Bert用在seq2seq任务上——UNILM实战
文章目录
- 1.UNILM简介
- 2.实战
-
- 2.0 租服务器
-
- 2.0.1 基础配置
- 2.0.2 网络和安全组
- 2.0.3 系统配置
- 2.0.4 服务器的状态
- 2.0.5 查看账单
- 2.1 环境配置
-
- 2.1.0 登录服务器
- 2.1.1 安装torch
- 2.1.2 配置 UNILM 要求的包
- 2.2 训练
- 2.3 验证
- 3.结语
1.UNILM简介
按照我粗浅的理解:
-
传统的seq2seq模型需要用一个encoder把输入的语料处理成向量,一个decoder把向量转换为词表里的词,生成目标语句。
-
Bert是一个预训练好的语言模型,有三层嵌入信息,能够很好的对输入语料进行建模。
我刚学习完Bert和传统的seq2seq时,就在想: 如果能够把Bert运用在seq2seq模型,那么或许能够得到更好的生成效果。
果然,早就有人实现了这个想法,并取名为UNILM,其实现过程是:改变训练Bert的方式,采用特定的顺序遮挡attention矩阵去训练,相当于是训练seq2seq模型。
详细的原理介绍可以看: Unilm模型的摘要任务原理解释 和 苏剑林老师针对中文UNILM的博客
总之,UNILM把Bert运用在seq2seq模型上,从而使得模型可以用于NLG(文本生成)。
2.实战
租服务器的这天是2020欧冠决赛,由于主队利物浦已经被淘汰了,我本不打算看凌晨3点的决赛的,没想到出了种种状况,导致我到凌晨3点才刚好调试完服务器环境,开始用数据训练微调UNILM模型。所以,我就边看比赛边等着它训练完,十分舒适。
2.0 租服务器
进入阿里云官网。
登录(支付宝、淘宝账户均可登录)并先预充一百元。
2.0.1 基础配置
登录后,点官网上方栏的控制台,再点左侧栏的云服务器 ECS,点页面中央的创建我的ECS
这样就进入了选择服务器规格的页面了,如下图。

(1) 付费模式
除了包年包月,我们还可以选择“按量付费”或者“抢占式实例”。按量付费是以小时为单位进行计费,计算完毕后需手动释放服务器以停止计费。“抢占式实例”也是按小时计费,价格随市场波动,出价高的一批用户获得GPU服务器的使用权。
由于我们的训练任务不用花很久时间,所以我采用的是“按量付费“。
(2) 地域及可用区
这个我选的是华北5(呼和浩特),其实选哪里都无所谓的,有的地区有优惠。
(3) 实例
服务器规格搜索并选择“ecs.gn5-c8g1.2xlarge”,该规格有8个vCPU,60G内存,一块P100 GPU,440G存储空间(暂时存储),Intel Xeon E5-2682v4 CPU。配置足以满足绝大部分任务的需求了。
(4) 镜像
Ubuntu16.04系统支持“自动安装GPU驱动”(推荐使用Ubuntu16.04,遇到的坑会少一点),可免去之后安装GPU驱动的步骤。
由于微软在github上发布的UNILM对于pytorch和cuda的版本要求是:
pytorch:1.2-cuda10.0-cudnn7
此外,UNILM要用到NVIDIA/apex,它又要求cuda版本要在10.1以上
所以,我尝试安装过几种cuda版本,最后发现下面这样选镜像配置是可以正常运行UNILM的
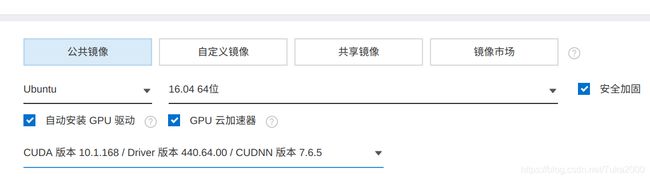
即选择:
自动安装 GPU 驱动
GPU 云加速器
CUDA 版本 10.1.168 / Driver 版本 440.64.00 / CUDNN 版本 7.6.5
(5)存储
不更改存储设置
完成上述配置后,点击“下一步:网络和安全组”。该界面,我们不做任何更改。
2.0.2 网络和安全组
不更改网络设置
安全组默认也保持不变。确保22端口打开即可,我们之后会通过ssh的方式连接服务器。
点击“下一步:系统配置”。
2.0.3 系统配置
选“自定义密码”(记住该密码,当我们登录服务器时,登录名为root,密码为此处设置的密码)
完成后点击“确认订单”。
我们可以设置自动释放的时间**(谨慎操作,到达释放时间后,实例会被释放,数据及IP不会被保留)**若读者对自己的使用时间没有把握,不建议设置“使用时限”。
点击同意《云服务器 ECS 服务条款》服务协议。
之后我们即可点击**右下角的“创建实例”**了。创建实例之后即开始计费,直到我们手动停止服务为止。
这样就注册好了一个云服务器实例。
2.0.4 服务器的状态
进入服务器控制台。
点击管理,
当不用服务器的时候,一定记得要停止服务或者快照保存+释放实例。
从今年6月开始,停止服务仍然会继续收取CPU的费用,所以还是采用快照保存+释放实例的方式比较合理。
关于快照的操作,详见阿里云的快照文档
2.0.5 查看账单
登录阿里云官网后,点官网上方栏的控制台,再点上方栏的费用,再点左边栏的费用账单,在费用账单界面上方有三个选项,选账单,就可以看到所有的费用支出了,如下图。
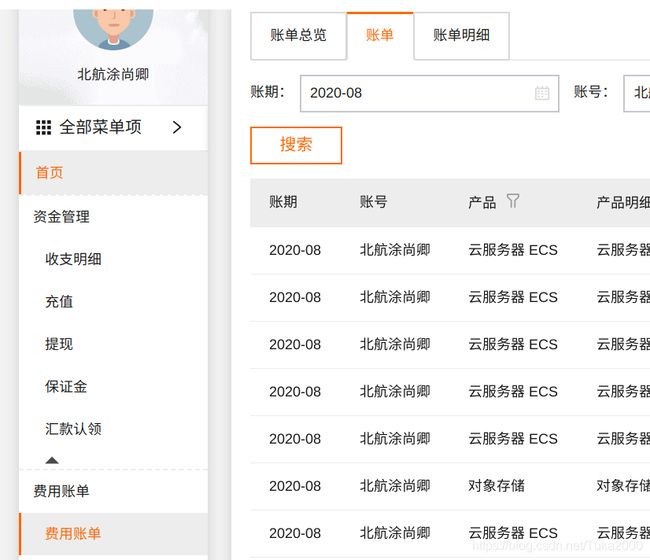
阿里云比较坑的一点是:他的扣费是延时扣的,可能你充了100元,一开始随意注册了3个多余的服务器实例,然后忘了释放了(即使停止服务了也会扣费,只有释放实例才不会继续扣费),可能在2个小时后才会发现自己突然被扣掉3个服务器2个小时的服务费。
而且就算欠费了,阿里云还是继续给你提供服务并扣钱,等你反应过来把多余的服务器关掉了,一看账单,有点头疼了。
所以,大家最好在下线前,检查一下自己的账单,预防忘记关掉多余服务器导致的扣费问题。
2.1 环境配置
2.1.0 登录服务器
登录后,点官网上方栏的控制台,再点左侧栏的云服务器 ECS,我们就可以看到我们正在运行的云服务器。记住我们服务器的公网IP地址,如下图。
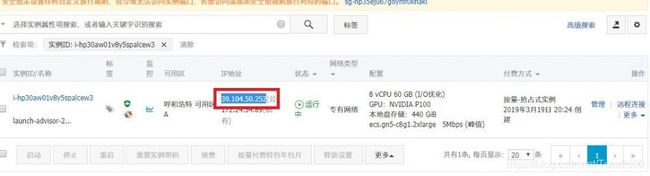
打开电脑本地的命令行终端(windows是cmd)
我们采用ssh登录服务器
输入的格式命令是
ssh -oPort=22 root@公网IP
所以这张图对应的登录命令就是
ssh -oPort=22 [email protected]
在电脑本地的命令行终端输入自己的公网IP对应的登录命令就可以登录服务器了。
登录成功显示如下:
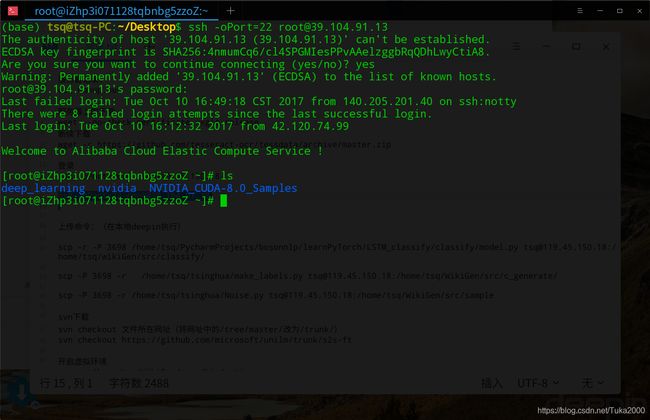
(这张图里我的CUDA是老版本的,后来跑程序的时候报错了,就不得不更新了…)
2.1.1 安装torch
刚登录的时候,由于我们在步骤2.0.1(4)里选择了自动安装GPU驱动,一般显示的是:
服务器正在下载cuda 和 一堆表示下载进度的##########################符号。
这个大概等10分钟就好了。
等他安装完成了,可能会强制你退出登录,这个时候重新登录一下。
由于阿里云已经帮我们预先安装好了pip。
所以,可以在登录后的终端输入
pip install torch
即可安装PyTorch,安装完成后:
输入python,进入python执行界面。在该界面下输入import torch ,不报错即代表安装成功。

2.1.2 配置 UNILM 要求的包
UNILM本身的预训练是我们无法去复现的,我们只需要根据官方给出的预训练好的模型,根据我们的下游任务的需求,用一些数据去训练UNILM来实现微调(fine-tuning),使得UNILM模型适应我们的任务要求。
我们采用的是微软在github根据UNILM发布的s2s-ft包,它一个PyTorch包,用于对预先训练好的UNILM进行微调,以便生成序列到序列的语句。项目地址
官网要求如下:
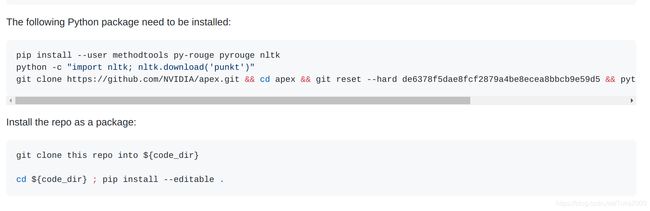
由于阿里云采用的是镜像源,安装这些包还比较快,但是毕竟是外网的包,应该没有直接从本地上传到服务器快吧。
我没试过直接在服务器上git clone要求的那2个包,不知道快不快,读者可以自己去官网试一下按它给的这几行安装命令去配置环境。
事实上,我走的安装之路比较奇怪,仅供参考:
-
在自己的笔记本电脑上建立一个文件夹叫UNILM
里面要下载好如下文件
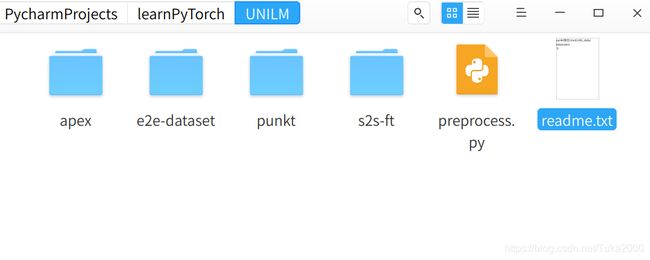
-
apex其实是官网的第三个要求,我们直接执行
git clone https://github.com/NVIDIA/apex.git -
e2e-dataset是我们的实验数据存放的地方,我采用的数据集是e2e餐馆评价的数据集,原始数据是csv格式的,需要自己处理成官网要求的json格式。
-
preprocess.py是我处理原始数据的文件(仅适用于e2e餐馆评价数据集),preprocess.py文件内容如下:
import os import pandas as pd import json def work(e2e_excel_path, save_path): for excelFile in os.listdir(e2e_excel_path): if excelFile[-3:] == "csv" and excelFile != "testset.csv": split = excelFile[:-4] excel_path = os.path.join(e2e_excel_path, excelFile) save_json_path = os.path.join(save_path, split + ".json") fout = open(save_json_path, "w") data = pd.read_table(excel_path, sep=",") lines = [] for i in range(len(data)): corpus = {} print(excelFile, i) src = data["mr"][i] tgt = data["ref"][i] corpus["src"] = src corpus["tgt"] = tgt json_str = json.dumps(corpus) lines.append(json_str + "\n") fout.writelines(lines) if __name__ == '__main__': e2e_excel_path = "/home/tsq/Downloads/ner/weigamg/data2text_template/e2e-dataset" save_path = "/home/tsq/PycharmProjects/learnPyTorch/UNILM/e2e-dataset" work(e2e_excel_path, save_path) -
punkt文件夹就是官网的第二个要求,我们直接执行
python -c "import nltk; nltk.download('punkt')"- 这样会下载punkt文件夹到笔记本的主目录下的一个叫nltk_data的文件夹下去,把punkt复制到UNILM文件夹下,方便等会上传
-
s2s-ft文件夹就是官网的第四个要求,需要我们从UNILM的github地址下载好s2s-ft文件夹,由于它是一个很大的github项目下面的一个单独的文件夹,我采用的是svn下载。在笔记本的UNILM文件夹下输入
svn checkout https://github.com/microsoft/unilm/trunk/s2s-ft-
下载好s2s-ft后,进入此文件夹,新建一个用来执行训练命令的脚本
train.sh。- 官网上给的命令是默认你有4块GPU集群训练的,我这里改成了单GPU。
- 避免爆内存,把
per_gpu_train_batch_size下降到了2。 - 然后
max_source_seq_length和max_target_seq_length是你输入和输出一个序列最长有多少个词,我这里是估摸着e2e数据集的长度设的,其实不太严谨。- 如果设置的太大,会拖慢训练速度。
- 设置的太小,会导致形成不了完整的句子。
- 需要注意的是
train.sh脚本里的OUTPUT_DIR和CACHE_DIR是要自己mkdir创建的
# path of training data TRAIN_FILE=/root/UNILM/e2e-dataset/trainset.json # folder used to save fine-tuned checkpoints OUTPUT_DIR=/root/UNILM/e2e-dataset/ckpt # folder used to cache package dependencies CACHE_DIR=/root/UNILM/s2s-ft/cache python run_seq2seq.py \ --train_file ${TRAIN_FILE} --output_dir ${OUTPUT_DIR} \ --model_type unilm --model_name_or_path unilm1.2-base-uncased \ --do_lower_case --fp16 --fp16_opt_level O2 --max_source_seq_length 64 --max_target_seq_length 64 \ --per_gpu_train_batch_size 2 --gradient_accumulation_steps 1 \ --learning_rate 7e-5 --num_warmup_steps 500 --num_training_steps 32000 --cache_dir ${CACHE_DIR} -
还是在s2s-ft文件夹,新建一个用来验证模型生成句子效果的脚本
valid.sh# path of the fine-tuned checkpoint MODEL_PATH=/root/UNILM/e2e-dataset/ckpt/ckpt-1500 SPLIT=validation # input file that you would like to decode INPUT_JSON=/root/UNILM/e2e-dataset/${SPLIT}.json export CUDA_VISIBLE_DEVICES=0 export OMP_NUM_THREADS=4 export MKL_NUM_THREADS=4 python decode_seq2seq.py \ --fp16 --model_type unilm --tokenizer_name unilm1.2-base-uncased --input_file ${INPUT_JSON} --split $SPLIT --do_lower_case \ --model_path ${MODEL_PATH} --max_tgt_length 64 --batch_size 2 --beam_size 5 \ --length_penalty 0 --forbid_duplicate_ngrams --mode s2s --forbid_ignore_word "."
-
-
最后一个文件readme.txt是提示我自己
punkt文件夹随UNILM上传之后放在服务器的/root/nltk_data/tokenizers 文件夹下(此目录需要自己mkdir) -
scp上传
scp是一个可以用来从本地电脑上传文件到指定服务的命令
上传的时候一定要在本地电脑的终端运行执行这些scp命令
不要在服务器端运行下面的命令哦 QAQ
scp -P 22 -r 你的笔记本UNILM文件夹的地址 root@你的公网IP:/root/比如我的命令是
scp -P 22 -r /home/tsq/PycharmProjects/learnPyTorch/UNILM [email protected]:/root/这样我们就能够把本地的UNILM上传到服务器的根目录下了 !
-
登录服务器,就会发现/root目录下,多了一个UNILM文件夹,下面的命令都是在服务器上执行的
-
新建一个nltk_data文件夹,nltk_data文件夹下面建一个tokenizers文件夹,把下载好的punkt文件夹从/root/UNILM复制到/root/nltk_data/tokenizers
-
运行
-
pip install --user methodtools py-rouge pyrouge nltk
-
-
在apex文件夹运行:
-
git reset --hard de6378f5dae8fcf2879a4be8ecea8bbcb9e59d5 && python setup.py install --cuda_ext --cpp_ext -
会出现一些warning,最后显示:
-
Installed /root/miniconda/envs/tf2.1_cu10.1_py36/lib/python3.6/site-packages/apex-0.1-py3.6-linux-x86_64.egg Processing dependencies for apex==0.1 Finished processing dependencies for apex==0.1
-
-
在s2s-ft文件夹运行:
-
pip install --editable .
如果走完了这一步,恭喜!你成功配置好了环境!
接下来就可以开始训练模型咯!
-
2.2 训练
登录服务器
进入/root/UNILM/s2s-ft/ 文件夹
命令行输入
bash train.sh
即可开始训练
正常的显示如下图
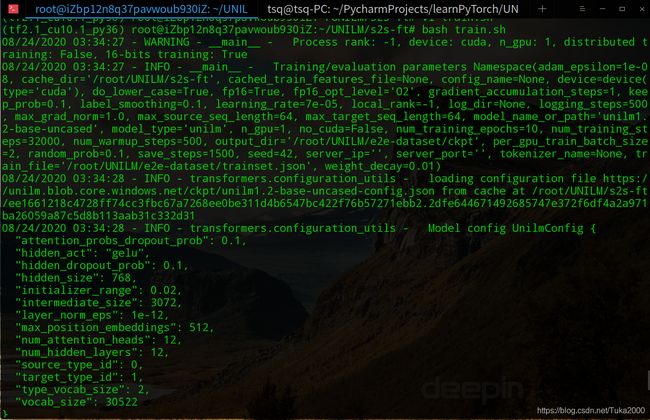
UNILM训练开始的时候会显示一些训练例子给我们,以此来看输入的数据格式是否正确,下面是Source tokens,即输入数据被Bert分词器处理后的效果
每训练1000个batch,UNILM会显示一下loss,并保存这一步的模型到之前train.sh指定的OUTPUT_DIR=/root/UNILM/e2e-dataset/ckpt文件夹下
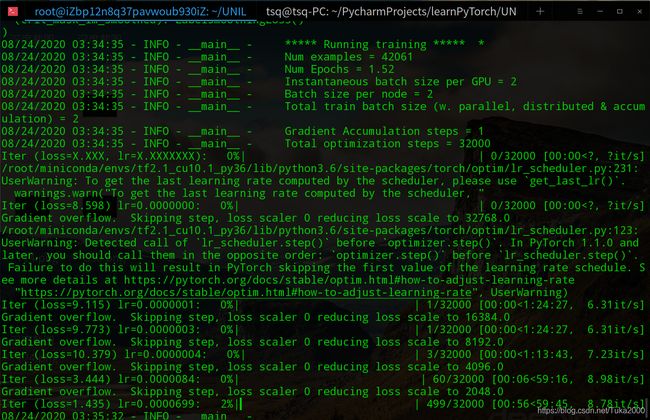
注意:保存的check point是以一个文件夹形式保存的,所以训练完了之后/root/UNILM/e2e-dataset/ckpt下面就会有很多文件夹
2.3 验证
(在训练完了之后才可)
登录服务器
进入/root/UNILM/s2s-ft/ 文件夹
命令行输入
bash valid.sh
即可开始验证,得到的句子例如:
| mr | ref | UNILM模型输出的句子 |
|---|---|---|
| name[The Eagle], eatType[coffee shop], food[English], priceRange[high], customer rating[average], area[city centre], familyFriendly[no], near[Burger King] | The Eagle is a high priced English coffee shop with an average rating thats based in the city centre near to Burger King that isn’t really children-friendly. | the eagle is an english coffee shop in the city centre near burger king . it has a high price range and an average customer rating . |
| name[The Eagle], eatType[coffee shop], food[Chinese], priceRange[high], customer rating[1 out of 5], area[riverside], familyFriendly[no], near[Burger King] | The Eagle is a coffee shop that offers Chinese food. It is not kid friendly and has a 1 out of 5 customer rating. It is located by Burger King in the riverside area. | the eagle is a high priced chinese coffee shop with a customer rating of 1 out of 5 . it is located in the riverside area near burger king and is not child friendly . |
| name[Fitzbillies], eatType[coffee shop], food[Chinese], priceRange[moderate], customer rating[3 out of 5], area[riverside], familyFriendly[no] | Fitzbillies is a coffee shop providing Chinese food in the moderate price range. It is located in the riverside. Its customer rating is 3 out of 5. | fitzbillies is a moderately priced chinese coffee shop with a customer rating of 3 out of 5 . |
分析发现UNILM生成的句子有以下特点:
- 对于相同的mr, UNILM输出的句子也是一样的
- 不同mr,句式变化不大
- 句子内容会根据输入的mr的变化而变化
- UNILM也会漏掉一些信息,不过句子的通顺性,语法的准确性是有保障的
3.结语
从服务器的配置到模型的训练,整个过程中最困难的应该是服务器的配置了,我当时是参考的这篇如何用云服务器进行深度学习的博客去配置的,遇到了版本对不上UNILM要求的问题,又重新来过了几遍才弄对。
在服务器上配环境倒是有这么一个好处: 不用担心会烧坏cpu啊、把系统整崩溃了或者什么东西,反正按小时计费,整坏了可以换一台机子,大不了重新配置一遍。