)在目标检测中,输入可以为任意尺寸,所以在ImageNet上预训练位置嵌入将变得无意义;因此,这里根据输入图像的大小,对预训练的位置嵌入进行双线性插值。(3)在训练检测模型时,PVT中所有层都不冻结,也即所有权重都参与更新。
作为FPN的输入,然后将细化的feature maps送到后续的检测或者实例分割head中。(2)在目标检测中,输入可以为任意尺寸,所以在ImageNet上预训练位置嵌入将变得无意义;因此,这里根据输入图像的大小,对预训练的位置嵌入进行双线性插值。(3)在训练检测模型时,PVT中所有层都不冻结,也即所有权重都参与更新。
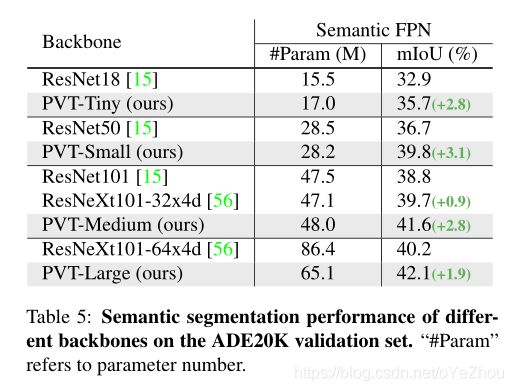
语义分割:
这里选择语义FPN作为baseline,其属于一种没有特殊操作的简单分割方法,这样可以更好地观察backbone所带来的的收益。类似于目标检测,这里也是直接使用特征金字塔的输出作为语义FPN的输入,并对预训练的位置嵌入使用双线性插值。
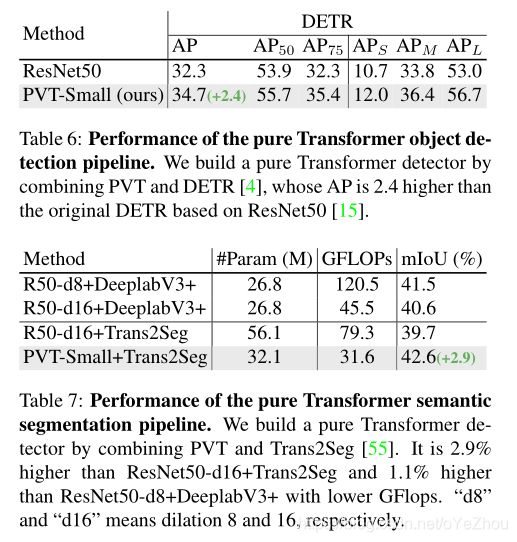
5、实验结果

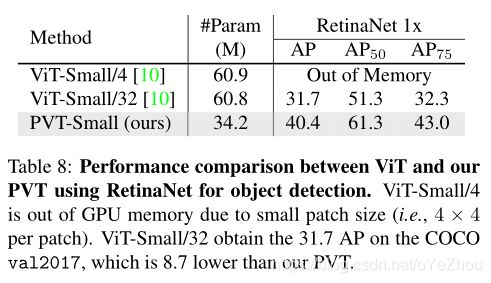


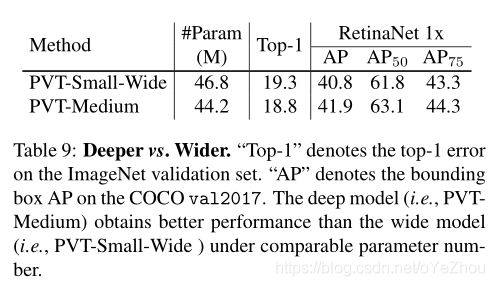
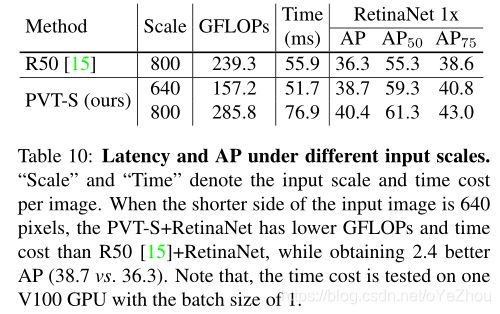
6、总结
本文主要提出了一个纯Transformer的模型——PVT,可以作为下游密集预测的backbone使用。还设计了一个渐进缩减金字塔和一个空间缩减注意力层,在有限的资源下获取多尺度的、更高分辨率的输出。大量实验表明,PVT比一些设计良好的CNN backbone效果更好。
尽管PVT可以作为替代CNN backbone的一个选择,但是那些专门针对CNN设计的一些模块却不能用到PVT中,如SE、SK、空洞卷积、NAS等。此外,经过多年发展,CNN backbone也有很多优秀的设计,如Res2Net、EfficientNet、ResNeSt等。与之相反,在CV领域基于Transformer的模型研究仍处于初级阶段,这还需要未来持续不断的研究。