【八】头歌平台实验-知识图谱1
主要讲解知识图谱。
第1关:什么是知识图谱
1、下面有关知识图谱的描述中,最准确的是?(D)
A、知识图谱是描述知识之间的关系的一种图结构。
B、知识图谱中的关系的类型只有有限的几种。
C、知识图谱起源于NASA的一项科研计划。
D、知识图谱描述的是一个包含关系和实体的巨大的网络。
2、以下哪个不是知识图谱的应用领域?(B)
A、搜索引擎
B、计算机视觉
C、人机交互
D、智能问答
3、知识图谱作为一个完整的概念,第一次被提出是什么时候?(A)
A、2012年
B、2013年
C、2014年
D、2015年
4、知识图谱可以用哪一种数据结构来描述?(B)
A、二叉树
B、图
C、字典
D、B树
5、知识图谱主要由哪两个部分组成?(A)
A、实体和关系
B、实体和对象
C、类和对象
D、类和实体
相关知识:
1、知识图谱起源
知识图谱这个概念第一次被提出发生在2012年,当时,谷歌为了让搜索引擎给出的结果更加准确,提出了知识图谱(Knowledge Graph)的概念。但是实际上2006年出现的语义网(Semantic Network)的含义类似于知识图谱。
近年来,随着机器学习和深度学习的高速发展,知识图谱技术也迎来了一个快速发展的时期。
2、什么是知识图谱
知识图谱,指的是描述实体之间关系的一个超大型的网络。比如下面是一个知识图谱的例子:

上面的图片中,矩形框中的物体就是实体,它指的是现实世界中存在的事物,即肉眼或者通过技术手段可以被观测到的东西;连线表示的是关系,指的是实体之间的关系,因为任何实体之间都有可能存在关系,所以看起来像一个网络。比如上面的地球和月球的关系是:月球是地球的卫星,好奇号和玉兔号的关系是两者都是地外天体探测器。好奇号和火星的关系是好奇号的目的地是火星,地球和火星的关系是同为八大行星,月球和玉兔号的关系是月球是玉兔号的目的地。
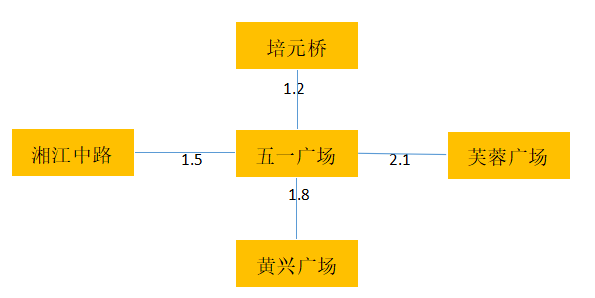
从上面可以看出,知识图谱可以概括为描述多种关系的图,图是一种数据结构,它由节点和连接节点的边组成,节点在这里即表示实体,而边则表示关系。稍微有所不同的是,数据结构中的节点和边都是单一类型的,比如表示城市地铁网格的图如下所示,其中的节点只能是地铁站的名字,而边只能是地铁站之间的距离:
但是知识图谱不同,知识图谱中的节点表示实体,可以有非常多的类型,比如人物、地址、公司名、行星名等等,而关系的种类也是无穷无尽的,比如人和人之间可以是同学、同事、亲人,人和地址之间可以是住址、目的地等。我们细化一下上面的第一幅图如下:
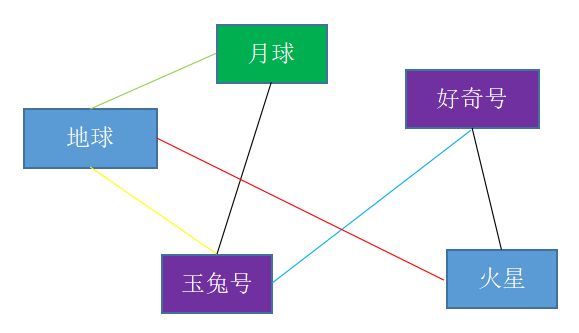
实体中,地球和火星都是太阳系的行星,用深蓝色标出;好奇号和玉兔号都是探测器,用紫色标出,月球是卫星,用深绿色标出。
关系中,玉兔号和月球,好奇号和火星都是目的地关系,用黑色标出;地球和火星是同为行星的关系;好奇号和玉兔号是同为探测器的关系;月球是地球的卫星。
简而言之,知识图谱是描述万事万物的各种类型的关系的一个巨大的网络,
第2关:知识图谱的价值
1、以下关于知识图谱的价值的描述中,错误的是?(C)
A、知识图谱的价值体现在多个方面。
B、知识图谱的价值之一是其具有强大的推理能力。
C、图像处理比知识图谱更接近人类的思维方式。
D、知识图谱可以帮助搜索引擎改进搜索结果。
2、在人工智能的各个分支领域中,最接近人类的思维方式的是?(B)
A、机器学习
B、知识图谱
C、自然语言处理
D、图像处理
3、知识图谱在推荐系统中的一种典型的应用是?(D)
A、智能问答
B、个性化推荐
C、模式识别
D、用户画像
4、下列哪个是知识图谱在搜索引擎中的典型应用?(D)
A、搜索“出国留学“时,给出一大推出国留学有关的网站。
B、搜索”长沙臭豆腐“时,第一条是“长沙臭豆腐”的百度百科。
C、搜索“长沙天气”时,第一条是中国天气网的长沙天气预报页面的链接。
D、搜索五一广场在哪个城市时,第一条直接给出结果:长沙市。
5、知识图谱的推理能力如何应用在金融风控上?(A)
A、通过推理过滤掉一些风险:借款人在其它银行是否有借贷、借款人是否曾经有过逾期行为、借款人是否有稳定的收入等等。
B、通过大数据分析构建借款人的画像。
C、通过人脸识别判断借款人是否是本人。
D、通过验证码判断借款人是否是机器人伪装的。
相关知识:
1、智能音箱
要想了解知识图谱的价值,我们先从不那么抽象的智能音箱说起。 相信大部分人都购买过或者接触过智能音箱产品,不论是小度、小爱、siri还是各种奇奇怪怪的智能音箱产品,其核心技术中都包含了知识图谱。举个简单的例子:当你告诉智能音箱播放音乐时,它会在自己存储的知识图谱中搜索音乐和播放这两个关键词,当它发现音乐是实体而播放是一种关系时,便会顺着播放找到关系的另外一端播放器,从而播放音乐(当然实际上比这个复杂的多,这里简化为了方便理解)。
知识图谱的价值,大部分情况下指的就是它的应用价值。即知识图谱帮助各种产品实现了什么样的具体的功能。下面给出一些例子。
2、知识图谱的价值
- 强大的推理能力
知识图谱最大的价值是其具有强大的推理能力。在人工智能的各个领域比如图像处理、声音处理、自然语言处理中,知识图谱是最接近人类的思维方式的,除了知识图谱,其它的领域都是通过大量的数据找出统一的规律,而知识图谱能够通过推理的方式处理问题。
知识图谱的推理能力可以用在金融风控上,比如银行借贷给个人,可以通过推理过滤掉一些风险:借款人在其它银行是否有借贷、借款人是否曾经有过逾期行为、借款人是否有稳定的收入等等。
- 推荐系统
知识图谱还经常被用于推荐系统中,比如在视频网站中,知识图谱通过分析用户经常看的视频的标签、视频的传作者、视频中的演员等分析出用户的爱好。用户画像也是知识图谱在推荐系统中的一种典型的应用。
- 搜索引擎
知识图谱可以帮助改进搜索引擎,在面对用户输入的有确定答案的问题时,知识图谱辅助的搜索引擎可以直接给出答案:先使用分析用户的输入,然后在存储的知识图谱中搜索答案。
这样用户就不需要逐个翻找网页搜索答案了。
第3关:知识图谱的架构
1、以下关于知识图谱的架构的描述中,错误的是?(B)
A、知识图谱的架构主要由数据来源、数据抽取、数据存储、逻辑推理以及上层应用组成。
B、知识图谱的数据来源不包括传统的数据库。
C、知识图谱中最难的部分是逻辑推理。
D、知识图谱不需要通过上层的应用来实现产品化。
2、知识图谱的数据抽取(知识抽取)阶段不包括哪一项?(D)
A、实体识别
B、关系抽取
C、指代消解
D、逻辑推理
3、知识图谱的数据来源,不包括哪一项?(C)
A、网络爬虫爬取的数据。
B、购物网站的用户数据。
C、机器学习获得的模型
D、电商网站的商品数据。
4、在“小明和同事李华都住在湘江时代小区”这一描述中,哪一个词汇表示的是知识图谱中的关系?(B)
A、小明
B、同事
C、湘江时代
D、小区
5、下列哪一个存储模型不适合用来存储知识图谱?(D)
A、RDF
B、图数据库
C、Neo4j
D、二叉树
相关知识:
1、知识图谱的架构
知识图谱的架构如下所示:
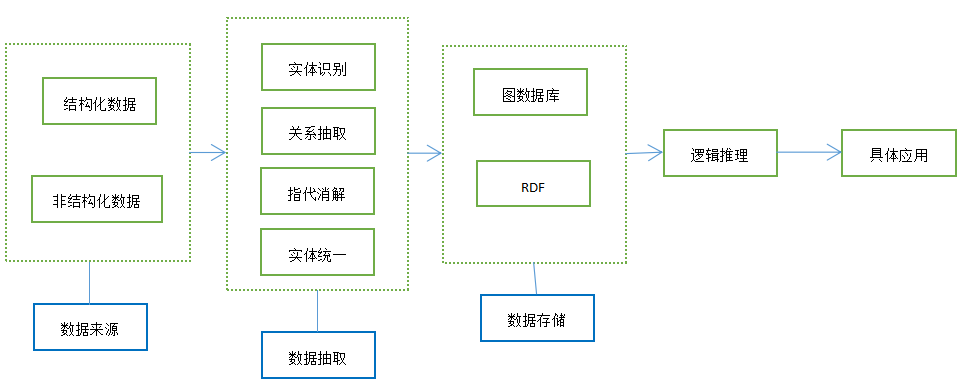
知识图谱总体上由数据来源、数据抽取、数据存储、逻辑推理以及上层应用组成。下面将分别介绍这几个部分。
2、数据来源
首先需要考虑的是,知识图谱中的“知识”从哪里来。
知识分为结构化的知识和非结构化的知识,我们据此划分来源。结构化的知识指的是知识的组织方式相同,比如传统关系型数据库中的数据。这类知识的来源通常是网站或者平台在用户长期的使用下积累的数据,比如购物网站的商品数据。
非结构化的知识通常的来源是爬取的网页数据,因为数据来自不同的网站,其组织结构自然是不同的。
在获取到数据之后,接下来要考虑的是如何从数据中抽取出我们需要的知识。
3、数据抽取
对于结构化的数据,从中提取知识通常比较简单,我们只需要使用一些基本的处理方式就可以获取到知识。比如对于购物网站中的商品数据,我们要获得“销量最好的5G手机”这种知识,使用sql语句或者java、python对数据库中的数据做一些处理即可。
对于非结构化的数据,从中获取知识通常需要经历如下几个步骤:
-
实体识别:从非结构化的数据中识别出哪些是实体是第一步,比如对于从网页上爬取的数据“湘江流经湖南省省会长沙”,需要从中识别出实体“湘江”、“湖南省”、“长沙”。
-
关系抽取:关系抽取是非结构数据处理的第二步,关系是连接实体的桥梁,比如对于上面的例子,我们需要识别出关系“流经”、“省会”,并判断出“湘江”和“长沙”的关系是“湘江流经长沙”,“湖南”和“长沙”的关系是“湖南省的省会是长沙”。
-
指代消解:指代消解,指的是将数据中的代词替换为对应的实体,比如对于“岳麓山坐落于长沙市,它位于湘江的西侧”,我们需要将其中的“它”替换为“岳麓山”。如果不进行指代消解,第二句话获得的知识将无法使用,因为使用的时候,不知道”它“具体值的是什么。
-
实体统一:有些实体有很多的名字,比如”土豆“和”马铃薯“是同一个东西,如果待处理的数据中既有土豆又有马铃薯,这个时候统一为”土豆“或者”马铃薯“,能够将低知识网络的复杂程度。
4、数据存储
知识图谱可以使用两种结构进行存储:RDF和图数据库。
RDF全称是Resource Description Framework,即资源描述框架,由主语、宾语和谓词组成,谓词可以简单理解为关系。RDF结构比较简单,是一种三元组。
图数据库中的实体和关系可以包含属性,比如前面例子中的”湖南“和”长沙“是省和省会的关系,湖南作为一个实体,可以有一些属性,比如面积、人口等。常见的图数据库有Neo4j等。
5、逻辑推理和具体的使用
数据存储完成后,我们就构建了自己的知识图谱,一般来说,大型的知识图谱可以包含几百G甚至T级别的数据。
在具体使用知识图谱的时候,首先要构建一个上层的应用,可以是网站、机器人、APP、智能硬件等,通过接口或者服务的方式使用知识图谱提供的逻辑推理能力。
逻辑推理是知识图谱中最难的部分,它需要分析上层应用的需求,并从已有的知识图谱中找出答案。
第4关:知识图谱的表示与建模
省会
南昌市
560万
7400平方公里
相关知识:
1、RDF表示法
在上一关中,我们说过知识图谱可以使用RDF或者图数据库来表示。
RDF可以使用xml来实现,即知识图谱可以使用xml定义的格式来表示,具体的xml格式并没有规定,只需要符合xml的规范,而且后续的推理环节中能够解析这些xml即可。如下是我们设计的一种xml格式:
湖南省 6900万 22万平方公里省会 长沙市 839万 1.2万平方公里
上面的程序中:
knowledge-graph标签表示一个知识图谱;
knowledge标签表示一个知识;
object标签表示实体中的主格;
predicate标签表示关系谓词;
subject标签实体中的宾格;
name标签表示实体的名字;
attribute标签表示实体的属性列表;
population标签表示地理类实体中的人口属性;
area标签表示地理类实体中的面积属性。
除了这种方式外,RDF还可以由其它几种实现的方式:N-Triples,Turtle,RDFa,JSON-LD等。
-END-![]()