NLP学习笔记(三) GRU基本介绍
大家好,我是半虹,这篇文章来讲门控循环单元 (Gated Recurrent Unit, GRU)
文章行文思路如下:
- 首先通过长短期记忆网络引出为什么需要门控循环单元
- 然后介绍门控循环单元的核心思想与运作方式
- 最后通过简洁的代码深入理解门控循环单元的运作方式
在之前的文章中,我们已经介绍过循环神经网络和长短期记忆网络
知道了长短期记忆网络是为了缓解循环神经网络容易出现梯度消失的情况而设计的
然而,长短期记忆网络的参数确实有点多,计算速度也是有点慢,所以后来就有人提出了门控循环单元
门控循环单元与长短期记忆网络效果相当,但是其参数更少,且计算速度更快
对比长短期记忆网络,门控循环单元去除了记忆元,但仍保留了门机制,只不过门机制的种类稍有不同
以下是循环神经网络、长短期记忆网络、门控循环单元三者的对比
| 网络 | 是否有记忆元 | 传递状态 | 是否有门机制 | 门机制的种类 |
|---|---|---|---|---|
| 循环神经网络 | 否 | 隐状态 | 否 | 无 |
| 长短期记忆网络 | 是 | 隐状态、记忆元 | 是 | 输入门、遗忘门、输出门 |
| 门控循环单元 | 否 | 隐状态 | 是 | 重置门、更新门 |
我们发现,门控循环单元仅在隐状态上就能实现对长期记忆的控制
这是怎么做到的呢?其核心就在于门机制,通过门机制控制隐状态中的信息流动
从直觉上来说,先前重要的记忆会保留在隐状态,不重要的记忆会被过滤,以此达到长期记忆的目的
门控循环单元中的门机制包括两类:
- 重置门:用于控制记住多少旧状态,英文为 Reset Gate \text{Reset Gate} Reset Gate
- 更新门:用于控制新旧状态的占比,英文为 Update Gate \text{Update Gate} Update Gate
实际上,所谓的门机制,就是一个带激活函数的线性层而已,且激活函数通常会用 sigmoid \text{sigmoid} sigmoid
因为这样能将输出限制在零到一之间,以表示门的打开程度,控制信息流动的程度
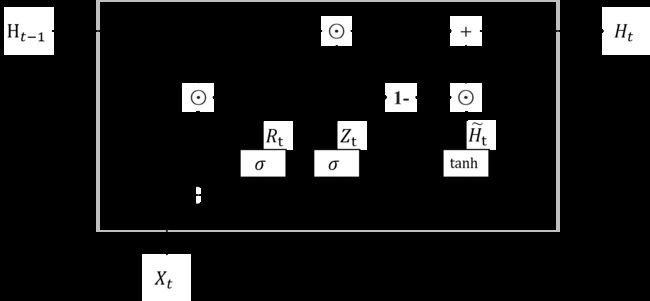
好了,下面进入本文的核心,介绍门机制是如何运作的
首先,通过当前输入 X t X_{t} Xt 和先前隐状态 H t − 1 H_{t-1} Ht−1,计算得到重置门 R t R_{t} Rt、更新门 Z t Z_{t} Zt
其中, W x r W_{xr} Wxr、 W h r W_{hr} Whr、 b r b_{r} br、 W x z W_{xz} Wxz、 W h z W_{hz} Whz、 b z b_{z} bz 是网络参数, σ \sigma σ 是 sigmoid \text{sigmoid} sigmoid 激活函数
R t = σ ( X t W x r + H t − 1 W h r + b r ) Z t = σ ( X t W x z + H t − 1 W h z + b z ) \begin{align*} R_{t} &= \sigma (X_{t} W_{xr} + H_{t-1} W_{hr} + b_{r}) \\ Z_{t} &= \sigma (X_{t} W_{xz} + H_{t-1} W_{hz} + b_{z}) \end{align*} RtZt=σ(XtWxr+Ht−1Whr+br)=σ(XtWxz+Ht−1Whz+bz)
然后,通过当前输入 X t X_{t} Xt 和先前隐状态 H t − 1 H_{t-1} Ht−1,同时集成重置门 R t R_{t} Rt,计算得到候选隐状态 H ~ t \tilde{H}_{t} H~t
其中, ⊙ \odot ⊙ 表示按元素乘法, tanh \text{tanh} tanh 是 tanh \tanh tanh 激活函数,重置门用于控制先前隐状态对当前候选隐状态的影响
H ~ t = tanh ( X t W x h + ( R t ⊙ H t − 1 ) W h h + b h ) \tilde{H}_{t} = \tanh (X_{t} W_{xh} + (R_{t} \odot H_{t-1}) W_{hh} + b_{h}) H~t=tanh(XtWxh+(Rt⊙Ht−1)Whh+bh)
最后,更新门 Z t Z_{t} Zt 控制采用多少来自 H t − 1 H_{t-1} Ht−1 的旧信息,多少来自 H ~ t \tilde{H}_{t} H~t 的新信息,计算得到当前隐状态 H t H_{t} Ht
其中, ⊙ \odot ⊙ 表示按元素乘法,更新门对于旧信息和新信息的记忆总是保持“恒定”
H t = Z t ⊙ H t − 1 + ( 1 − Z t ) ⊙ H ~ t H_{t} = Z_{t} \odot H_{t-1} + (1 - Z_{t}) \odot \tilde{H}_{t} Ht=Zt⊙Ht−1+(1−Zt)⊙H~t
上述计算过程对应的计算图如下所示:
最后我们来简单实现一下门控循环单元
作为例子,我们用这个门控循环单元对以下句子进行编码:我在画画
import torch
import torch.nn as nn
# 定义输入数据
# 对于输入句子我在画画,首先用独热编码得到其向量表示
x1 = torch.tensor([1, 0, 0]).float() # 我
x2 = torch.tensor([0, 1, 0]).float() # 在
x3 = torch.tensor([0, 0, 1]).float() # 画
x4 = torch.tensor([0, 0, 1]).float() # 画
h0 = torch.zeros(5) # 初始化隐状态
# 定义模型参数
# 模型的输入是三维向量,这里定义模型的输出是五维向量
W_xr = nn.Parameter(torch.randn(3, 5), requires_grad = True)
W_hr = nn.Parameter(torch.randn(5, 5), requires_grad = True)
b_r = nn.Parameter(torch.randn(5) , requires_grad = True)
W_xz = nn.Parameter(torch.randn(3, 5), requires_grad = True)
W_hz = nn.Parameter(torch.randn(5, 5), requires_grad = True)
b_z = nn.Parameter(torch.randn(5) , requires_grad = True)
W_xh = nn.Parameter(torch.randn(3, 5), requires_grad = True)
W_hh = nn.Parameter(torch.randn(5, 5), requires_grad = True)
b_h = nn.Parameter(torch.randn(5) , requires_grad = True)
# 前向传播
def forward(X, H):
# 计算各种门机制
R = torch.sigmoid(torch.matmul(X, W_xr) + torch.matmul(H, W_hr) + b_r) # 重置门
Z = torch.sigmoid(torch.matmul(X, W_xz) + torch.matmul(H, W_hz) + b_z) # 更新门
# 计算候选隐状态
H_tilde = torch.tanh(torch.matmul(X, W_xh) + torch.matmul(R * H, W_hh) + b_h)
# 计算当前隐状态
H = Z * H + (1 - Z) * H_tilde
# 返回结果
return H
h1 = forward(x1, h0)
h2 = forward(x2, h1)
h3 = forward(x3, h2)
h4 = forward(x4, h3)
# 结果输出
print(h3) # tensor([ 0.7936, -0.9788, 0.8360, 0.2307, -0.9928])
print(h4) # tensor([ 0.8460, -0.9946, 0.9130, 0.0313, -0.9986])
至此本文结束,要点总结如下:
- 门控循环单元与长短期记忆网络效果相当,但是其参数更少,且计算速度更快
- 门控循环单元通过门机制,仅在隐状态上就能实现对长期记忆的控制