共轭梯度法(Conjugate Gradients)(4)
最近在看ATOM,作者在线训练了一个分类器,用的方法是高斯牛顿法和共轭梯度法。看不懂,于是恶补了一波。学习这些东西并不难,只是难找到学习资料。简单地搜索了一下,许多文章都是一堆公式,这谁看得懂啊。
后来找到一篇《An Introduction to the Conjugate Gradient Method Without the Agonizing Pain》,解惑了。
为什么中文没有这么良心的资料呢?英文看着费劲,于是翻译过来搬到自己的博客,以便回顾。
由于原文比较长,一共 66 66 66 页的PDF,所以这里分成几个部分来写。
目录
共轭梯度法(Conjugate Gradients)(1)
共轭梯度法(Conjugate Gradients)(2)
共轭梯度法(Conjugate Gradients)(3)
共轭梯度法(Conjugate Gradients)(4)
共轭梯度法(Conjugate Gradients)(5)
12. Preconditioning
预条件?(Preconditioning)是一种提升矩阵条件数(condition number)的技术。
假设 M M M 是一个近似于 A A A 的对称正定矩阵,但更容易求逆。
要求解 A x = b Ax=b Ax=b,可以通过求解下面的式子间接得到。 M ( − 1 ) A x = M ( − 1 ) b (53) M^{(-1)} Ax = M^{(-1)}b \tag{53} M(−1)Ax=M(−1)b(53)
如果 κ ( M ( − 1 ) A ) ≪ κ ( A ) \kappa(M^{(-1)} A) \ll \kappa(A) κ(M(−1)A)≪κ(A),或者 M − 1 A M^{-1} A M−1A 的特征值比 A A A 的聚(clustered)得更好,我们可以比原问题更快地迭代地求解式子(53)。问题是, M − 1 A M^{-1}A M−1A 不会通常是对称或者定(definite,正定或负定)的,尽管 M M M 和 A A A 都是对称或者定。
我们可以克服这个困难,因为对于每一个对称的,正定的 M M M,总是有一个(不是唯一的)矩阵 E E E 拥有这样的特性: E E T = M EE^T=M EET=M。(这样的 E E E 是可以获得的,例如用 Cholesky 分解 )。矩阵 M − 1 A M^{-1}A M−1A 和矩阵 E − 1 A E − T E^{-1} A E^{-T} E−1AE−T 有同样的特征值。这是因为,如果 v v v 是 M − 1 A M^{-1}A M−1A 的特征向量,特征值为 λ \lambda λ;则 E T v E^Tv ETv 就是 E − 1 A E − T E^{-1} A E^{-T} E−1AE−T 的特征向量,特征值为 λ \lambda λ:
( E − 1 A E − T ) ( E T v ) = ( E T E − T ) E − 1 A v = E T M − 1 A v = λ E T v (E^{-1} A E^{-T}) (E^T v) = (E^T E^{-T}) E^{-1} Av = E^T M^{-1} Av = \lambda E^T v (E−1AE−T)(ETv)=(ETE−T)E−1Av=ETM−1Av=λETv
A x = b Ax=b Ax=b 这个系统可以转换为问题:
E − 1 A E − T x ^ = E − 1 b , x ^ = E T x E^{-1} A E^{-T} \widehat{x} = E^{-1} b, \qquad \widehat{x} = E^T x E−1AE−Tx =E−1b,x =ETx
首先我们求解 x ^ \widehat{x} x ,然后到 x x x。由于 E − 1 A E − T E^{-1} A E^{-T} E−1AE−T 是对称和正定的, x ^ \widehat{x} x 可以用最陡下降或者共轭梯度来求。用 CG 来求解这个系统的过程称为:
Transformed Preconditioned Conjugate Gradient Method
(变换预条件共轭梯度法):
d ^ ( 0 ) = r ^ ( 0 ) = E − 1 b − E − 1 A E − T x ^ ( 0 ) \hat{d}_{(0)} = \hat{r}_{(0)} = E^{-1}b - E^{-1} A E^{-T} \hat{x}_{(0)} d^(0)=r^(0)=E−1b−E−1AE−Tx^(0) α ( i ) = r ^ ( i ) T r ^ ( i ) d ^ ( i ) T E − 1 A E − T d ^ ( i ) \alpha_{(i)} = \dfrac{ \hat{r}_{(i)}^T \hat{r}_{(i)} }{ \hat{d}_{(i)}^T E^{-1} A E^{-T} \hat{d}_{(i)} } α(i)=d^(i)TE−1AE−Td^(i)r^(i)Tr^(i) x ^ ( i + 1 ) = x ^ ( i ) + α ( i ) d ^ ( i ) \hat{x}_{(i+1)} = \hat{x}_{(i)} + \alpha_{(i)} \hat{d}_{(i)} x^(i+1)=x^(i)+α(i)d^(i) r ^ ( i + 1 ) = r ^ ( i ) − α ( i ) E − 1 A E − T d ^ ( i ) \hat{r}_{(i+1)} = \hat{r}_{(i)} - \alpha_{(i)} E^{-1} A E^{-T} \hat{d}_{(i)} r^(i+1)=r^(i)−α(i)E−1AE−Td^(i) β ( i + 1 ) = r ^ ( i + 1 ) T r ^ ( i + 1 ) r ^ ( i ) T r ^ ( i ) \beta_{(i+1)} = \dfrac{ \hat{r}_{(i+1)}^T \hat{r}_{(i+1)} }{ \hat{r}_{(i)}^T \hat{r}_{(i)} } β(i+1)=r^(i)Tr^(i)r^(i+1)Tr^(i+1) d ^ ( i + 1 ) = r ^ ( i + 1 ) + β ( i + 1 ) d ^ ( i ) \hat{d}_{(i+1)} = \hat{r}_{(i+1)} + \beta_{(i+1)} \hat{d}_{(i)} d^(i+1)=r^(i+1)+β(i+1)d^(i)
这种方法有一个你不希望的特点,就是必须算出 E E E。然而,有一些细心的变量替换可以消掉 E E E。令 r ^ ( i ) = E − 1 r ( i ) \hat{r}_{(i)} =E^{-1} {r}_{(i)} r^(i)=E−1r(i) 以及 d ^ ( i ) = E T d ( i ) \hat{d}_{(i)} =E^T d_{(i)} d^(i)=ETd(i),然后利用等式 x ^ ( i ) = E T x ( i ) \hat{x}_{(i)} = E^T x_{(i)} x^(i)=ETx(i) 和 E − T E − 1 = M − 1 E^{-T}E^{-1} = M^{-1} E−TE−1=M−1,我们推导出 Untransformed Preconditioned Conjugate Gradient Method(未变换的预条件共轭梯度法):
r ( 0 ) = b − A x ( 0 ) r_{(0)} = b - Ax_{(0)} r(0)=b−Ax(0) d ( 0 ) = M − 1 r ( 0 ) d_{(0)} = M^{-1} r_{(0)} d(0)=M−1r(0) α ( i ) = r ( i ) T M − 1 r ( i ) d ( i ) T A d ( i ) \alpha_{(i)} = \dfrac{r_{(i)}^T M^{-1} r_{(i)} }{ d_{(i)}^T A d_{(i)} } α(i)=d(i)TAd(i)r(i)TM−1r(i) x ( i + 1 ) = x ( i ) + α ( i ) d ( i ) x_{(i+1)} = x_{(i)} + \alpha_{(i)} d_{(i)} x(i+1)=x(i)+α(i)d(i) r ( i + 1 ) = r ( i ) − α ( i ) A d ( i ) r_{(i+1)} = r_{(i)} -\alpha_{(i)} A d_{(i)} r(i+1)=r(i)−α(i)Ad(i) β ( i + 1 ) = r ( i + 1 ) T M − 1 r ( i + 1 ) r ( i ) T M − 1 r ( i ) \beta_{(i+1)} = \dfrac{ r_{(i+1)}^T M^{-1} r_{(i+1)} }{ r_{(i)}^T M^{-1} r_{(i)} } β(i+1)=r(i)TM−1r(i)r(i+1)TM−1r(i+1) d ( i + 1 ) = M − 1 r ( i + 1 ) + β ( i + 1 ) d ( i ) d_{(i+1)} = M^{-1} r_{(i+1)} + \beta_{(i+1)} d_{(i)} d(i+1)=M−1r(i+1)+β(i+1)d(i)
矩阵 E E E 没有出现在这些式子里了;只有 M − 1 M^{-1} M−1 是需要算的。同理,你也可以导出不需要 E E E 的 Preconditioned Steepest Descent Method。
预条件者(preconditioner) M M M 的有效性由条件数 (condition number) M − 1 A M^{-1}A M−1A 决定,偶尔也取决于特征值聚的情况(clustering)。
剩下的问题是找到一个 preconditioner 能够足够地近似 A A A,以充分地提高收敛性,在每一次迭代中弥补计算 M − 1 r ( i ) M^{-1} r_{(i)} M−1r(i) 的成本。(不需要显式地计算 M M M 或者 M − 1 M^{-1} M−1,只需要计算 M − 1 M^{-1} M−1 乘上一个向量的效果)。在这样的约束下,在这种约束下,有惊人的丰富的可能性提供,而我在此仅能触到及一些皮毛。
直观地说,预处理(preconditioning)是一种试图拉伸二次型,使其看起来更球形,从而使特征值相互靠近。 最好的预条件者(preconditioner)是 M = A M=A M=A;对于这个预条件者, M − 1 A M^{-1}A M−1A 有一个条件数(condition number),那就是 1 1 1,然后二次型是完全的球形,所以求解只需要一次迭代。可惜的是,预条件这一步解决的是系统 M x = b Mx=b Mx=b,所以这根本不是一个有用的预条件者(preconditioner)。
最简单的预条件者(preconditioner)是一个对角矩阵,其中对角项与 A A A 的对角项完全相同。采用这种预条件者(preconditioner)的过程被称为对角预条件(diagonal preconditioning)或者叫雅克比预条件(Jacobi preconditioning),等价于沿着坐标轴缩放二次型。(相比之下,完美预条件者(perfect preconditioner) M = A M=A M=A 是沿着特征向量的轴来缩放二次型。) A A A 对角矩阵很容易求逆,但通常只是一个普通的预条件者(preconditioner)。经过对角预条件(diagonal preconditioning)之后,我们的例子的等高线如 图(36) 所示。

与 图(3) 相比,很明显,已经发生了一些改善。条件数(condition number)从 3.5 3.5 3.5 提升到了大概 2.8 2.8 2.8。当然,对于 n ≫ 2 n \gg 2 n≫2 的系统会得到更多的提升。
还有一种更复杂的预条件者(preconditioner),是不完整的 Cholesky 预条件(incomplete Cholesky preconditioning)。
Cholesky 因式分解(Cholesky factorization)是一种把矩阵 A A A 分解成形式 L L T LL^T LLT 的技术,其中 L L L 是一个下三角矩阵。不完整 Cholesky 因式分解是一种变体,允许很少或者不填充。 A A A 由 L ^ L ^ T \hat{L}\hat{L}^T L^L^T 来近似,其中 L ^ \hat{L} L^ 可能被限制为具有与 A A A 相同的非零元素模式; L L L 的其它元素配抛弃掉了。为了把 L ^ L ^ T \hat{L}\hat{L}^T L^L^T 作为预条件者(preconditioner), L ^ L ^ T ω = z \hat{L}\hat{L}^T \omega = z L^L^Tω=z 的解是通过回代来求得的。( L ^ L ^ T \hat{L}\hat{L}^T L^L^T 的逆不需要被显式地计算)。然而,incomplete Cholesky preconditioning 并不总是稳定。
现在开发出来了许多 preconditioner ,有一些十分复杂,无论你用不用,对于大规模的应用,人们普遍认为 CG 应该与 preconditioner 一起使用。
13. Conjugate Gradients on the Normal Equations
(正规方程上的共轭梯度)
CG 可以用于求解这样的线性系统:其中 A A A 不对称,不正定,甚至不是方阵。
对于最小二乘问题: min x ∥ A x − b ∥ 2 (54) \min_{x} \| Ax-b \|^2 \tag{54} xmin∥Ax−b∥2(54)
可以通过把 式子(54) 的导数设为 0 0 0 来求解: A T A x = A T b (55) A^T Ax = A^T b \tag{55} ATAx=ATb(55)
如果 A A A 是方形、非奇异的,那 式子(55) 的解就是 A x = b Ax=b Ax=b 的解。
如果 A A A 不是方形,且 A x = b Ax=b Ax=b 是 overconstrained 的(即线性无关方程的数量比变量的数量多,或者叫超定?Overdetermined system?),那 式子(55) 的解就不一定是 A x = b Ax=b Ax=b 的解。不过,我们总是可以找到一个 x x x 使 式子(54) —— 每个线性方程的平方误差和(sum of the squares of the errors ) 最小化。
A T A A^TA ATA 是对称且正定的(对于任意 x x x, x T A T A x = ∥ A x ∥ 2 ≥ 0 x^T A^T A x=\| Ax \|^2 \geq 0 xTATAx=∥Ax∥2≥0)。如果 A x = b Ax=b Ax=b 不是 underconstrained 的,那 A T A A^TA ATA 是非奇异的,那像最陡下降和共轭梯度这样的方法可以用于求解 式子(55)。这么做的唯一麻烦就是 A T A A^TA ATA 的条件数(condition number )是 A A A 的条件数的平方,因此收敛速度明显较慢。
一个重要的技术点是,矩阵 A T A A^TA ATA 没有被显式地形成,因为它没有 A A A 那么稀疏。相反,对于式子 A T A d A^TAd ATAd ,我们首先是求 A d Ad Ad,然后再求 A T A d A^TAd ATAd。如果我们通过 A d Ad Ad 和自己的内积来求 d T A T A d d^TA^TAd dTATAd(它在式子(46)l里),那么数值稳定性就会提升。
14. The Nonlinear Conjugate Gradient Method
(非线性共轭梯度法)
CG 不仅能被用于求解二次型问题的最小值,还可以用于最小化任何函数 f ( x ) f(x) f(x),只要能计算它的梯度 f ′ f' f′ 。
它能用于各种各样的优化问题,例如工程设计,训练神经网络,非线性回归等。
14.1 Outline of the Nonlinear Conjugate Gradient Method
(非线性共轭梯度法的概述)
为了推导非线性的 CG,对线性算法做 3 3 3 个改动:用于计算残差的递归公式不能用了。计算步长 α \alpha α 的方法更加复杂。对于 β \beta β 的选择也有一些不同。
在非线性 CG 中,残差总是设为负的梯度: r ( i ) = − f ′ ( x ( i ) ) r_{(i)} = -f'(x_{(i)}) r(i)=−f′(x(i))
搜索方向的计算和线性 CG 里面一样,用残差的格拉姆-施密特共轭(Gram-Schmidt conjugation)来计算。沿着这个搜索方向执行线搜索(line search)比线性情况要困难得多,并且有多种过程可以使用。
和线性 CG 里面一样,通过确保梯度和搜索方向正交,来找到 α ( i ) \alpha_{(i)} α(i) 使 f ( x ( i ) + α ( i ) d ( i ) ) f( x_{(i)} + \alpha_{(i)}d_{(i)}) f(x(i)+α(i)d(i)) 最小化。我们可以使用任何算法来找到式子 [ f ′ ( x ( i ) + α ( i ) d ( i ) ) ] T d ( i ) [f'(x_{(i)} + \alpha_{(i)}d_{(i)})]^Td_{(i)} [f′(x(i)+α(i)d(i))]Td(i) 的零点。
在线性 CG 里, β \beta β 有几个等价的表达式。 在非线性 CG 里,这些表达式不再等价;研究者们仍然在寻求最好的选择。有两种可选的做法,一个是 Fletcher-Reeves 公式,另一个是 Polak-Ribière 公式: β ( i + 1 ) F R = r ( i + 1 ) T r ( i + 1 ) r ( i ) T r ( i ) , β ( i + 1 ) P R = r ( i + 1 ) T ( r ( i + 1 − r ( i ) ) r ( i ) T r ( i ) \beta_{(i+1)}^{FR} = \dfrac{ r_{(i+1)}^T r_{(i+1)} }{ r_{(i)}^T r_{(i)} } ,\qquad \beta_{(i+1)}^{PR} = \dfrac{ r_{(i+1)}^T (r_{(i+1} -r_{(i)}) }{ r_{(i)}^T r_{(i)} } β(i+1)FR=r(i)Tr(i)r(i+1)Tr(i+1),β(i+1)PR=r(i)Tr(i)r(i+1)T(r(i+1−r(i))
如果初始点足够接近所期望的最小值,那么 Fletcher-Reeves 法可以收敛。但在那里 Polak-Ribière 法在少数情况下会无限循环,得不到收敛。不过 Polak-Ribière 法常常会收敛得更快。
幸运的是,令 β = max { β P R , 0 } \beta = \max \{ \beta^{PR},0\} β=max{βPR,0} 可以保证 Polak-Ribière 法收敛。如果 β P R < 0 \beta^{PR} <0 βPR<0,使用该值相当于重启 CG。重启 CG 就是忘掉过去的搜索方向,并向最陡下降的方向重新开始 CG。
下面是非线性共轭梯度法的概览: d ( 0 ) = r ( 0 ) = − f ′ ( x ( 0 ) ) , d_{(0)} = r_{(0)} = -f'(x_{(0)}), d(0)=r(0)=−f′(x(0)), Find α ( i ) that minimizes f ( x ( i ) + α ( i ) d ( i ) ) , \text{Find} \; \alpha_{(i)} \; \text{that minimizes} \; f(x_{(i)} + \alpha_{(i)} d_{(i)}), Findα(i)that minimizesf(x(i)+α(i)d(i)), x ( i + 1 ) = x ( i ) + α ( i ) d ( i ) , x_{(i+1)} = x_{(i)} + \alpha_{(i)} d_{(i)}, x(i+1)=x(i)+α(i)d(i), r ( i + 1 ) = − f ′ ( x ( i + 1 ) ) , r_{(i+1)} = - f'(x_{(i+1)}), r(i+1)=−f′(x(i+1)), β ( i + 1 ) = r ( i + 1 ) T r ( i + 1 ) r ( i ) T r ( i ) or β ( i + 1 ) = max { r ( i + 1 ) T ( r ( i + 1 ) − r ( i ) ) r ( i ) T r ( i ) , 0 } \beta_{(i+1)} = \dfrac{r_{(i+1)}^T r_{(i+1)} }{ r_{(i)}^T r_{(i)} } \qquad \text{or} \qquad \beta_{(i+1)} = \max \left\{ \dfrac{r_{(i+1)}^T ( r_{(i+1)} -r_{(i)} ) }{ r_{(i)}^T r_{(i)} } ,0 \right\} β(i+1)=r(i)Tr(i)r(i+1)Tr(i+1)orβ(i+1)=max{r(i)Tr(i)r(i+1)T(r(i+1)−r(i)),0} d ( i + 1 ) = r ( i + 1 ) + β ( i + 1 ) d ( i ) d_{(i+1)} = r_{(i+1)} + \beta_{(i+1)} d_{(i)} d(i+1)=r(i+1)+β(i+1)d(i)
非线性 CG 不像线性 CG 那么能保证收敛。 f f f 与二次函数越不像,搜索方向就会越快失去共轭性。(很快就会清楚,“共轭(conjugacy)”在非线性 CG 中仍然有一些意义。)
另外一个问题是,一般性的函数 f f f 可能有许多局部最小值。CG 不能保证收敛到全局最小值。如果 f f f 没有下界,甚至可能找不到局部最小值。
图(37) 展示了非线性 CG。
图(37)a 的方程有多个局部最小值。
图(37)b 展示了用 Fletcher-Reeves 公式时,非线性 CG 的收敛情况。在这个例子里, CG 几乎不像线性的情况那么有效;这个函数似乎很难最小化。
图(37)c 展示了一个横截面,对应于 图(37)b 的第一条线搜索。注意到会有好几个极小值,线搜索会找到一个 α \alpha α ,对应于附近的最小值。
图(37)d 展示了 Polak-Ribière CG 的优越的收敛情况。
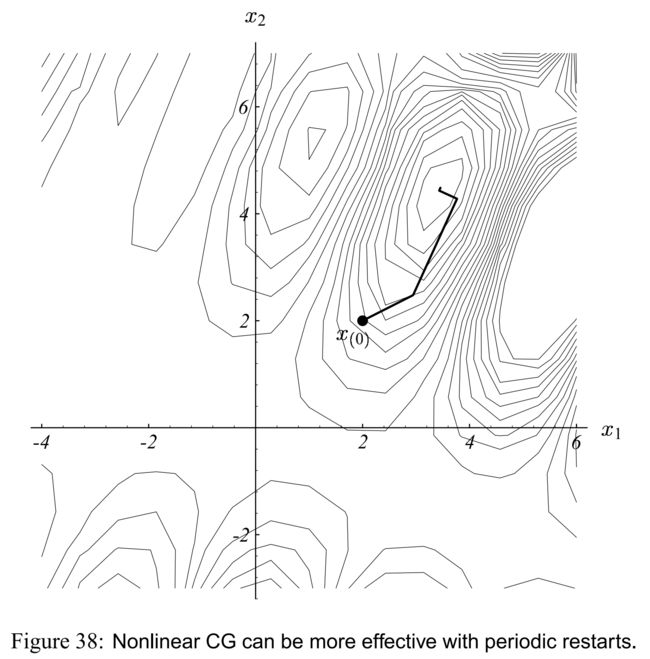
由于 CG 只能在 n n n 维空间生成 n n n 个共轭向量, 所以每 n n n 次迭代后重启 CG 是有意义的,特别是 n n n 很小的时候。图(38) 展示了非线性 CG 每第二次迭代就重启的效果。(对于这个特殊的例子, Fletcher-Reeves 法和 Polak-Ribière 法的表现都是一样的)
14.2 General Line Search(一般的线搜索)
依赖 f ′ f' f′ 的值,我们有机会使用一个快速的算法来找到 f ′ T d f'^Td f′Td 的零点。
例如,如果 f ′ f' f′ 是 α \alpha α 中的多项式,那就能用上高效的算法进行多项式的寻零(zero-finding)。
然而,我们将会仅考虑通用性的算法。
两种寻零(zero-finding)的迭代法分别是牛顿-拉夫森(Newton-Raphson)算法和弦截(Secant)法。两种算法都要求 f f f 二阶连续可微。 牛顿-拉夫森(Newton-Raphson) 算法还会要求求 f ( x + α d ) f(x+\alpha d) f(x+αd) 关于 α \alpha α 的二阶导。
牛顿-拉夫森(Newton-Raphson) 算法依赖于泰勒级数(Taylor series)的近似
f ( x + α d ) ≈ f ( x ) + α [ d d α f ( x + α d ) ] α = 0 + α 2 2 [ d 2 d α 2 f ( x + α d ) ] α = 0 ( 56 ) = f ( x ) + α [ f ′ ( x ) ] T d + α 2 2 d T f ′ ′ ( x ) d d d α f ( x + α d ) ≈ [ f ′ ( x ) ] T d + α d T f ′ ′ ( x ) d . ( 57 ) \begin{aligned} f(x+\alpha d) & \approx f(x) + \alpha \left[ \dfrac{d}{d\alpha} f(x+ \alpha d) \right]_{\alpha=0} + \dfrac{\alpha^2}{2} \left[ \dfrac{d^2}{d\alpha^2} f(x+ \alpha d) \right]_{\alpha=0} \qquad (56) \\[1em] &= f(x) + \alpha [f'(x)]^T d + \dfrac{\alpha^2}{2} d^T f''(x) d \\[1em] \dfrac{d}{d\alpha} f(x+ \alpha d) & \approx [f'(x)]^T d + \alpha d^T f''(x)d. \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad (57) \end{aligned} f(x+αd)dαdf(x+αd)≈f(x)+α[dαdf(x+αd)]α=0+2α2[dα2d2f(x+αd)]α=0(56)=f(x)+α[f′(x)]Td+2α2dTf′′(x)d≈[f′(x)]Td+αdTf′′(x)d.(57)
其中 f ′ ′ ( x ) f''(x) f′′(x) 为海森矩阵(Hessian matrix):
f ′ ′ ( x ) = [ ∂ 2 f ∂ x 1 ∂ x 1 ∂ 2 f ∂ x 1 ∂ x 2 ⋯ ∂ 2 f ∂ x 1 ∂ x n ∂ 2 f ∂ x 2 ∂ x 1 ∂ 2 f ∂ x 2 ∂ x 2 ⋯ ∂ 2 f ∂ x 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ 2 f ∂ x n ∂ x 1 ∂ 2 f ∂ x n ∂ x 2 ⋯ ∂ 2 f ∂ x n ∂ x n ] f''(x)= \begin{bmatrix} \dfrac{\partial^2 f}{\partial x_1 \partial x_1} & \dfrac{\partial^2 f}{\partial x_1 \partial x_2} & \cdots & \dfrac{\partial^2 f}{\partial x_1 \partial x_n} \\[1.5em] \dfrac{\partial^2 f}{\partial x_2 \partial x_1} & \dfrac{\partial^2 f}{\partial x_2 \partial x_2} & \cdots & \dfrac{\partial^2 f}{\partial x_2 \partial x_n} \\[1.5em] \vdots & \vdots & \ddots & \vdots \\[1.5em] \dfrac{\partial^2 f}{\partial x_n \partial x_1} & \dfrac{\partial^2 f}{\partial x_n \partial x_2} & \cdots & \dfrac{\partial^2 f}{\partial x_n \partial x_n} \end{bmatrix} \\[1.5em] f′′(x)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡∂x1∂x1∂2f∂x2∂x1∂2f⋮∂xn∂x1∂2f∂x1∂x2∂2f∂x2∂x2∂2f⋮∂xn∂x2∂2f⋯⋯⋱⋯∂x1∂xn∂2f∂x2∂xn∂2f⋮∂xn∂xn∂2f⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
通过将 式子(57) 置零,可以将函数 f ( x + α d ) f(x+ \alpha d) f(x+αd) 近似最小化,给定: α = − f ′ T d d T f ′ ′ d \alpha = - \dfrac{ f'^T d}{ d^T f^{''} d } α=−dTf′′df′Td
截断的泰勒级数通过一个抛物面近似 f ( x + α d ) f(x + \alpha d) f(x+αd),我们走到抛物面的底部,,见 图(39)。实际上,如果 f f f 是一个二次型,那么这个抛物线近似是精确的,因为 f ′ ′ f'' f′′ 就是我们熟悉的矩阵 A A A。通常来讲,如果搜索方向都是 f ′ ′ f{''} f′′-正交的,那么这些搜索方向就共轭(conjugate)。

“共轭(conjugate)” 的含义一直在变化,因为 f ′ ′ f{''} f′′ 是随着 x x x 而变化的。 f ′ ′ f{''} f′′ 随 x x x 变化得越快,搜索方向就越快失去共轭性(conjugacy)。另一方面, x ( i ) x_{(i)} x(i) 越接近解,每次迭代的 f ′ ′ f{''} f′′ 就变化越小。起始点越靠近解,非线性 CG 和线性 CG 的收敛性就越像。
为了在非二次型的方程上进行精确的线搜索,必须沿着搜索线重复地走,知道 f ′ T d f'^{T}d f′Td 为 0 0 0。因此,一个 CG 的迭代可能包含许多次 牛顿-拉夫森(Newton-Raphson)迭代。 必须在每一步都计算 f ′ T d f'{T}d f′Td 和 d T f ′ ′ d d^T f{''}d dTf′′d 的值。如果 d T f ′ ′ d d^T f{''}d dTf′′d 可以被解析性地简化,那么这些计算就没什么开销。但如果必须计算完整的矩阵 f ′ ′ f{''} f′′,那算法就会很慢。对于某些应用,可以通过仅用 f ′ ′ f{''} f′′ 的对角元素来进行近似的线搜索,来规避这个问题。当然,有一些函数根本不可能计算 f ′ ′ f{''} f′′。
为了进行精确的线搜索而不计算 f ′ ′ f{''} f′′,弦截(Secant)法通过在不同的两点 α = 0 \alpha=0 α=0 和 α = σ \alpha = \sigma α=σ 计算 f ( x + α d ) f(x+\alpha d) f(x+αd) 的一阶导,来近似 f ( x + α d ) f(x+\alpha d) f(x+αd) 的二阶导。其中 σ \sigma σ 是任意小的非零数: d 2 d α 2 f ( x + α d ) ≈ [ d d α f ( x + α d ) ] α = σ − [ d d α f ( x + α d ) ] α = 0 σ σ ≠ 0 = [ f ′ ( x + σ d ) ] T d − [ f ′ ( x ) ] T d σ (58) \begin{aligned} \dfrac{d^2}{d\alpha^2} f(x+ \alpha d) & \approx \dfrac{ \left[ \dfrac{d}{d\alpha} f(x+ \alpha d) \right]_{\alpha = \sigma} - \left[ \dfrac{d}{d\alpha} f(x+ \alpha d) \right]_{\alpha = 0} }{ \sigma } \qquad \sigma \neq 0 \\[1em] &= \dfrac{ \left[ f'(x + \sigma d) \right]^T d - [f'(x)]^T d }{ \sigma } \end{aligned} \tag{58} dα2d2f(x+αd)≈σ[dαdf(x+αd)]α=σ−[dαdf(x+αd)]α=0σ=0=σ[f′(x+σd)]Td−[f′(x)]Td(58)
其中当 α \alpha α 和 σ \sigma σ 逼近 0 0 0 的时候,它能更好地近似二阶导。
如果我们用 式子(58) 来替代泰勒展开式(式子(56))中的第 3 3 3 项,就有: d d α f ( x + α d ) ≈ [ f ′ ( x ) ] T d + α σ { [ f ′ ( x + σ d ) ] T d − [ f ′ ( x ) ] T d } \dfrac{d}{d\alpha} f(x+ \alpha d) \approx [f'(x)]^Td + \dfrac{\alpha}{\sigma} \left\{ [f'(x+\sigma d)]^T d - [f'(x)]^T d \right\} dαdf(x+αd)≈[f′(x)]Td+σα{[f′(x+σd)]Td−[f′(x)]Td}
通过将 f ( x + α d ) f(x+ \alpha d) f(x+αd) 的导数置 0 0 0 来最小化它: α = − σ [ f ′ ( x ) T ] d [ f ′ ( x + σ d ) ] T d − [ f ′ ( x ) ] T d (59) \alpha = - \sigma \dfrac{ [f'(x)^T] d}{ [f'(x+\sigma d)]^T d - [f'(x)]^T d } \tag{59} α=−σ[f′(x+σd)]Td−[f′(x)]Td[f′(x)T]d(59)
像 牛顿-拉夫森(Newton-Raphson) 法一样,弦截(Secant)法也用一个抛物线(parabola)来近似 f ( x + α d ) f(x+ \alpha d) f(x+αd)。但是 弦截法 不是通过在 1 1 1 个点上求一阶和二阶导来找到抛物线,而是在两个不同的点上求一阶导,见 图(40)。
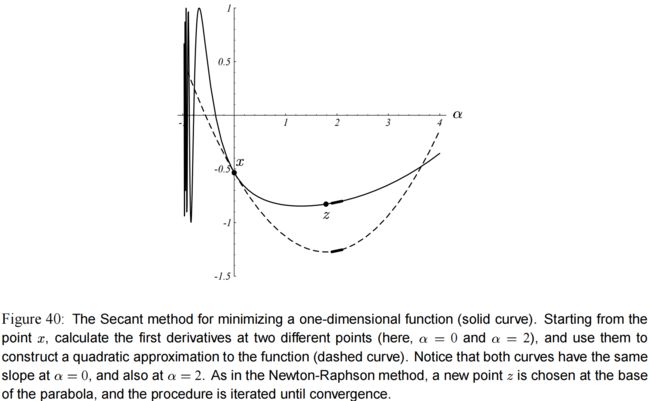
通常,我们在弦截(Secant)法的第一个迭代中选择任意的 σ \sigma σ;在后续迭代中,我们选择 x + σ d x+ \sigma d x+σd 作为上一次弦截(Secant)迭代法的 x x x 的值。换句话说,如果我们令 α [ i ] \alpha_{[i]} α[i] 表示在弦截法第 i i i 次迭代中算出来的 α \alpha α 的值,那么 σ [ i + 1 ] = − α [ i ] \sigma_{[i+1]} = -\alpha_{[i]} σ[i+1]=−α[i]。
当 x x x 足够接近精确解时,牛顿-拉夫森(Newton-Raphson) 法和 弦截(Secant)法都应当终止。
当要求的精度过低,可能会导致收敛失败,但是要求的精度太高会导致计算很慢,而且没有任何收获。因为如果 f ′ ′ ( x ) f''(x) f′′(x) 随 x 变化很大,共轭性将很快崩溃。因此,进行快而不精确的线搜索往往是更好的策略(例如,固定 Newton-Raphson 和 Secant 法的迭代次数 )。不幸的是,不精确的线搜索可能会导致,构建的搜索方向不是下降的方向。一个常见的解决方案是测试这种可能性: r T d r^Td rTd 是负的吗?然后有必要的话,通过令 d = r d=r d=r 重启 CG。
两种方法都有一个更大的问题,就是他们不能区分最小值和最大值。非线性 CG 的结果通常严重依赖初始位置,如果用 Newton-Raphson 或者 Secant 法的 CG 从局部最大值的附近开始,它可能会收敛到那个点上。
两种方法各有优点,Newton-Raphson 法收敛速度更快,如果能够很快地计算 d T f ′ ′ d d^T f'' d dTf′′d (或者能很好地近似),例如时间复杂度在 O ( n ) \mathcal{O}(n) O(n) 以内,那么首选Newton-Raphson法。
Secant 法只需要求 f f f 的一阶导,但是它能否成功,取决于参数 σ \sigma σ 选得好不好。
其它的方法也很容易推导出来,例如,通过在 3 3 3 个不同的点采样 f f f,有可能产生一个抛物线来近似 f ( x + α d ) f(x+ \alpha d) f(x+αd),甚至不需要求 f f f 的一阶导。
14.3 Preconditioning
可以通过选择一个预条件者(preconditioner) M M M 来预条件(preconditioning)非线性 CG,对这个 M M M 的要求是, M M M 要近似于 f ′ ′ f'' f′′,且要使 M − 1 r M^{-1}r M−1r 容易计算。
在线性 CG 中,预条件者(preconditioner)试图将二次型变换,使其变得像一个球型。
在非线性 CG 中,预条件者(preconditioner)是在 x ( i ) x_{(i)} x(i) 的一个邻域上做这个变换的。
计算完整的海森矩阵(Hessian Matrix) f ′ ′ f'' f′′ 开销很大,通常计算它的对角线来作为预条件者(preconditioner)。然而,要提前告诉你的是,如果 x x x 距离局部最小值足够远,海森矩阵的对角元素可能不是全为正数。预条件者(preconditioner)应该是正定的,所以不允许有负的对角元素。一个保守的解决方案是,当无法保证海森矩阵是正定的时候,那就不做预条件(precondition)(令 M = I M=I M=I)。
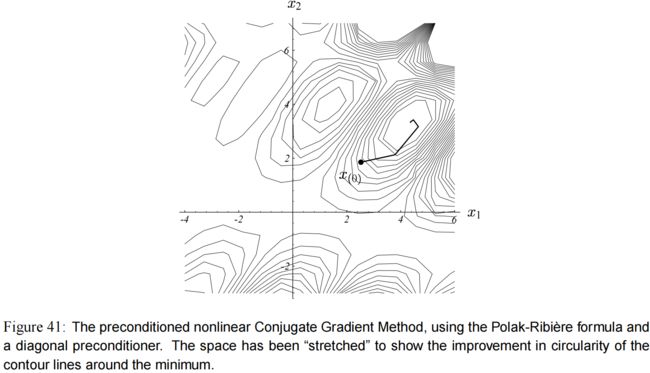
图(41) 展示的是对角预条件的非线性共轭梯度(diagonally preconditioned nonlinear CG) 的收敛情况,用的是 Polak-Ribière 法,和 图(37) 中的方程一样。这里我作弊了一下,在每次迭代中,在解点 x x x 处用 f ′ ′ f'' f′′ 的对角元素来预条件(precondition)。