Predicting Depth,Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Archite
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture
主要贡献:
使用multi scale训练, 每一阶段的输入都是累加上一阶段的输出和原图像的一层卷积下采样.
第一阶段和第二阶段联合训练(感觉就是可以把第一阶段和第二阶段联合在一起了 这不过把第一阶段最后的输出和第一阶段第一层的特征图串联输入给下一层, 相当于变相的使用了跳跃连接, 但是把12和3分开好在是省时间, 让2的输出和实际的label相同的大小, 这样就可以求损失值)
1 Introduction
本文多尺度方法直接从图像生成像素级图, 不需要低级的超像素和外形, 并且能够使用一系列的卷积栈在越来越高的分辨率上对齐图像细节.
代码: http://cs.nyu.edu/~deigen/dnl/
2 Related work
对于语义分割, 相比于只使用局部特征或者离散的proposals描述. 本文的网络使用局部和全局预测. 并且能够用于三个不同的任务.
本文使用三种不同的尺度去生成特征并且改善预测到更高的分辨率.
之前的语义分割方法是使用RGB数据. 大多数使用局部特征来对过度分割的区域进行分类,这是通过全局一致性优化(如CRF)来实现的. 本文显示进行一致的全局预测, 然后进行迭代局部细化. 这么做可以让局部网络意识到他们在全局场景上的地位, 并且可在他们精确的预测中使用这些信息.
Gupta首先通过生成轮廓来创建语义分割,然后使用手动生成的特征和SVM或用于对象检测的卷积网络对区域进行分类。值得注意的是,还执行amodal完成,其通过比较来自深度的平面来在图像的不同区域之间传输标签。
本文的方法, 首先模型在最粗糙的范围内具有大的全图像视野. 对应不同的阶段学习不同的网络.
3 Model Architecture
本文的模型是一个多尺度深度网络, 首先根据整个图像预测粗略的全局输出, 然后使用更精细的局部网络进行细化.
模型先是用别的模型初始化.
网格结构方面与文献《Depth map prediction from a single image using a multi-scale deep network》基本相似,可以说是在这篇paper的基础上做的修改,区别在于:
(1)采用了更深层的网络
(2)增加了第三个尺度的网络,使得我们的输出是更高分辨率的图片(之前的paper输出大小是55*77,现在最后网络的输出大小是109*147)
(3)与之前的思路有点不同,之前采用的方式是,先训练scale1,训练完成后,以scale 1的输出作为scale 2的输入。现在所采用的方式是:scale 1和scale 2联合训练,最后固定这两个尺度CNN,在训练scale 3
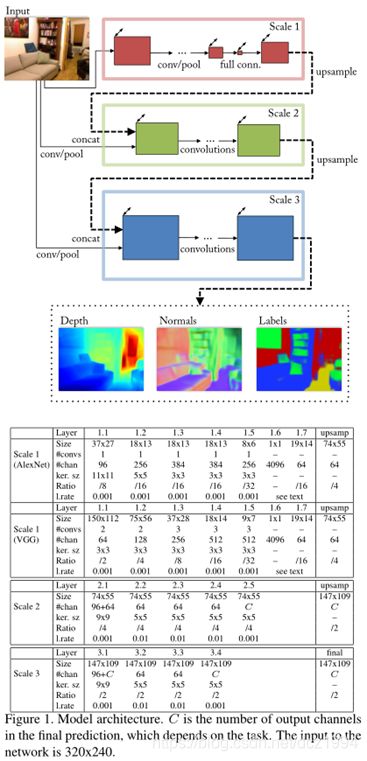
Scale1: Full-Image View
网络的输入:原始图片,输入图片大小为 三通道彩色图片. 网络的输出:19*14大小的图片. 然后上采样到74X55.
Scale2: Predictions
串联"scale1的输出特征"和"卷积池化后的原图特征"进行卷积训练. 之后再上采样.
Scale3: Higer resolution
多加了这个尺度的网络,仅仅只是为了获得更高分辨率的输出.
串联"scale2的输出特征"和"卷积池化后的原图特征"进行卷积训练.
4 Task
4.3 Semantic Labels
使用像素级softmax分类去预测每个像素类别标签,
单个像素交叉熵损失:
![]()

5 Training
5.1 Training procedure
训练使用SGD分为两个阶段:
1 连接Scale1和2一起训练(这和输出有关系, 以为Scale1的输出不是原始图像的大小, 语义分割肯定行不通, 但是Scale2是, 这也间接说明了Scale3仅仅是为了调节精准度而已).
2 固定之上的Scale参数, 训练Scale3. 由于输入Scale3的像素数量Scale2的4倍, 为了加速训练随机裁剪74X55的大小, 首先是把图像通过Scale1和2前向传播, 然后裁剪结果作为Scale3的输入.
5.2 Data Augmentation
在旋转, 平移, 颜色, 翻转和对比中使用随机缩放.