算法工程师面试题总结
1.Python is 和 == 有什么区别?
a==b判断两个对象a和b的内容是否相等,默认调用__eq__()函数
a is b判断a和b是否为同一个地址,即判断id(a)==id(b)。例如:
a = 2, b =2 a==b输出[True] a is b输出[True]
c = 257 d = 257 c==d输出[True] c is d输出[False]
对于整数对象,Python把一些频繁使用的整数对象缓存起来,保存到一个叫small_ints的链表中,在Python的整个生命周期内,任何需要引用这些整数对象的地方,都不再重新创建新的对象,而是直接引用缓存中的对象。python规定-5到256的整数较为常用,但凡是需要用些小整数时,就从这里面取,不再去临时创建新的对象。因为257不再小整数范围内,因此尽管a和b的值是一样,但是他们在Python内部却是以两个独立的对象存在的,各自为政,互不干涉。但是尽管这里a和b是公用一个地址,但是如果对b进行操作,改变了数值,并不会对a进行操作。当然,如果c=257, d = c这样的操作,d和c依然是一个id。
c = 257
def foo():
... a = 257
... b = 257
... print a is b
... print a is c
输出True和False。这是因为在同一个代码块中,Python出于对性能的考虑,但凡是不可变对象,(在python中,整数、字符串都是不可变对象)在同一个代码块中的对象,只有是值相同的对象,就不会重复创建,而是直接引用已经存在的对象。
对于列表、矩阵的赋值,则默认是传递地址。并且对一方的操作会改变另一方。
x=[1,2]
y=x
print(y is x)
y[0]=0
print(y is x)
输出结果为True 和True. 若想深层复制,请用y=x.copy()
2. Maxpooling和Meanpooling怎么反向传播?两者有什么优缺点?池化层有什么作用?
max pooling反向传播时,将当前神经元的梯度值传递到前一层最大元素对应的神经元,其余的神经元梯度值为0。mean传播时,将当前神经元的值平均分配到参与计算的所有神经元。
最大池化保留了纹理特征,平均池化保留整体的数据特征. 如果背景白色,辨别内容黑色,则应该用平均池化,因为最大池化会把黑色的辨识体抹去。相反如果背景黑色,字体白色,例如MNist数据集,应该用最大池化。


3.智力题:有1000瓶酒,其中只有一瓶有毒。现在用小白鼠进行实验,小白鼠只要服用任意量有毒酒就会在24小时内死亡。问最少要用多少只小白鼠进行实验才能在24小时内检测出哪瓶药水有毒?
用10只小白鼠表示十位二进制的每一位。对于每一瓶酒,将其序号转化为二进制数,对应1的小白鼠喝酒,对应0的不喝。24小时后,死去的小白鼠代表1,没有死去的代表0,所得到的数字就是有毒的那瓶酒的编号。
4.算法题:给你一个很大的文件,文件里有很多行数据,每一行数据是一个用户的uid,表示这个用户点开过抖音,请你找出打开抖音次数最频繁的前10个用户。
hash1, hash2 = {},{}
for ID in data:
if ID in hash1:
hash1[ID] += 1
else:
hash1[ID] = 1
if len(hash2)<10:
hash2[ID] = hash1[ID]
else:
(key, value)=min(zip(hash2.keys(),hash2.values()),key=lambda x:x[1])
if hash1[ID]>value:
del hash2[key]
hash2[ID]=hash1[ID]5.熟悉的机器学习算法?
按照学习历程来讲,逻辑回归、LDA、QDA、朴素贝叶斯、决策树、KNN、支持向量机SVM、集成学习Bagging Boosting Stacking(bootstraping ada-boost 随机森林)、MLP(multilayer perceptron)多层感知器(其实就是feed-forward NN)
6.描述一下朴素贝叶斯算法.
朴素贝叶斯是一种生成式学习方法。
P(y|x)=P(x|y)*P(y)/P(x) 而对于每一个x,P(x)是固定的,我们只需要比较P(x|y)*P(y)
朴素贝叶斯朴素假设所有特征之间均条件独立。
![]()
![]()
伯努利朴素贝叶斯(BNB)比较简单,所有feature只有0和1之分。
训练阶段:计算每个类别出现的概率P(y)、计算每个类别每个特征出现的概率P(xi|y)。
测试阶段:对于一个变量,P(y|x)正比于P(x|y)P(y),算出每个y对应的概率,取最大者。
在训练的时候,需要对参数做一个平滑:

原因是数据不足的情况下,有些feature的在某一类数据中出现的概率为0,那么在预测的时候,任何一个出现了该feature的数据出现的概率都为0,这是很不合理的,我们只能说它出现的概率应该很低,而不是为0。所以需要做个平滑。
此外还有多项式朴素贝叶斯和高斯朴素贝叶斯。前者统计出现次数,求概率的时候只统计出现概率不统计不出现概率。高斯朴素贝叶斯则是针对连续性变量来说的。
多项式朴素贝叶斯(MNB)和伯努利朴素贝叶斯训练阶段计算先验概率P(y)的方式是一样的,计算P(xi|y)不一样,MNB是通过计算(y=1的情况下,特征xi出现的总次数)+1/(y=1的词语总数)+特征总数 来计算P(xi=1|y=1)的(分子+1是平滑), 即BNB是计算该类别下出现该特征的概率,MNB是计算该类别下该特征出现总次数的比重。
测试阶段也不一样:
假设x=(1,0,1,1)
BNB: P(y|x)=P(x|y)*P(y)=P(x1=1|y)*P(x2=0|y)*P(x3=1|y)*P(x4=1|y)*P(y)
假设x=(2,0,1,3)
MNB: P(y|x)=P(x|y)*P(y)=P(x1=1|y)^2*P(x3=1|y)*P(x4=3|y)^3
7.描述一下逻辑回归算法.
逻辑回归本质上就是对log-adds ratio进行线性回归。普通的回归算法是根据数据模拟一条曲线,而逻辑回归作为分类算法同样是模拟一条曲线,在这条曲线之上预测为1,否则为0。
![]()
这么做的动机是log-adds ratio取值范围是整个实数集,所以可以用一条直线取模拟它的取值。
逻辑回归是一个典型的判别式模型,直接对P(y|x)进行估计和建模。
![]()
![]()
![]()
![]()
训练的时候,利用以下公式即可
![]()
手撕LR算法的话,注意将偏移项b当成w_0,将输入数据的feature加一个全1项即可。
8.算法题:请对输入字符串做如下处理,AAA改成AA, AABB改成AAB
用re正则表达式.
"(.)\\1+"表示某个字符出现超过一次。先将所有超过一次的变成不超过两个。
"(.)\\1+(.)\\2+"表示AABB式字符串,全改成\\1\\1\\2即可。
N = int(input())
import re
for i in range(N):
word = input()
word = re.sub("(.)\\1+","\\1\\1",word)
word = re.sub("(.)\\1+(.)\\2+","\\1\\1\\2",word)
print(word)9. C++中NULL和nullptr有什么区别?
在C语言中,NULL通常被定义为:#define NULL ((void *)0)
所以说NULL实际上是一个空指针,如果在C语言中写入以下代码,编译是没有问题的,因为在C语言中把空指针赋给int和char指针的时候,发生了隐式类型转换,把void指针转换成了相应类型的指针。
int *pi = NULL; void指针变成了int指针
char *pc = NULL; void指针变成了char指针
以上代码如果使用C++编译器来编译则是会出错的,因为C++是强类型语言,void*是不能隐式转换成其他类型的指针的. NULL在C++中就是0,这是因为在C++中void* 类型是不允许隐式转换成其他类型的,所以之前C++中用0来代表空指针,但是在重载整形的情况下,会出现问题,即若函数重载的输入类型一个是int *另一个是void *,将NULL作为空指针输入时,会调用int *函数,这和我们的初衷违背。所以,C++11加入了nullptr,可以保证在任何情况下都代表空指针,而不会出现上述的情况,因此,建议以后还是都用nullptr替代NULL吧,而NULL就当做0使用。
10.机器学习中生成式学习generative learning和判别式学习discriminative learning有什么区别
判别式学习尝试直接找到一个判定域,在这个判定域大于0的时候P(y=1|x)>P(y=0|x),反之亦然。
生成式学习尝试对每一个类别,找出该类别的分布。即用模型估计P(x|y=y_i)。随后用贝叶斯公式求P(y|x)。这样做的好处是,当预测的行为发生变化时,每个类别的分布并未变化。例如,预测垃圾邮件模型中,假设用判别式学习到了一个判定域,但是如果写垃圾邮件的人将频率提高1000倍,则必须重新估计P(y|x),而利用生成式学习则不需要,因为无论这个人写垃圾邮件快慢,垃圾邮件和非垃圾邮件各自的概率分布是没有变化的,因此我们只需要重新评估P(y)这个后验概率。
总结来说:判别式学习有如下特点:
- 对条件概率建模,学习不同类别之间的最优边界。
- 捕捉不同类别特征的差异信息,不学习本身分布信息,无法反应数据本身特性。
- 学习成本较低,需要的计算资源较少。
- 需要的样本数可以较少,少样本也能很好学习。
- 预测时拥有较好性能。
- 无法转换成生成式。
生成式学习有如下特点:
- 对联合概率建模,学习所有分类数据的分布。
- 学习到的数据本身信息更多,能反应数据本身特性。
- 学习成本较高,需要更多的计算资源。
- 需要的样本数更多,样本较少时学习效果较差。
- 推断时性能较差。
- 一定条件下能转换成判别式。
判别式学习的例子: 逻辑回归、感知器(Perceptron)、SVM、决策树、KNN
生成式学习的例子: LDA、QDA、朴素贝叶斯
11.什么是二叉搜索树?有什么用途
它或者是一棵空树,或者是具有下列性质的二叉树: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值; 它的左、右子树也分别为二叉排序树。二叉搜索树作为一种经典的数据结构,它既有链表的快速插入与删除操作的特点,又有数组快速查找的优势;所以应用十分广泛,例如在文件系统和数据库系统一般会采用这种数据结构进行高效率的排序与检索操作。
12.什么是平衡二叉树?有什么用途
平衡二叉树指所有结点的左右子树的高度相差不超过1。在二叉搜索树的插入和删除运算中,采用平衡树的优点是:使树的结构较好,从而提高查找运算的速度。缺点是:是插入和删除运算变得复杂化,从而降低了他们的运算速度。
13.K-fold交叉验证,K的大小对bias和variance有什么影响?
k-fold交叉验证常用来确定不同类型的模型(线性、指数等)哪一种更好,为了减少数据划分对模型评价的影响,最终选出来的模型类型(线性、指数等)是k次建模的误差平均值最小的模型。当k较大时,经过更多次数的平均可以学习得到更符合真实数据分布的模型,Bias就小了,但是这样一来模型就更加拟合训练数据集,再去测试集上预测的时候预测误差的期望值就变大了,从而Variance就大了;反之,k较小时模型不会过度拟合训练数据,从而Bias较大,但是正因为没有过度拟合训练数据,Variance也较小。
14.讲讲深度学习的梯度爆炸和梯度消失问题?可以如何解决?
梯度消失或爆炸指的是反向传播时,由于网络深度很大,每一层的梯度值不稳定,有可能出现传播过深时,梯度过小或过大,影响靠前网络参数的更新。梯度爆炸可以用加一个门限值的方法解决,但梯度消失是一个棘手的问题,它会导致前层网络权值参数更新过于缓慢。具体来说,输出层对某一层的梯度值是中间几层权值参数的乘积乘以这几层激活函数的导数以及该层输入参数决定的,即
![]()

①初始的时候往往初始化|w|的值是比较小的,经过连续乘积到了输入层有可能变得特别小,即梯度消失。梯度爆炸也同理。
②当使用sigmoid或tanh函数时,若x已经进入饱和区,深层网络不断移动输入值,导致靠前网络导数值都会约等于0,连续乘积引发梯度消失。
对于一个含有三层隐藏层的简单神经网络来说,当梯度消失发生时,接近于输出层的隐藏层由于其梯度相对正常,所以权值更新时也就相对正常,但是当越靠近输入层时,由于梯度消失现象,会导致靠近输入层的隐藏层权值更新缓慢或者更新停滞。这就导致在训练时,只等价于后面几层的浅层网络的学习。
尤其是对于RNN网络来讲,当输入序列过长的时候,也会出现梯度消失或者爆炸。
解决方法:
可以引入残差块。residual block即skip connection。这样每一层的梯度都至少有一个+1,不至于变得太小,其次残差块还能保存前一层的信息。即如下结构。可以看出,该层输出对输入的导数为权值参数+1,因此不会变得太小。上面的公式会变成如下:
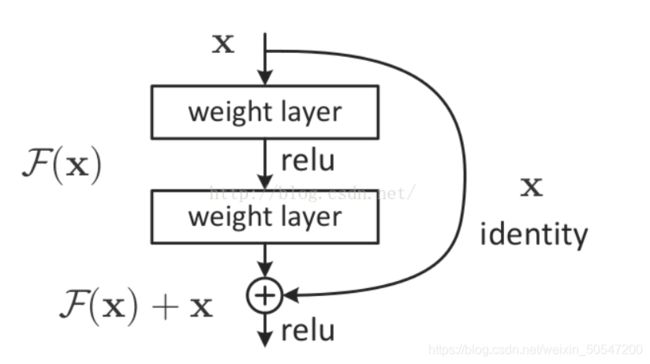
可以引入BN。如果使用sigmoid或tanh函数,当某层输入数据进入饱和区的时候,该层激活函数对输入的导数接近为0,导致梯度消失。BN可以强行将输入数据移动到非饱和区,同时还能保证该层输入数据不会过大或者过小,因为梯度是和该层输入也有关的。
使用ReLU,maxout等替代sigmoid: Relu函数的导数要么是1要么是0,而sigmoid的导数可能过多聚集在较小的值,乘积过多会导致梯度消失。实际上,sigmoid只有x在0附近才有较大的导数值(0.25)。
15.有哪些解决过拟合的方法?
①增加数据,最简单粗暴,过拟合其实就是根据训练数据出来的模型不能很好的适应测试数据。
②增加正则项,限制参数矩阵变得过大。一般来说,过拟合是因为模型训练的过于复杂,所以直观上来看模型曲线会变化很剧烈,因此需要很大的导数,进一步也就是参数会变得很大。
③神经网络增加drop_out。④k-fold交叉验证。⑤权值共享。例如卷积网络。
⑥batch normalization可以适当的减缓过拟合。因为它可以确保数据的分布不发生变化。
⑦集成学习。bagging boosting stacking,和交叉验证有点像,不听一家之言。
⑧早停early stopping,避免模型过于复杂。⑨在数据上或者参数上增加噪声。
16.一共有4种normalization分别是batch, layer, instance和group。解释它们的区别。
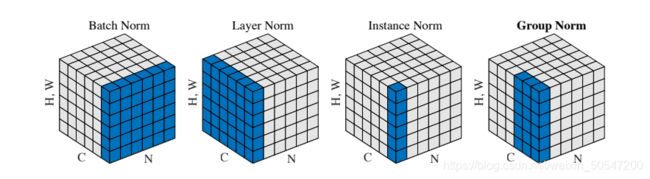
这里以三维数据(C,H,W)为例,其中C是channel,H,W分别为对应channel的图片的长和宽。
如果考虑batch size作为第四维,则为(N,C,H,W),不同的归一化仅仅是针对的维度不同,操作都是对每个元素进行(x-u)/σ,问题是谁的u,σ?
batch norm:对C归一化,即固定channel,对该channel的(N,H,W)求平均和方差,保证每一个channel在一个batch size内所有元素的平均值为0,方差为1。那么bn的目的是什么?在深层网络训练的过程中,由于网络中参数变化而引起内部结点数据分布发生变化,这一过程被称作Internal Covariate Shift。假设输入数据服从某个分布,那么刚开始输入的时候,每一层网络的输入都服从这个分布,但随着训练的加深,权重参数在不断变化,底层网络的一点点变化便可以引起深层网络的大幅度变化,导致深层网络输入数据的分布不断变化,而网络需要不停的适应输入分布的变化取训练网络,导致收敛速度很慢,bn保证了每一层网络的分布不发生变化,提高收敛速度。
layer norm: 这个好理解,也是刚学机器学习进行的最多的操作,即对N进行归一化,每一个输入数据(C,H,W), 保证该输入数据均值和方差为0和1。
instance norm: 即只针对一个数据的一个channel进行归一化。这也是数据预处理常用的归一化。
group norm: GN是针对bn在batch size太小的时候出现的方差均值不可靠而出现的。首先G是一个超参数,表示把每个channel分成多少个组,常取32。因此GN对batchsize中每一个数据都要进计算,统计的范围是C/G个channel,可以看出当G=1的时候,就是layer normalization,因此GN每次都对一个batch中N个数据的每一个进行C/G次归一化。
17.LSTM如何解决梯度消失的?LSTM和GRU有什么区别?
18.信息熵如何计算?


IG(Y|X) = H(Y)-H(Y|X)
19. GBDT(Gradient Boosting Decision Tree)和XGBoost有什么区别?
GBDT是用回归树来boosting的一种算法。和AdaBoost不同,Gradient Boost每一次的计算是为了减少上一次的残差(residual),而为了消除残差,我们可以在残差减少的梯度(Gradient)方向上建立一个新的模型。所以说,在Gradient Boost中,每个新的模型的建立是为了使得之前模型的残差往梯度方向减少。Shrinkage(缩减)的思想认为,每次走一小步逐渐逼近结果的效果,要比每次迈一大步很快逼近结果的方式更容易避免过拟合。即它不完全信任每一个棵残差树,它认为每棵树只学到了真理的一小部分,累加的时候只累加一小部分,通过多学几棵树弥补不足。本质上,Shrinkage为每棵树设置了一个weight,累加时要乘以这个weight,但和Gradient并没有关系。

传送门:ML-NLP/3.2 GBDT.md at master · NLP-LOVE/ML-NLP · GitHub
对于XGBOOST是一种改进的GBDT


机器不学习:机器学习时代三大神器GBDT、XGBoost、LightGBM (360doc.com)
(1条消息) 通俗理解kaggle比赛大杀器xgboost_结构之法 算法之道-CSDN博客
终于有人说清楚了--XGBoost算法 - mantch - 博客园 (cnblogs.com)
20.几种优化算法,SGD SGDM AdaGrad RMSProp Adam 说说异同
①SGD(Stochastic Gradient Descent)随机梯度下降,是最基本的求最值算法。
![]()
②SGDM (SGD with Momentum)是对SGD的改进。引入了动量概念,由于随机梯度下降中每次的梯度是由当前batch中所有samples计算得出的梯度求平均得到,它只能代表这一个batch中下降最快的方向,并不代表整个数据的梯度。因此,对过往计算过的梯度g_t-1,g_t-2,...,g_0求一个加权平均值。
![]()
通常取β=0.9,因此每次的动量由以0.9为公比的加权平均梯度计算得到。
SGD和SGDM算法有如下缺点:
1. 选择恰当的初始学习率很困难。
2. 学习率调整策略受限于预先指定的调整规则。
3. 相同的学习率被应用于各个参数。
4. 高度非凸的误差函数的优化过程,如何避免陷入大量的局部次优解或鞍点。
③AdaGrad(Adapative Gradient)自适应梯度,同样是对SGD的改进。虽然SGD很简单,但是有个明显的缺点是学习率固定,且每次更新对所有参数的学习率是一样的,没有区分。因此AdaGrad的思想就是随着迭代,逐渐减小学习率,并且保证每个参数的学习率是不一样的。
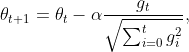
随着epoch的增加,分母越来越大,学习率逐渐变小,其次每一个参数g_t^i对应更新的学习率也不一样。
起到的效果是在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小),并且能够使得陡峭的方向变得平缓,从而加快训练速度。
频繁更新的梯度,则累积的分母项逐渐偏大,那么更新的步长(stepsize)相对就会变小,而稀疏的梯度,则导致累积的分母项中对应值比较小,那么更新的步长则相对比较大。
AdaGrad能够自动为不同参数适应不同的学习率(平方根的分母项相当于对学习率α进进行了自动调整,然后再乘以本次梯度),大多数的框架实现采用默认学习率α=0.01即可完成比较好的收敛。
优势:在数据分布稀疏的场景,能更好利用稀疏梯度的信息,比标准的SGD算法更有效地收敛。
缺点:主要缺陷来自分母项的对梯度平方不断累积,随之时间步地增加,分母项越来越大,最终导致学习率收缩到太小无法进行有效更新。
④RMSProp是对AdaGrad的改进,AdaGrad过于依赖以往所有计算过的梯度,这是不合理的,RMSProp仿照SGDM引入了二阶动量概念,
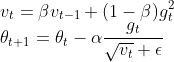
可以看出,引入二阶动量v, v并不会随着迭代变得过大,因为它实际上只近似依赖于前N个梯度。
优势:能够克服AdaGrad梯度急剧减小的问题,在很多应用中都展示出优秀的学习率自适应能力。尤其在不稳定(Non-Stationary)的目标函数下,比基本的SGD、Momentum、AdaGrad表现更良好。
⑤Adam是RMSProp的基础上再引入一阶动量。
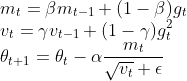
总结:上述5种优化器,本质上就是加入了一阶动量和二阶动量,加入一阶动量的目的是使得更新的梯度更可信,加入二阶动量的目的是使得学习率可以自适应调整。Adam优化器就是结合了SGD AdaGrad RMSProp产生的。
虽然Adam算法目前成为主流的优化算法,不过在很多领域里(如计算机视觉的对象识别、NLP中的机器翻译)的最佳成果仍然是使用带动量(Momentum)的SGD来获取到的。Wilson 等人的论文结果显示,在对象识别、字符级别建模、语法成分分析等方面,自适应学习率方法(包括AdaGrad、AdaDelta、RMSProp、Adam等)通常比Momentum算法效果更差。
Adam和SGDM的优缺点比较:
SGDM缺点是学习率固定,需要在训练过程中调整学习率。同时收敛速度较慢。
Adam有着调参容易 收敛速度快等优点,但是也存在经常被人吐槽的泛化性问题和收敛问题。
什么是泛化性?


原因分析: Adam二阶动量是固定时间窗口内的累积,随着时间窗口的变化,遇到的数据可能发生巨变,使得 v_t可能会时大时小,不是单调变化。这就可能在训练后期引起学习率的震荡,导致模型无法收敛。
Adams可能错失全局最优解. 自适应学习率算法可能会对前期出现的特征过拟合,后期才出现的特征很难纠正前期的拟合效果。
21.常用的声纹识别网络的DNN Pooling以及loss部分分别有什么常用模型?
DNN: TDNN及其变体 以及 CNN网络
①Extend-TDNN: 就是在每个TDNN层后面加了个全连接层
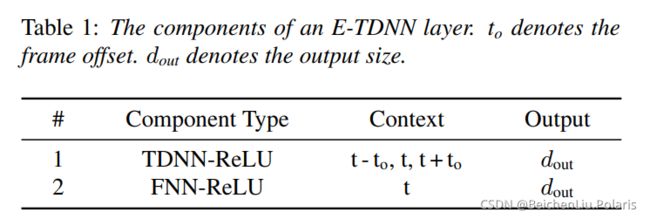
②Factorized-TDNN: 有待搞清楚
 ③R向量,这个用的是ResNet18和ResNet34的二维卷积网络来实现的
③R向量,这个用的是ResNet18和ResNet34的二维卷积网络来实现的
④ECAPA-TDNN:目前效果最好的TDNN。
Emphasized Channel Attention, Propagation and Aggregation。 所谓Emphasized Channel Attention其实就是把原先的scalar Attentive statistic pooling变成了vectorial attentive statistic pooling。每一个channel都有一个自己的权重。这个做法其实和pooling中的④完全一样,这两篇论文都是2020年的interspeech,我不太懂后者是怎么成功发表的。。。

 除此之外,他们还将全局信息和每一帧ht进行拼接
除此之外,他们还将全局信息和每一帧ht进行拼接

主网络用了如下的结构,称为SE-Res2Block
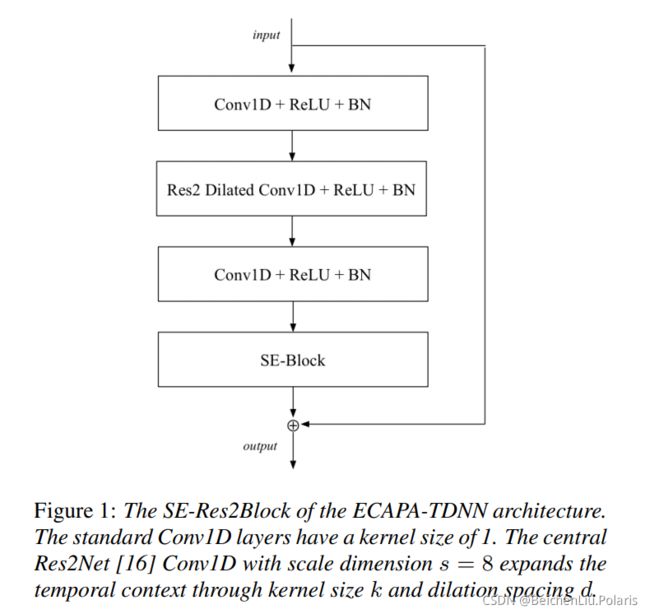
两个TDNN层包裹一个Res2Net。两个TDNN层类似于瓶颈层的作用,它们的卷积核尺寸均为1,第一个TDNN层减小channel的数量,第二个TDNN将channel的数量恢复。这样可以减少Res2Net层的参数。然后再经过一个Sequeeze-Excitation block。本质上就是给每一个维度乘上一个训练得出的标量s,其由frame-level的均值向量经过两个矩阵W训练得出。这一步的动机是作者嫌原先的TDNN的卷积核尺寸太小,不够关注全局信息,因此用SE将全局信息提取出来,交给原先的每一个维度的数据。

在池化的时候,作者认为不应该只用最后一层的特征来池化,应该也要用到浅层的特征。整个网络的结构如下。其中共有三层上述提到的SE-RES2 block。三个block的输出特征C*T (注意该block中因为有一个类似于瓶颈层的TDNN包裹,保持C不变)将三个输出聚集到一起,形成一个3*C*T的特征,再经过一个卷积核尺寸为1的TDNN,得到1536*T的特征,再进行pooling。最后使用的loss函数是AAM loss。具体可以见loss这部分内容。

Pooling:
①d-vector直接求平均值
②x-vector Statistic Pooling求每一个维度的均值和方差,拼接起来
③Attentive Statistic Pooling求加权均值和方差 给每一帧的维度向量一个权重,根据权重求加权的平均值和方差。权重用一个权重矩阵W和v训练得到,具体来说
输入H=[h1,h2,...,hT]∈N*T,ht∈N*1 对于每个ht,用权重矩阵W∈N*N和v∈1*N计算得到一个值,再将所有ht的值进行一个softmax,得到的即为每个ht的权重

 ④Attentive vector-based Statistic Pooling在一篇论文中提出,这种pooling方法认为用一个标量权重不合理,改用一个向量权重系数,很简单,用两个W训练即可:
④Attentive vector-based Statistic Pooling在一篇论文中提出,这种pooling方法认为用一个标量权重不合理,改用一个向量权重系数,很简单,用两个W训练即可:
 同时,作者为了改善性能,引入了transformer的多头机制,
同时,作者为了改善性能,引入了transformer的多头机制,
原文说的是这样的好处是可以让这个向量权重模型学习到多个方面

作者还提出,如果用这种多头机制,需要加入一个正则项保证每个头之间有差异

⑤Self-attentive pooling于2018年提出 其实本质上和attentive statistic pooling差不多。
唯一的区别就是她引入了多头机制,以及它没有涉及方差的计算,仅仅是一个加权均值。

⑥self multi-head attention pooling 于2019年提出。这个是和⑤有点像,将每一个ht分成k份,认为有k个头,对每个头有一个相应的uk ,然后对应的头有不同的权重。这个其实本质上就是弱化版的向量权重系数的训练,如果k恰好等于ht的维度N,那么其实就变成训练一个向量参数了。
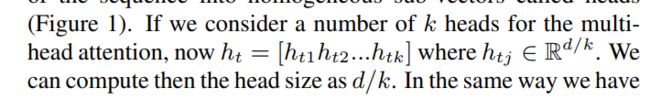

Loss: 交叉熵损失函数、ROC loss等
triplet loss:同一个说话人不同的音频的embedding应该相似,不同说话人相同的音频的embedding应该相差较大。以这样的损失函数去进行训练。

22.CTC LOSS的尖峰效应解释一下?



23. CNN网络的高性能计算方法?
24.残差网络的作用是什么?
一个是解决梯度消失问题。另一个是解决网络退化问题。因为深度网络去拟合恒等函数的效果不好,或者说网络较难以去实现恒等函数H(x)=x. 所谓的残差网络,就是引入一个shortcut,让网络去拟合H(x) = x+F(x) = x 即让网络去实现F(x)=0这个函数。结果表明0函数是比较好训练的,而且这样加入x并没有提高计算量。
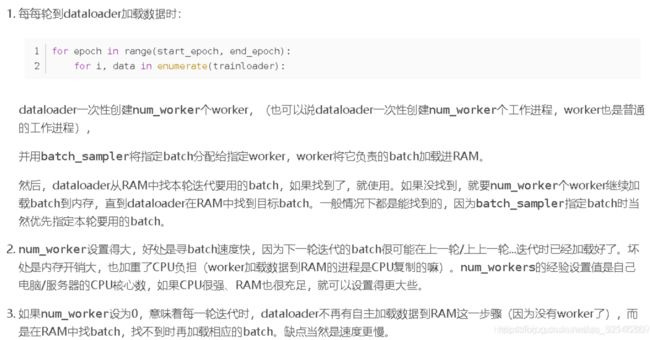
25.Pytorch num_of_worker的作用?
26.L1和L2正则化的区别
L1正则化可以对特征进行选择,训练出稀疏的参数,且鲁棒性更好,对异常值不敏感,可能存在多个解
L2正则化偏向于训练出各项比较均衡的参数,鲁棒性较差,若异常值>1,则会经过平方放大,即对异常值比较敏感,但其有闭式导数,便于计算。



27.支持向量机SVM为何在训练完成以后可以去掉非支持向量的样本?
28.关于ROC的理解,如果将测试集的数据加入训练集,则ROC曲线会发生怎样的变化?
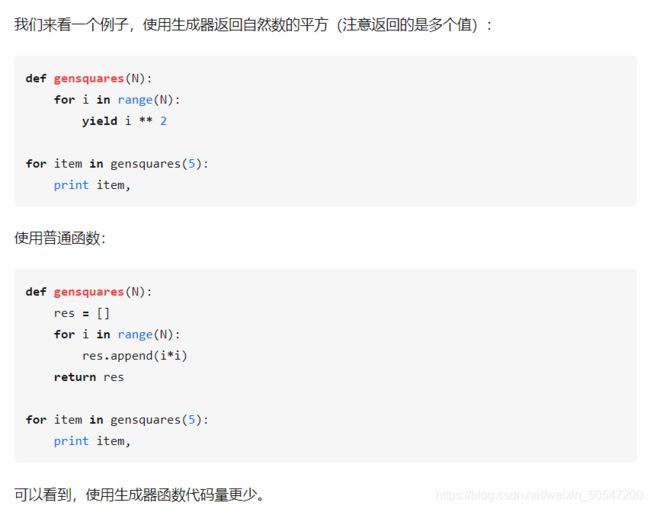
29.Python中生成器的好处是什么?
生成器可以大大节省内存空间,且遍历过之后即会被释放。
[i for i in range(100000000)]这句代码要执行很长时间,因为它要生成完整数组保存在内存当中。
(i for i in range(100000000))这句代码可以瞬间完成,返回一个生成器,需要的时候取数据即可。


30.操作系统OS中,进程和线程的关系是怎样的?
进程和线程都是一个时间段的描述,是CPU工作时间段的描述。是运行中的程序指令的一种描述,这需要与程序中的代码区别开来。




huhu