数据库中间件
文章目录
- 一.基本概念
-
- 1.1 垂直切分
- 1.2 水平切分
- 1.3 应用
- 二. ShardingSphere-JDBC读写分离
-
- 2.1 一主多从配置
- 2.2 核心配置
- 2.3 事务
- 三.ShardingSphere-JDBC垂直分片
-
- 3.1 数据库
- 3.2 核心配置
- 3.3 测试
- 四.ShardingSphere-JDBC水平分片
-
- 4.1 数据库
- 4.2 基本配置
- 4.3 标椎分片表配置
- 4.4 分片算法配置
- 4.5 分布式序列算法
- 4.6 多表关联
一.基本概念
1.1 垂直切分
垂直切分包括垂直分表和垂直分库;
垂直分库就是根据业务耦合性,将关联度低的不同表存储在不同的数据库,类似于微服务项目中根据业务创建不同的服务

垂直分表是基于数据库中的"列"进行,某个表字段较多,可以新建一张扩展表,将不经常用或字段长度较大的字段拆分出去到扩展表中。

优缺点
优点:
1.可根据业务进行拆分
2.便于对不同业务的数据进行管理和维护
3.高并发场景下,垂直切分一定程度的提升IO、数据库连接数、单机硬件资源的瓶颈
缺点:
1.部分表无法join,只能通过接口聚合方式解决,提升了开发的复杂度
2.分布式事务处理复杂
3.依然存在单表数据量过大的问题(需要水平切分)
1.2 水平切分
当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平切分了。
水平切分包括水平分表和水平分库;
水平分表
将同一个表按不同的条件分散到多个表中,每个表中只包含一部分数据,从而使得单个表的数据量变小.
库内分表只解决了单一表数据量过大的问题,但没有将表分布到不同机器的库上,因此对于减轻MySQL数据库的压力来说,帮助不是很大,大家还是竞争同一个物理机的CPU、内存、网络IO,最好通过分库分表来解决。
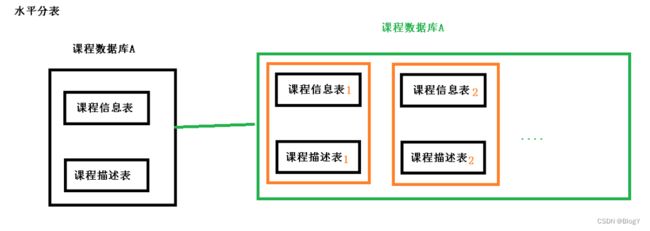
水平分库

优缺点
优点:
1.不存在单库数据量过大、高并发的性能瓶颈,提升系统稳定性和负载能力
2.应用端改造较小,不需要拆分业务模块
缺点:
1.跨分片的事务一致性难以保证
2.跨库的join关联查询性能较差
3.数据多次扩展难度和维护量极大
1.3 应用
(1)在数据库设计时候考虑垂直分库和垂直分表
(2)随着数据库数据量增加,不要马上考虑做水平切分,首先考虑缓存处理,读写分离,使用索引等等方式,如果这些方式不能根本解决问题了,再考虑做水平分库和水平分表
二. ShardingSphere-JDBC读写分离
2.1 一主多从配置
具体配置过程可参考下面文章
参考链接
binlog格式说明:
- binlog_format=STATEMENT:日志记录的是主机数据库的
写指令,性能高,但是now()之类的函数以及获取系统参数的操作会出现主从数据不同步的问题。 - binlog_format=ROW(默认):日志记录的是主机数据库的
写后的数据,批量操作时性能较差,解决now()或者 user()或者 @@hostname 等操作在主从机器上不一致的问题。 - binlog_format=MIXED:是以上两种level的混合使用,有函数用ROW,没函数用STATEMENT,但是无法识别系统变量
binlog-ignore-db和binlog-do-db的优先级问题:


2.2 核心配置
# 应用名称
spring.application.name=sharging-jdbc-demo
# 开发环境设置
spring.profiles.active=dev
# 内存模式
spring.shardingsphere.mode.type=Memory
# 配置真实数据源
spring.shardingsphere.datasource.names=master,slave1,slave2
# 配置第 1 个数据源
spring.shardingsphere.datasource.master.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master.jdbc-url=jdbc:mysql://192.168.1.110:3307/test?useUnicode=true&characterEncoding=utf8
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master.username=root
spring.shardingsphere.datasource.master.password=root
# 配置第 2 个数据源
spring.shardingsphere.datasource.slave1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave1.jdbc-url=jdbc:mysql://192.168.1.110:3308/test?useUnicode=true&characterEncoding=utf8
spring.shardingsphere.datasource.slave1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave1.username=root
spring.shardingsphere.datasource.slave1.password=root
# 配置第 3 个数据源
spring.shardingsphere.datasource.slave2.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave2.jdbc-url=jdbc:mysql://192.168.1.110:3309/test?useUnicode=true&characterEncoding=utf8
spring.shardingsphere.datasource.slave2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave2.username=root
spring.shardingsphere.datasource.slave2.password=root
# 读写分离类型,如: Static,Dynamic
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.type=Static
# 写数据源名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.write-data-source-name=master
# 读数据源名称,多个从数据源用逗号分隔
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.read-data-source-names=slave1,slave2
# 负载均衡算法名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.load-balancer-name=alg_round
# 负载均衡算法配置
# 负载均衡算法类型
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_round.type=ROUND_ROBIN
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_random.type=RANDOM
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.type=WEIGHT
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave1=1
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave2=2
# 打印SQl
spring.shardingsphere.props.sql-show=true
2.3 事务
为了保证主从库间的事务一致性,避免跨服务的分布式事务,ShardingSphere-JDBC的主从模型中,事务中的数据读写均用主库。
- 不添加@Transactional:insert对主库操作,select对从库操作
- 添加@Transactional:则insert和select均对主库操作
- 注意:在JUnit环境下的@Transactional注解,默认情况下就会对事务进行回滚(即使在没加注解@Rollback,也会对事务回滚)
三.ShardingSphere-JDBC垂直分片
3.1 数据库

3.2 核心配置
# 应用名称
spring.application.name=sharding-jdbc-demo
# 环境设置
spring.profiles.active=dev
# 配置真实数据源
spring.shardingsphere.datasource.names=user,order
# 配置第 1 个数据源
spring.shardingsphere.datasource.user.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.user.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.user.jdbc-url=jdbc:mysql://192.168.1.110:3307/test?useUnicode=true&characterEncoding=utf8
spring.shardingsphere.datasource.user.username=root
spring.shardingsphere.datasource.user.password=root
# 配置第 2 个数据源
spring.shardingsphere.datasource.order.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.order.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.order.jdbc-url=jdbc:mysql://192.168.1.110:3306/gu?useUnicode=true&characterEncoding=utf8
spring.shardingsphere.datasource.order.username=root
spring.shardingsphere.datasource.order.password=root
# 标准分片表配置(数据节点)
# spring.shardingsphere.rules.sharding.tables.-name>.actual-data-nodes=值
# 值由数据源名 + 表名组成,以小数点分隔。
# <table-name>:逻辑表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=user.t_user
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order.t_order
# 打印SQL
spring.shardingsphere.props.sql-show=true
3.3 测试
@Test
public void testInsertOrderAndUser(){
User user = new User();
user.setUname("强哥");
userMapper.insert(user);
Order order = new Order();
order.setMoney("100");
orderMapper.insert(order);
}
四.ShardingSphere-JDBC水平分片
4.1 数据库


注意:水平分片的id需要在业务层实现,不能依赖数据库的主键自增
4.2 基本配置
#========================基本配置
# 应用名称
spring.application.name=sharging-jdbc-demo
# 开发环境设置
spring.profiles.active=dev
# 内存模式
spring.shardingsphere.mode.type=Memory
# 打印SQl
spring.shardingsphere.props.sql-show=true
#========================数据源配置
# 配置真实数据源
spring.shardingsphere.datasource.names=server-user,server-order0,server-order1
# 配置第 1 个数据源
spring.shardingsphere.datasource.server-order0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.server-order0.jdbc-url=jdbc:mysql://192.168.1.110:3306/gu?useUnicode=true&characterEncoding=utf8
spring.shardingsphere.datasource.server-order0.username=root
spring.shardingsphere.datasource.server-order0.password=root
# 配置第 2 个数据源
spring.shardingsphere.datasource.server-order1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.server-order1.jdbc-url=jdbc:mysql://192.168.1.110:3307/test?useUnicode=true&characterEncoding=utf8
spring.shardingsphere.datasource.server-order1.username=root
spring.shardingsphere.datasource.server-order1.password=root
# 配置第 3 个数据源
spring.shardingsphere.datasource.server-user.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-user.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.server-user.jdbc-url=jdbc:mysql://192.168.1.110:3308/test?useUnicode=true&characterEncoding=utf8
spring.shardingsphere.datasource.server-user.username=root
spring.shardingsphere.datasource.server-user.password=root
4.3 标椎分片表配置
#========================标准分片表配置(数据节点配置)
# spring.shardingsphere.rules.sharding.tables.-name>.actual-data-nodes=值
# 值由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。
# <table-name>:逻辑表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=server-user.t_user
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order1.t_order1
# spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order0.t_order ,server-order0.t_order1,server-order1.t_order,server-order1.t_order1
测试:保留上面配置中的一个分片表节点分别进行测试,检查每个分片节点是否可用
/**
* 水平分片:插入数据测试
*/
/**
* 水平分片:插入数据测试
*/
@Test
public void testInsertOrder(){
Order order = new Order();
order.setMoney("11111");
orderMapper.insert(order);
}
4.4 分片算法配置
#========================标准分片表配置(数据节点配置)
# spring.shardingsphere.rules.sharding.tables.-name>.actual-data-nodes=值
# 值由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。
# <table-name>:逻辑表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=server-user.t_user
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order$->{0..1}.t_order$->{0..1}
#------------------------分库策略
# 分片列名称 选择根据哪一列进行分片
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=user_id
# 分片算法名称 选择哪种算法进行分片
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=alg_mod
#------------------------分片算法配置
# 行表达式分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_inline_userid.type=INLINE
# 分片算法属性配置 路由到哪个数据源取决于userId
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_inline_userid.props.algorithm-expression=server-order$->{user_id % 2}
# 取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_mod.type=MOD
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_mod.props.sharding-count=2
#------------------------分表策略
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=money
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=alg_hash_mod
#------------------------分片算法配置
# 哈希取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.type=HASH_MOD
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.props.sharding-count=2
分库分表测试
/**
* 水平分片:分库分表插入数据测试
*/
@Test
public void testInsertOrderTableStrategy(){
for (long i = 1; i < 5; i++) {
Order order = new Order();
order.setMoney("ATGUIGU" + i);
order.setUserId(1L);
orderMapper.insert(order);
}
for (long i = 5; i < 9; i++) {
Order order = new Order();
order.setMoney("ATGUIGU" + i);
order.setUserId(2L);
orderMapper.insert(order);
}
}
通过userId(2)取余之后,ATGUIGU5~8分配在server-order0的库,然后通过money列取哈希之后分配在不同的表


通过userId(1)取余之后,ATGUIGU5~8分配在server-order0的库,然后通过money列取哈希之后分配在不同的表


查询测试
/**
* 水平分片:根据user_id查询记录
* 查询了一个数据源,每个数据源中使用UNION ALL连接两个表
*/
@Test
public void testShardingSelectByUserId(){
QueryWrapper<Order> orderQueryWrapper = new QueryWrapper<>();
orderQueryWrapper.eq("user_id", 1L).or().eq("user_id", 2L);
List<Order> orders = orderMapper.selectList(orderQueryWrapper);
orders.forEach(System.out::println);
}

4.5 分布式序列算法
雪花算法:
水平分片需要关注全局序列,因为不能简单的使用基于数据库的主键自增。
这里有两种方案:一种是基于MyBatisPlus的id策略;一种是ShardingSphere-JDBC的全局序列配置。
基于MyBatisPlus的id策略:将Order类的id设置成如下形式
@TableId(type = IdType.ASSIGN_ID)
private Long id;
基于ShardingSphere-JDBC的全局序列配置:
#------------------------分布式序列策略配置
# 分布式序列列名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=alg_snowflake
# 分布式序列算法配置
# 分布式序列算法类型
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
# 分布式序列算法属性配置
#spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.props.xxx=
此时,需要将实体类中的id策略修改成以下形式:
//当配置了shardingsphere-jdbc的分布式序列时,自动使用shardingsphere-jdbc的分布式序列
//当没有配置shardingsphere-jdbc的分布式序列时,自动依赖数据库的主键自增策略
@TableId(type = IdType.AUTO)
4.6 多表关联
创建关联表
在server-order0、server-order1服务器中分别创建两张订单详情表t_order_item0、t_order_item1
我们希望同一个用户的订单表和订单详情表中的数据都在同一个数据源中,避免跨库关联,因此这两张表我们使用相同的分片策略。
那么在t_order_item中我们也需要创建order_no和user_id这两个分片键
CREATE TABLE t_order_item0(
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
price DECIMAL(10,2),
`count` INT,
PRIMARY KEY(id)
);
CREATE TABLE t_order_item1(
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
price DECIMAL(10,2),
`count` INT,
PRIMARY KEY(id)
);