【文本聚类】三种聚类算法实现影评的情感分析(K-Means,Agglomerative,DBSCAN)
文本处理
from nltk.corpus import movie_reviews
# ([...], pos)
# ([...], neg)
documents = [(list(movie_reviews.words(fileid)), category) for category in movie_reviews.categories() for fileid in movie_reviews.fileids(category)]
# 将documents「随机化」,为组成训练集和测试集作准备
import random
random.shuffle(documents)
# 挑出词频最高的2000个词,作为「特征词」 (其实去掉停词,去掉标点符号,还剩大概1800个词)
import nltk
from nltk.corpus import stopwords
import string
word_fd = nltk.FreqDist(w.lower() for w in movie_reviews.words()).most_common(2000) # 词频最高的前2000个(词+频度)
feature_words = [w for (w, _) in word_fd if w not in stopwords.words("english") and w not in string.punctuation] # 处理后最终的特征词列表
# 文本处理(用的是多个document文件,返回的正好是训练需要的二维数组)
import numpy as np
features = np.zeros([len(documents), len(feature_words)], dtype = float)
for i in range(len(documents)):
document_words = set(documents[i][0])
for j in range(len(feature_words)):
features[i, j] = 1 if (feature_words[j] in document_words) else 0
# 通过除以标准差,归一化各维度的变化尺度————将特征预处理为「白噪声」
from scipy.cluster.vq import whiten
features = whiten(features)
文本聚合
# K-Means聚合————一种划分聚合
from scipy.cluster.vq import vq, kmeans
centroids, _ = kmeans(features, 2)
Kmeans_cluster_res, _ = vq(features, centroids)
# Agglomerative聚合————一种层级聚合
from scipy.cluster.hierarchy import linkage, fcluster
agg = linkage(features, method='single', metric='euclidean')
Agg_cluster_res = fcluster(agg, 50, criterion='distance')
# DBSCAN聚合————一种密度聚合
from sklearn.cluster import DBSCAN
DBSCAN_cluster_res = DBSCAN(eps=50, min_samples=3, metric='euclidean').fit(features).labels_
评估测试
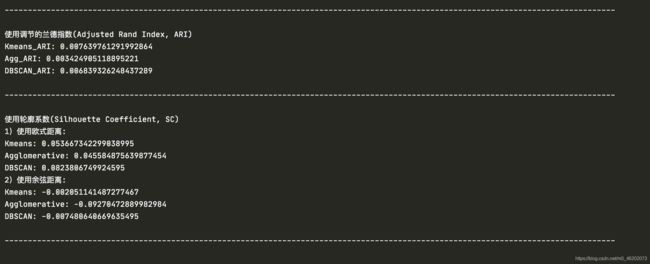
▶ 调节的兰德指数(Adjusted Rand Index, ARI) ——— 需要真实的分类标签
# 获取目标值
target = [c for (_, c) in documents]
target = [1 if c == 'pos' else 0 for c in target]
from sklearn import metrics
print('Kmeans_ARI: %s' % metrics.adjusted_rand_score(np.array(target), Kmeans_cluster_res))
print('Agg_ARI: %s' % metrics.adjusted_rand_score(np.array(target), Agg_cluster_res))
print('DBSCAN_ARI: %s' % metrics.adjusted_rand_score(np.array(target), DBSCAN_cluster_res))
▶ 轮廓系数(Silhouette Coefficient, SC) ——— 不需要真实的分类标签
from sklearn.metrics import silhouette_score
print("1)使用欧式距离:")
print("Kmeans:",silhouette_score(features, Kmeans_cluster_res, metric='euclidean'))
print("Agglomerative:",silhouette_score(features, Agg_cluster_res, metric='euclidean'))
print("DBSCAN:",silhouette_score(features, DBSCAN_cluster_res, metric='euclidean'))
print("2)使用余弦距离:")
print("Kmeans:",silhouette_score(features, Kmeans_cluster_res, metric='cosine'))
print("Agglomerative:",silhouette_score(features, Agg_cluster_res, metric='cosine'))
print("DBSCAN:",silhouette_score(features, DBSCAN_cluster_res, metric='cosine'))
运行实测
注
- 上面的代码是直接copy就可运行的 !
- 但是效果极差 >_< ! —— 兰德指数均在0.001的量级(这非常小),使用余弦距离的轮廓系数甚至均为负数
- 原因大致在于:参数选用不合适;该文本不适合聚类(毕竟特征词如此松散)
最后,记录一个困扰我近2h的BUG:
word_fd = nltk.FreqDist(w.lower() for w in movie_reviews.words()).most_common(2000)
这句代码的目的选出词频最高的前2000个(词+频度),将这些词作为特征词
但是!
我为了快速看到运行效果,心急地将特征词数从2000降到200
这导致文本的特征过于稀疏,甚至无法完成聚类!(都是一类!)
希望能够帮到你一些 >_<