详细说说业务主键和非业务主键
什么是业务主键和非业务主键
主键,就是指在数据表中,可以唯一表示一条数据的字段。例如表记录的序号,或者订单表里的订单号等。
业务主键,就是从业务层面上来反应数据等唯一性,比如订单号,员工编号,商品编号等。这些编号一般都会包含一定的业务含义。比如订单号会拼入下单日期时间,员工编号可能拼入入职时间,商品编号会拼入商品分类缩写等等。并且为了能统一维护,业务主键一般是按照规则生成的定长的字符串。
非业务主键,就是和业务无关,真正的表数据的唯一标记。一般会采用bigint类型的自增列作为非业务主键。非业务主键是数据表真正意义上的主键。主键索引也是基于这个非业务主键来生成的。
为什么要有非业务主键,业务主键为什么不能取代非业务主键
下面我以mysql为例,讲一下我对于这两个问题的看法。
B+树
要说明这两个问题,就必须说到索引的存储结构B+树。
我们都知道,mysql的索引都是以B+树的形式存储在内存中。关于B+树的说明,网上有很多,我这边就只做简单的必要说明。忘记的,可以参照下面这个文章。
一文彻底搞懂MySQL索引
B+树是聚簇索引,即所有的数据都会在叶子结点中存储,而枝节点只会存储子节点的引用地址。这是B+树的特地昂,并且每个节点都是存储在磁盘中的同一页中。当我们需要查找数据的时候,其实将磁盘的某一页加载到内容中,然后进行处理。而B+树所有的数据行都是存储在叶子结点,即所有的查找都需要到达某一个叶子结点才能完成。于是对于B+树而言,每一次的查找,深度都是一样的。
因为数据从磁盘加载到内存的时间,比在内存中查找数据的时间消耗多得多,所以,就必须减少B+树的查找深度。换句话说,如何让枝节点尽量的多存储数据,才是提高查询性能的关键因素。

以上图这个B+树为例,假设枝节点只能存储三个引用,那么存储45个数据需要三层。查找数据时,从根节点到叶子结点需要三次加载磁盘数据到内存中,最后在叶子结点中找到数据。
但是如果一个枝节点可以存储9个引用,那么B+树的深度就变为2,查找数据只要加载两次磁盘数据到内存即可完成。
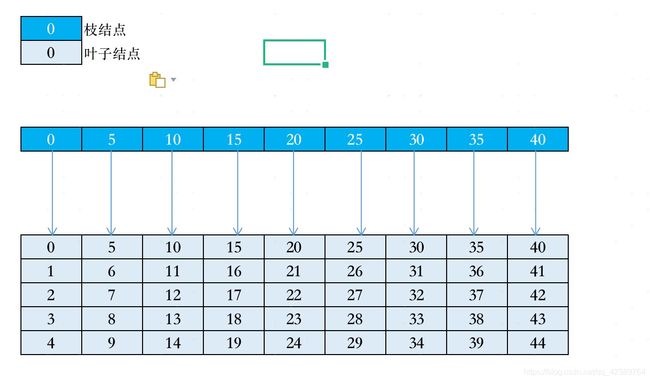
或者说,枝节点不变,数据大小减小,使得一个叶子结点可以存储15条数据,也可以将B+树的深度降到两层。
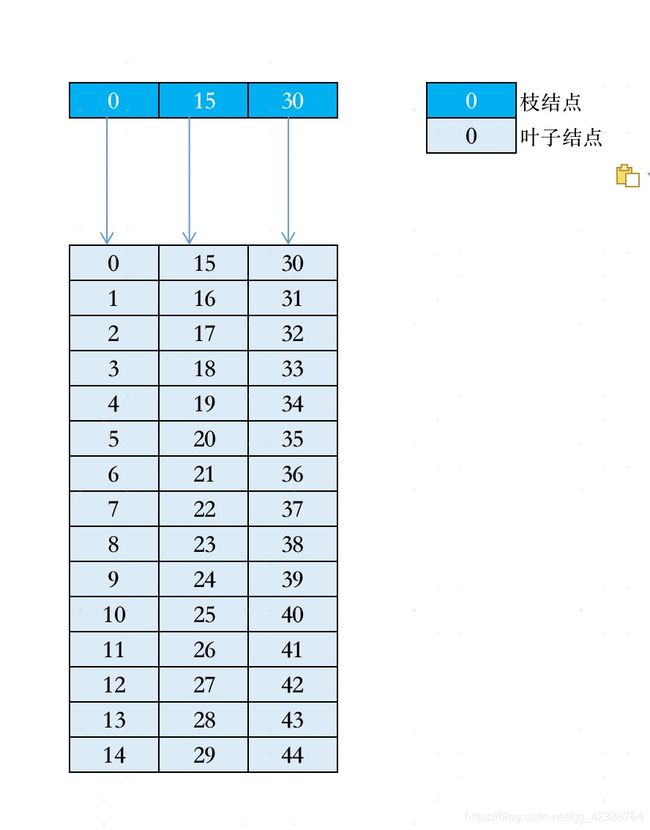
基于上述原理,mysql在设计的时候,使用B+树,在枝节点不存储数据,只存储引用,尽量减少数据大小,增加枝节点的数据个数。到这里,你就该明白,为什么B+树不在枝节点中存储数据了吧。
主键索引和辅助索引
讲了索引的数据结构,我们再来说一下主键索引和辅助索引。主键在建立时,就自带了主键索引。但是一个表里面,不可能只有主键索引,还有很多辅助索引。比如用户表,在建立时,除了对主键建立主键索引,我们还会对省市区来做索引,或者对用户的一些属性做索引。那么如果每个索引都按照B+树的原理,在叶子结点存储全量表数据,那么在磁盘中不就有了很多分数据的拷贝?这无疑浪费了内存。
事实上,mysql在实现的时候,区分了主键索引和辅助索引。只有主键索引的叶子结点存储了真实数据,而辅助索引的叶子结点存储的是主键值。于是,这又引发了另外一个问题,所有的查询,最终都是要走到主键索引上。即使是按辅助索引查找数据,找到了主键值之后,还是要按主键值去主键索引中找到真正的数据,于是主键索引的性能尤为重要。
解答
有了上面的知识做铺垫,我们再来解答为什么要有非业务主键,以及为什么不能用业务主键代替非业务主键。
为什么有非业务主键
我们在建表的时候,一般都会键一个int(或者Bigint)类型的字段,并且设置为自增,并将这个字段设置为主键。这就是我们说的非业务主键,这个值其实没有业务含义,只是作为数据表的真实主键存在。下面说明几个问题:
1,为什么是int类型
int类型占4个字节,表示范围为:-2147483648~2147483647,如果我们只用正数部分,也可以表示21亿以上的数据。
而如果采用varhcar型,"2147483647"这个字符串占据的字节数远远超过4个字节(具体多少依据字符集而定)。
根据上面的知识点,我们可以知道,辅助索引的叶子结点存储的都是主键值,如果主键采用varchar类型,那么将大大减少辅助索引的叶子结点数据量,消耗查询性能。
2,为什么是自增
关于这个问题,需要了解B+树的插入原理。B+树在插入时,会先按照查找过程,查到这个数据的位置,然后将数据插入到指定位置。插入完成后,如果叶子结点数据达到最大,则会触发分裂逻辑,将叶子结点的数据对半分裂成两个叶子结点,并重新整理枝结点。具体可以参照我的这篇文章
mysql对B+树插入逻辑的优化
因为对半分裂会引发存储浪费,所以mysql对B+树的插入做了优化,优化后,新插入的结点引发分裂,如果是最后,则把新插入的结点写到新的叶子结点,否则,把新结点插入到后面一个叶子结点中。插入后,后继叶子结点达到饱和,则继续分裂。最后调整枝结点。
因为B+树是一个有序树,所以如果每次加入的都是最大值,那么叶子结点达到最大时,只会分裂最后的叶子结点,并调整枝结点引用。
但是,如果插入的数据不是有序的,而是乱序的,那么下一个结点如果定位到中间的叶子结点,并触发了结点分裂。假设这个叶子结点后面的叶子结点全部达到饱和,则会触发很多的叶子结点的分裂合并,拖慢索引的插入效率。
因此,索引值采用自增,是为了提高索引的插入效率。特别是当数据了巨大时,效率提升尤为明显。
为什么业务主键不能取代非业务主键
基于上面为什么要有非业务主键,我想这个问题就迎刃而解。因为业务主键,因为需要包含业务含义,所以只能是varchar类型,并且是按照一定规则生成的,必定是无序的。这两点,都是不适合作为表数据的主键的原因。也决定了业务主键不能代替非业务主键,作为数据表的真正意义上的主键。
关于mysql的B+树的插入及分裂逻辑,先挖个坑,后面再做分享。
以上内容,如有不正,还望指出。