Polynomial多项式升维和PCA降维
Polynomial多项式升维和PCA降维 --潘登同学的Machine Learning笔记
文章目录
- Polynomial多项式升维和PCA降维 --潘登同学的Machine Learning笔记
-
- (简单回顾)多元线性回归模型
- Polynomial多项式升维
-
- 多项式升维具体操作(以两个变量为例)
- PCA降维
-
- 特征向量中刻画了矩阵的本质
- PCA目标
- PCA的过程
- PCA 总结
- 应用实例PCA:
(简单回顾)多元线性回归模型
-
总目标:预测 -
模型:
y = β 0 + β 1 x 1 + ⋯ + β k x k y = \beta_0 + \beta_1x_1 + \cdots + \beta_kx_k y=β0+β1x1+⋯+βkxk -
优化目标:MSE
L o s s = ∑ n = 1 m e r r o r 2 = ∑ n = 1 m ( y ^ − y ) 2 Loss = \sum_{n=1}^{m} error^{2} = \sum_{n=1}^{m} (\hat{y} - y)^{2} Loss=n=1∑merror2=n=1∑m(y^−y)2 -
优化方法:梯度下降法
θ j t + 1 = θ j t − η ∙ g r a d i e n t j \theta_j^{t+1} = \theta_j^{t} - \eta \bullet gradient_j θjt+1=θjt−η∙gradientj
Polynomial多项式升维
跟我学这个Polynomial怎么读, 破你诺μ;破你诺μ;破你诺μ
如果数据的如下:

那么用多元线性回归 y = β 0 + β 1 x 1 y=\beta_0 + \beta_1x_1 y=β0+β1x1去拟合效果就不尽人意了;
对于上图我们可以将模型修改为:
y = β 0 + β 1 x 1 + β 2 x 1 2 y=\beta_0 + \beta_1x_1 + \beta_2x_1^2 y=β0+β1x1+β2x12
注意:上面仍然是线性回归模型, 线性回归的线性是指 β \beta β线性, 而不是里面的解释变量(自变量)是线性;
当数据呈现一种非线性关系的时候,即 y 不是随着 X 线性变化的时候,我们这时有两种选择,一是选择用非线性的算法(回归树、 神经网络等)去拟合非线性的数据。二是铁了心的用线性算法,但是需要把数据变成线性变化的关系才能更好的让算法发挥功能。其实也不要小看线性算法,毕竟线性的算法运算速度快是一大优势,当我们把数据通过升维变成线性变化关系后,就能让线性模型可以去应对更加广泛的数据集;
多项式升维具体操作(以两个变量为例)
假设数据集有两个维度 X 1 , X 2 X_1, X_2 X1,X2, 采用多元线性回归模型:
y = β 0 + β 1 x 1 + β 2 x 2 y = \beta_0 + \beta_1x_1 + \beta_2x_2 y=β0+β1x1+β2x2
对其进行二阶多项式升维:
y = β 0 + β 1 x 1 + β 2 x 2 + β 3 x 1 2 + β 4 x 2 2 + β 5 x 1 x 2 y = \beta_0 + \beta_1x_1 + \beta_2x_2 + \beta_3x_1^2 + \beta_4x_2^2 + \beta_5x_1x_2 y=β0+β1x1+β2x2+β3x12+β4x22+β5x1x2
话不多说, 上代码!!!
#%%多项式回归升维
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
np.random.seed(42)
m = 100
X = 6*np.random.rand(m, 1) - 3
y = 0.5*X**2 + X + 2 + np.random.randn(m, 1)
plt.plot(X, y, 'b.')
X_train = X[:80]
y_train = y[:80]
X_test = X[80:]
y_test = X[80:]
# 进行多项式升维, 升维为 2, 10
d = {1: 'g-', 2: 'r+', 10: 'y*'}
for i in d:
print('现在维度为:', i)
poly_features = PolynomialFeatures(degree=i, include_bias=True)
X_poly_train = poly_features.fit_transform(X_train)
X_poly_test = poly_features.fit_transform(X_test)
print(X_train[0])
print(X_poly_train[0])
print(X_train.shape)
print(X_poly_train.shape)
#把测试集和训练集扔进去后就会自动在数据的左边拼接上升维后的数据
#注意 多项式回归只是一个预处理工具,不是model
lin_reg = LinearRegression(fit_intercept=False)
lin_reg.fit(X_poly_train, y_train)
print(lin_reg.intercept_, lin_reg.coef_)
# 看看是否随着degree的增加升维,是否过拟合了
y_train_predict = lin_reg.predict(X_poly_train)
y_test_predict = lin_reg.predict(X_poly_test)
plt.plot(X_poly_train[:, 1], y_train_predict, d[i])
print('训练集的MSE')
print(mean_squared_error(y_train, y_train_predict)) #训练集的MSE
print('测试集的MSE')
print(mean_squared_error(y_test, y_test_predict)) #测试集的MSE
plt.show()
观察到升维为10维的模型训练集的MSE要小于2维的模型,表明在训练阶段, 10维模型的拟合效果更好; 但是在10维模型的训练集MSE要大于2维的模型, 表明预测效果略差; 而这就称为过拟合!!! (训练更好, 测试更差)
PCA降维
PCA(Principal components analysis), 也叫主成分分析
在维度灾难、冗余,这些在数据处理中常见的场景,不得不需要我们进一步处理,为了 得到更精简更有价值的信息,我们所用的的各种方法的统称就是降维;
降维有两种方式:
- 特征映射:它的思想即把高维空间的数据映射到低维空间;(如:PCA)
- 特征选择:
- 过滤式(打分机制):过滤,指的是通过某个阈值进行过滤。(依据指标方差、信息增益、互信息)
我们能知道, 方差越大蕴含的信息量越大(从反面想一想, 如果一个回归中的x都相同没啥区别, 那么怎么去拟合不同的y);
信息增益在决策树中详细讲解, 不是本文目标;
互信息是计算语言学模型分析的常用方法,它度量两个对象之间的相互性。详见百度百科;
- 包裹式:每次迭代产生一个特征子集,评分;
- 嵌入式:先通过机器学习模型训练来对每个特征得到一个权值。接下来和过滤式相似, 通过设定某个阈值来筛选特征。区别在于,嵌入式使用机器学习训练;过滤式采用统计特征;(如前面讲过的Lasso和后面要说的决策树模型)
- 过滤式(打分机制):过滤,指的是通过某个阈值进行过滤。(依据指标方差、信息增益、互信息)
特征向量中刻画了矩阵的本质
回想矩阵的本质: 线性方程组的系数矩阵 n × n n\times n n×n(假设n个未知数n条方程)
我们可以那些所谓的带入消元法, 加减消元法解出结果;
而用矩阵的语言来说就是将系数矩阵化为单位阵, 这样左边的未知量就能直接等于右边的系数了(也称为解耦,原本的 x 1 , x 2 x_1,x_2 x1,x2的耦合关系解开, 变成单个变量), 如下:
矩阵方程:
[ 30 15 12 5 ] [ x 1 x 2 ] = [ 675 265 ] {\begin{bmatrix} 30 & 15 \\ 12 & 5 \\ \end{bmatrix}} {\begin{bmatrix} x_1\\ x_2 \\ \end{bmatrix}}= {\begin{bmatrix} 675 \\ 265 \\ \end{bmatrix}} [3012155][x1x2]=[675265]
化为单位阵:
[ 1 0 0 1 ] [ x 1 x 2 ] = [ 20 5 ] {\begin{bmatrix} 1 & 0 \\ 0 & 1 \\ \end{bmatrix}} {\begin{bmatrix} x_1\\ x_2 \\ \end{bmatrix}}= {\begin{bmatrix} 20 \\ 5 \\ \end{bmatrix}} [1001][x1x2]=[205]
这是解存在的例子, 左边理所当然地化为了单位阵; 如果解不存在, 可能左边无论如何都不能化为单位阵;
所以我们有所谓简化行阶梯形;
- 行阶梯型

- 简化行阶梯形

这个简化行阶梯形反映了矩阵方程解的情况, 所以我们能说它刻画了矩阵某一方面的本质;
回到特征向量上:特性向量又是怎么刻画矩阵本质的呢?
我们不站在矩阵的线性方程组的角度了, 我们现在站在几何空间的角度了
而对于矩阵的几何含义,我认为严质彬老师讲得太好了, 耐心学完他, 你也能成为数学博士!
- 举个栗子:
在 R 2 {\Bbb{R}^2} R2的向量空间中, 存在一个向量
x ⃗ = [ 2 2 ] \vec{x}={\begin{bmatrix} 2 \\ 2 \\ \end{bmatrix}} x=[22]
存在一个矩阵A
A = [ 1 − 1 1 1 ] A={\begin{bmatrix} 1 & -1 \\ 1 & 1 \\ \end{bmatrix}} A=[11−11]
将向量左乘矩阵
A x ⃗ = [ 0 4 ] A\vec{x}={\begin{bmatrix} 0 \\ 4 \\ \end{bmatrix}} Ax=[04]
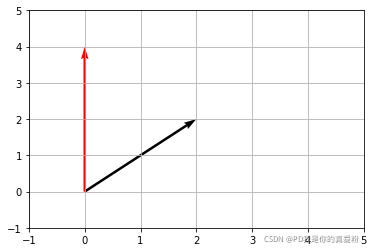
发现其实左乘矩阵的作用就是对向量进行旋转拉伸;
注意:因为我们使用一个2x2的矩阵去乘上一个2x1的向量, 结果向量自然是2x1的;所以还在原平面内; 倘若是用3x2的矩阵去乘上一个2x1的向量, 那结果就是3x1的,就不在这个坐标平面内了;
深刻理解矩阵与标准线性空间线性映射两事物的等同性
(矩阵分析的思想)
给定 A ∈ F m × n \mathbf{A} \in \Bbb{F}^{m\times n} A∈Fm×n, 通过右乘列向量, 可决定线性映射
A : F n → F m x ↦ A x \mathcal{A}:{\Bbb{F}^{n}} \to {\Bbb{F}^{m}} \\ \quad x \mapsto \mathbf{A}x A:Fn→Fmx↦Ax
显然有:
A = [ A ( ϵ 1 ) , A ( ϵ 2 ) , ⋯ , A ( ϵ n ) ] ∈ F m × n \mathbf{A} = [\mathcal{A}(\epsilon_1), \mathcal{A}(\epsilon_2), \cdots, \mathcal{A}(\epsilon_n)] \in \Bbb{F}^{m\times n} A=[A(ϵ1),A(ϵ2),⋯,A(ϵn)]∈Fm×n
记 F n {\Bbb{F}^{n}} Fn的标准基(裂分块)为 [ ϵ 1 , ϵ 2 , ⋯ , ϵ n ] [\epsilon_1, \epsilon_2, \cdots, \epsilon_n] [ϵ1,ϵ2,⋯,ϵn],是单位阵 I n \mathbf{I}_n In
验证: A x = A ( x ) \mathbf{A}x = \mathcal{A}(x) Ax=A(x)
x ∈ F n x \in {\Bbb{F}^{n}} x∈Fn, 将x的坐标形式写出来
x = [ ϵ 1 , ϵ 2 , ⋯ , ϵ n ] x x = [\epsilon_1, \epsilon_2, \cdots, \epsilon_n]x x=[ϵ1,ϵ2,⋯,ϵn]x
这个是标准基, 就是单位阵, 所以坐标跟自己一样, 但是含义不相等
A ( x ) = ( 线 性 性 质 ) A ( ϵ 1 x 1 ) + A ( ϵ 2 x 2 ) + ⋯ + A ( ϵ n x n ) = ( 数 乘 性 质 ) A ( ϵ 1 ) x 1 + A ( ϵ 2 ) x 2 + ⋯ + A ( ϵ n ) x n = [ A ( ϵ 1 ) , A ( ϵ 2 ) , ⋯ , A ( ϵ n ) ] x = A x \begin{aligned} \mathcal{A}(x) & \stackrel{(线性性质)}= \mathcal{A}(\epsilon_1 x_1) + \mathcal{A}(\epsilon_2 x_2)+ \cdots + \mathcal{A}(\epsilon_n x_n)\\ & \stackrel{(数乘性质)}= \mathcal{A}(\epsilon_1)x_1 + \mathcal{A}(\epsilon_2)x_2+ \cdots + \mathcal{A}(\epsilon_n)x_n \\ & = [\mathcal{A}(\epsilon_1), \mathcal{A}(\epsilon_2), \cdots, \mathcal{A}(\epsilon_n)]x \\ & = Ax \end{aligned} A(x)=(线性性质)A(ϵ1x1)+A(ϵ2x2)+⋯+A(ϵnxn)=(数乘性质)A(ϵ1)x1+A(ϵ2)x2+⋯+A(ϵn)xn=[A(ϵ1),A(ϵ2),⋯,A(ϵn)]x=Ax
所以矩阵的乘法与线性映射就有等同性了;
而我们常说矩阵是线性变换, 线性变换是线性映射的一个特例, 线性变换是将一个空间的向量映射到原空间; 是一种特殊的线性映射;
观察下面一个例子:

空间中存在一个向量 x ⃗ = ( 1 , 1 , 1 ) \vec{x} = (1,1,1) x=(1,1,1), 对其左乘一个矩阵A:
A = [ 2 0 0 0 2 0 0 0 3 ] A= \begin{bmatrix} 2 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 3 \\ \end{bmatrix} A=⎣⎡200020003⎦⎤
A x ⃗ = [ 2 0 0 0 2 0 0 0 3 ] [ 1 1 1 ] = [ 2 2 3 ] A\vec{x} = {\begin{bmatrix} 2 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 3 \\ \end{bmatrix}} {\begin{bmatrix} 1 \\ 1 \\ 1 \\ \end{bmatrix}}= \begin{bmatrix} 2 \\ 2 \\ 3 \\ \end{bmatrix} Ax=⎣⎡200020003⎦⎤⎣⎡111⎦⎤=⎣⎡223⎦⎤
对原向量来说, 这个矩阵A作用后的向量相当于在x轴上使原向量伸长至两倍, 在y轴上伸长至两倍, 在z轴上伸长至3倍;
特征向量描绘了矩阵做线性变换的方向
我们一直在说矩阵是线性变换, 但是这个线性变换到低是怎么做的呢, 到低将原向量怎么旋转怎么拉伸?
线性变换的方向就是特征向量的方向
看前面的例子, 很容易的知道特征向量是
( 1 0 0 ) ; ( 0 1 0 ) ; ( 0 0 1 ) {\begin{pmatrix} 1 \\ 0 \\ 0 \\ \end{pmatrix}}; {\begin{pmatrix} 0 \\ 1 \\ 0 \\ \end{pmatrix}}; {\begin{pmatrix} 0 \\ 0 \\ 1 \\ \end{pmatrix}} ⎝⎛100⎠⎞;⎝⎛010⎠⎞;⎝⎛001⎠⎞
那拉伸的方向就是x轴,y轴,z轴; 如果矩阵A作用在一个
( 1 0 0 ) \begin{pmatrix} 1 \\ 0 \\ 0 \\ \end{pmatrix} ⎝⎛100⎠⎞
上, 那只会将它扩大2倍, 因为他在y轴, z轴上没有分量,不能被拉伸;
线性变换的程度就是特征值
根据前面的铺垫, 拉伸两倍, 拉伸3倍, 这些倍数都由特征值来确定;
- 来个例子:
对实矩阵A计算特征值与特征向量:
A = ( 3 2 4 2 0 2 4 2 3 ) A={\begin{pmatrix} 3 & 2 & 4 \\ 2 & 0 & 2 \\ 4 & 2 & 3 \\ \end{pmatrix}} A=⎝⎛324202423⎠⎞
import numpy as np
A = np.array([[3,2,4],[2,0,2],[4,2,3]])
lamdba, alpha = np.linalg.eig(A)
for i in range(len(lamdba)):
print('特征值为:', lamdba[i])
print('特征向量为:', alpha[:, i])
结果如下:

我们这样解释: 矩阵A做线性变换的时候, 对 α 1 \alpha_1 α1方向进行了-1倍的拉伸(因为特征向量的那个数字太长了, 简记为 α \alpha α);对 α 2 \alpha_2 α2方向进行了8倍的拉伸;对 α 3 \alpha_3 α3方向进行了-1倍的拉伸;
我们已经对特征值和特征向量有了深刻的理解: 特征向量不是凭空找来的, 而是用于刻画矩阵作为线性变换时的方向, 而特征值则是刻画线性变换的程度的;
PCA目标
- 最小投影距离;
- 最大投影方差;
- 降维后不同维度的相关性为0;

单从数据角度看, 数据的离散程度越大, 代表数据在所投影的维度有越高的区分度,这个区分度就是信息量
将坐标轴进行旋转就能正确降维了。而这个旋转的操作其实就是矩阵变换
X是原数据, V是降维后的数据
X = ( x 1 x 2 ) ⟶ 线 性 变 换 ( v 1 v 2 ) = V X = {\begin{pmatrix} x_1 \\ x_2 \\ \end{pmatrix}} \stackrel{线性变换}\longrightarrow {\begin{pmatrix} v_1 \\ v_2 \\ \end{pmatrix}} = V X=(x1x2)⟶线性变换(v1v2)=V
A X = ( a 11 a 12 a 21 a 22 ) ( x 1 x 2 ) = ( v 1 v 2 ) AX={\begin{pmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \\ \end{pmatrix}}{\begin{pmatrix} x_1 \\ x_2 \\ \end{pmatrix}}={\begin{pmatrix} v_1 \\ v_2 \\ \end{pmatrix}} AX=(a11a21a12a22)(x1x2)=(v1v2)
根据我们上面的观点, 可以描绘这个过程
通过矩阵 A 对坐标系 X 进行线性变换。其实就可以得知,特征值对应的特征向量就是理想中想取得的正确坐标轴,而特征值就等于数据在旋转后的坐标上对应维度的方差(沿对应的特征向量的数据的方差)。而 A 其实即为我们想求得的那个降维特征空间, V 则是我们想要的降维后的数据
PCA的过程
-
标准化
- 将均值化为0, 若未中心化,可能第一主成分的方向有误;
- 除以标准差, 消除量纲的影响
-
计算协方差矩阵
c o v ( X , Y ) = ∑ i = 1 m ( X i − X ˉ ) ( Y i − Y ˉ ) m − 1 cov(X,Y) = \frac{\sum_{i=1}^{m}(X_i-\bar{X})(Y_i-\bar{Y})}{m-1} cov(X,Y)=m−1∑i=1m(Xi−Xˉ)(Yi−Yˉ)
因为前面已经标准化了, 所以协方差矩阵可以用 E = ( X X T ) E=(XX^{T}) E=(XXT)或者 1 m X X T \frac{1}{m}XX^{T} m1XXT来表示;
为什么要计算协方差矩阵:
回想目标:在降维后的每一维度上,方差最大。而方差最大,则容易想到的就是协方差矩阵,去标准化后,协方差矩阵的对角线上的值正好就是各个数据维度的方差。原始数据的协方差矩阵 X n × n X_{n\times n} Xn×n对角线,对应的就是原始数据的方差;降维后的数据的协方差矩阵 X n ′ × n ′ ′ X'_{n'\times n'} Xn′×n′′,对应的就是降维后的数据的方差。
-
目标:迹最大
我们的目的,是使方差最大,这就又想到了另一个概念:迹,因为迹不就是对角线上所有元素之和吗,而协方差矩阵的迹,不就是方差之和吗。这样我们构建损失函数,不就是 a r g m a x t r ( X ′ ) argmaxtr(X') argmaxtr(X′) !!!
设新的坐标系 W n ′ × n ′ W_{n'\times n'} Wn′×n′: { w 1 , w 2 , ⋯ , w n } \{{w_1, w_2, \cdots, w_n\}} {w1,w2,⋯,wn}
显然w为标准正交基(目标中, 要求各个维度间线性无关)
∣ ∣ w ∣ ∣ 2 = 1 , w i T w j = 0 ||w||_2=1, w_i^Tw_j = 0 ∣∣w∣∣2=1,wiTwj=0
则原数据在新的坐标系下的投影为 Z = W T X Z=W^TX Z=WTX, 其中 Z = { z 1 , z 2 , ⋯ , z n ′ } Z=\{z_1, z_2, \cdots, z_{n'}\} Z={z1,z2,⋯,zn′}
注意:X的本质不是向量, 而是向量在标准基下的坐标!!! X的向量形式应该写为 I X \mathbf{I}X IX, 即用标准基底与X相乘, 所以这里的 Z = W T X Z=W^TX Z=WTX, 只不过是在另一组基下的向量而已;
向量 X i X_i Xi 在ω上的投影坐标可以表示为:
( X i , ω ) = X i T ω (X_i, \omega) = X_i^T \omega (Xi,ω)=XiTω
易知中心化后, 投影均值为0
1 m ∑ i = 1 m X i T ω = 0 \frac{1}{m}\sum_{i=1}^{m}X_i^T\omega = 0 m1i=1∑mXiTω=0
投影之后的方差可以表示为:
D ( x ) = 1 n ∑ i = 1 n ( X i T ω ) 2 = 1 n ∑ i = 1 n ( X i T ω ) T ( X i T ω ) = 1 n ∑ i = 1 n ω T X i X i T ω = ω T ( 1 n ∑ i = 1 n X i X i T ) ω = ( 1 n ∑ i = 1 n X i X i T ) = 1 n X X T \begin{aligned} D(x) & = \frac{1}{n}\sum_{i=1}^{n}(X_i^T\omega)^2 \\ & = \frac{1}{n}\sum_{i=1}^{n}(X_i^T\omega)^T(X_i^T\omega) \\ & = \frac{1}{n}\sum_{i=1}^{n}\omega^T X_i X_i^T \omega \\ & = \omega^T(\frac{1}{n}\sum_{i=1}^{n} X_i X_i^T) \omega \\ & = (\frac{1}{n}\sum_{i=1}^{n} X_i X_i^T) \\ & = \frac{1}{n} X X^T \\ \end{aligned} D(x)=n1i=1∑n(XiTω)2=n1i=1∑n(XiTω)T(XiTω)=n1i=1∑nωTXiXiTω=ωT(n1i=1∑nXiXiT)ω=(n1i=1∑nXiXiT)=n1XXT
就是样本的协方差矩阵, 所以将问题转化为
{ max { ω T Σ ω } s . t . ω T ω = 1 \begin{cases} \max \{\omega^T \Sigma \omega\} \\ s.t. \quad \omega^T \omega = 1 \\ \end{cases} {max{ωTΣω}s.t.ωTω=1
其中 Σ \Sigma Σ表示协方差矩阵;
- 拉格朗日乘子法求解上式
J ( ω ) = ω T Σ ω + λ ( ω T ω − 1 ) J(\omega) = \omega^T \Sigma \omega + \lambda(\omega^T \omega - 1) J(ω)=ωTΣω+λ(ωTω−1)
对 ω \omega ω求导, 令他为0:
Σ ω = − λ ω \Sigma \omega = - \lambda \omega Σω=−λω
带回D(X):
D ( X ) = ω T Σ ω = − λ ω T ω = − λ D(X) = \omega^T \Sigma \omega = - \lambda \omega^T \omega = - \lambda D(X)=ωTΣω=−λωTω=−λ
λ \lambda λ是由特征值构成的对角阵,且特征值在对角线上,其余位置为 0。很显然,W为标准正交基,我们假如把特征值以及对应的 W 的那一列拿出来和相乘,不就是一个求特征值和特征向量的过程嘛。而 W 的维度为 n’ x n’,显然我们就是求前 n’个最大的特征值以及对应的特征向量(同时也可以设定一个阈值,当前 n’个特征向量达到总和的多少占比时,一 般是 85%,就提取,这样可能在尽可能减少信息量损失的情况下更多地降低维度)。这 n’ 个特征向量组成的矩阵 W 即为我们需要的矩阵。通过将原始数据矩阵与该矩阵进行矩阵乘法,便可以将 n 维的数据降到 n’维。也就是说,一条 n 维的数据{1xn},假设选了前 n’ 个 特征向量,通过乘以特征矩阵{nxn’},就变成了 n’ 维的数据{1xn’},我们就达到了降维的目的。
捋一遍思路
目标: 最大投影方差 ⇔ \Leftrightarrow ⇔ 协方差矩阵的迹最大 ⟺ ( 矩 阵 的 迹 不 变 ) \stackrel{(矩阵的迹不变)}\Longleftrightarrow ⟺(矩阵的迹不变) 特征值最大(特征值所在的对角阵也是由协方差矩阵来的)
那么特征值最大的特征向量就是第一主成分,接着是第二主成分 ⋯ \cdots ⋯
PCA 总结
PCA 的主要优点有:
- 仅通过方差衡量信息量,不受数据集以外因素影响。
- 各主成分之间正交,消除可能出现的低秩、或者原始数据成分间相关的可能。
- 计算方法简单,易于实现。
主要缺点:
- 降维后各个特征维度的含义具有一定的模糊性,数据的可解释性没有原始样本的特征强。(可解释性变弱)
- 方差小的非主成分可能含有对样本差异的重要信息(可能丢失强力特征),因降维丢弃后可能对后续处理有影响
应用实例PCA:
数据集是机器学习经典数据集, 后面还会经常用到;
目标: 将4维数据降维成两维, 并在平面上显示
import matplotlib.pyplot as plt
import sklearn.decomposition as dp
from sklearn.datasets.base import load_iris
x,y=load_iris(return_X_y=True) #加载数据,x表示数据集中的属性数据,y表示数据标签
pca=dp.PCA(n_components=2) #加载pca算法,设置降维后主成分数目为2
reduced_x=pca.fit_transform(x) #对原始数据进行降维,保存在reduced_x中
red_x,red_y=[],[]
blue_x,blue_y=[],[]
green_x,green_y=[],[]
for i in range(len(reduced_x)): #按鸢尾花的类别将降维后的数据点保存在不同的表表中
if y[i]==0:
red_x.append(reduced_x[i][0])
red_y.append(reduced_x[i][1])
elif y[i]==1:
blue_x.append(reduced_x[i][0])
blue_y.append(reduced_x[i][1])
else:
green_x.append(reduced_x[i][0])
green_y.append(reduced_x[i][1])
plt.scatter(red_x,red_y,c='r',marker='x')
plt.scatter(blue_x,blue_y,c='b',marker='D')
plt.scatter(green_x,green_y,c='g',marker='.')
plt.show()
最终效果如下:

Polynomial多项式升维和PCA降维就是这样了, 继续下一章吧pd的Machine Learning