【层级多标签文本分类】HFT-CNN: Learning Hierarchical Category Structure for Multi-label Short Text Categorizati
HFT-CNN: Learning Hierarchical Category Structure for Multi-label Short Text Categorization
1、背景
1、作者(第一作者和通讯作者)
Kazuya Shimura
2、单位
University of Yamanashi
3、年份
2018
4、来源
计算语言学协会
2、四个问题
1、要解决什么问题?
类别层次结构(HS),该方法利用类别之间的层次关系来解决数据稀疏问题。HS层次越低,分类性能越差。因为较低的类别是细粒度的,每个类别的训练数据量比较高级别的要小得多。解决HS低层次的分类问题。
2、用了什么方法解决?
通过应用卷积神经网络(CNN)和微调技术
3、效果如何?
在两个基准数据集上的实验结果表明,本文提出的方法与CNN方法相比具有较强的竞争力。
4、还存在什么问题?
论文笔记
1、INTRODUCTION
长文本由于自身的特点和信息量,一段文本会描述一个特定的主题。短文本由于其自身长度的原因是缺少这种特征的。一般对于短文本的处理会借鉴上下文的语料或者同义词来扩充短文本的含义。但是由于文本的领域相关性,上下文的语料和同义词的分布未必和原始语料一致。由于以上原因短文本分类一直受到人们的关注。
在深度学习领域,对于短文本分类CNN是一种常见的方法,但是这种方法通常需要大规模的语料。文中认为短文本的多标签分类任务所面临的的问题主要是由多标签带来的数据稀疏的问题。在多标签分类中,我们会遇到标签是平行和具有层级结构的情况,例如我们看新闻的时候有生活类,科技类,娱乐类,而娱乐类又会分为电影频道,电视剧频道等等。对于标签有层级关系的问题,文中提出了Hierarchical CNN结构。
2 Hierarchical Fine-Tuning based CNN
2.1 CNN architecture
文中文本分类的CNN模型类似于Text-CNN,输入是短文本sentence,sentence由词向量拼接而成,文中使用的是fasttext,接着使用卷积核为w的卷积层提取sentence的特征,然后添加max-pooling层,将这些池化层的的结果拼接然后经过全连接层和dropout得到上层标签[A,B,…]的概率,loss采用交叉熵。这是一个非常经典的CNN结构。

参考模型中标签的结构,来说下其样本训练学习的思路: 1)输入的是样本一段短文本sentence,将sentence转换成词embedding,文中利用的fastText; 2)接着先训练样本的顶层label(A,B),具体是在embedding层后加一个卷积层(convoluational layer),最大池化层(maxpooling layer),全连接层+dropout,最后加个sigmoid层,用的二元交叉熵(binary cross-entorpy loss)进行A,B标签预测,这一个CNN分类框架; 3)在预测下一层标签时(A1,A2,B1,B2),采用的仍是CNN结构,只是在embedding layer和convoluational layer不重新生成,而是继承上一层学习的结果,然后在这个基础上进行微调学习; 4)按照2,3步骤,遍历整个层级标签;
2.2 Hierarchical structure learning
对于下层标签的预测文中的思路是在上层标签的预测中模型已经学到了通用的特征,但是深层layer应该去学习原始数据集中比较详细的信息。因此文中对embedding和卷积层参数保持不变,在这个基础上进行微调学习,这一步标签也由[A,B]变为[A1,A2,B1,B2]。
2.3 Multi-label categorization
对于最终文本分类的结果判断文章采用了两种得分方式:
BSF(Boolean Scoring Function)
MSF(Multiplicative Scoring Function)
两种方法都是设置一个阈值,文本在某个分类的得分超过阈值则认为是该分类的。区别是BSF只有在文本被分到一级分类的情况下才会认为分类的二级分类是正确的,MSF没有这项限制。
3 Experiments
3.1 Data and HFT-CNN model setting
文中数据集采用RCV1和Amazon 670K,相关链接可以见相关资料部分。数据集的基本情况如下,L表示数据集标签的层级深度,TrTe表示训练数据和测试数据,C表示标签整体的量。分类的效果采用F1值进行衡量,此外还采用了P@k和NDCG@k标准。

3.3 Basic results
文中将HFT-CNN和没有经过微调的CNN模型(WoFT-CNN)和没有经过层级结构标签处理的模型(Flat Model)进行对比,实验效果如下,其中B表示BSF,M表示MSF。
可以看出在效果上RCV1和Amazon 670K,HFT-CNN的效果都是优于其他模型的,但是在使用MSF得分和Micro F1值时WoFT的效果和HFT相同,但是在Macro F1的得分缺逊于HFT-CNN。这个我们猜测是因为WoFT整体效果比较好,但是在某一类上的分类效果差于HFT-CNN所以导致Macro F1值比较低,这也证明了HFT-CNN的初衷:对标签分类,模型先学习比较通用的知识,然后进行细分。
3.4 Comparison with state-of-the-art method
STOA效果文中主要对比了XML-CNN,实验效果如下,可以看到在两个数据集上,HFT-CNN的效果超越了目前的STOA的效果。

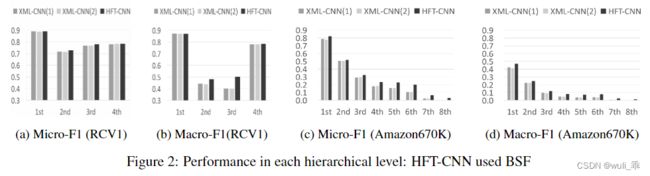
层级分类效果
文中统计了多个层级的文本分类效果,可以看出标签层级越深,分类效果越差,但是HFT-CNN的效果依然优于XML。
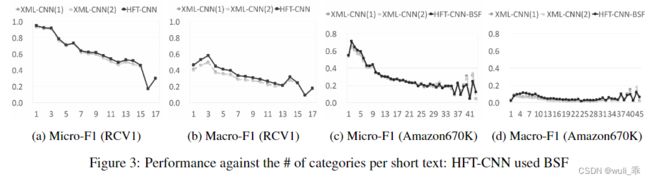
多标签数量
文中对于每个短文本的有多个分类的情况下对分类的数量的准确率进行了统计,可以看到分类越多识别的准确率越低。
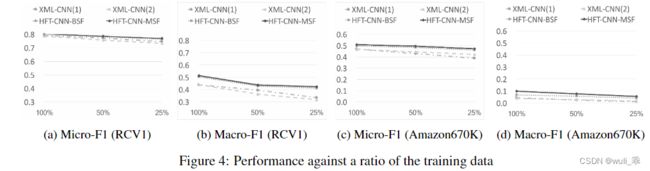
训练数据规模
文中也讨论了训练数据的规模对实验结果的影响,可以看到训练数据越多实验效果越好。但是需要注意的是随着训练数据规模的降低,HFT-CNN的效果下降的较XML比较平缓。这表示经过多轮学习,HFT-CNN学到的语料内容更多一点。
本文参考:https://blog.csdn.net/lion19930924/article/details/105623783?spm=1001.2014.3001.5502
https://comdy.blog.csdn.net/article/details/122855614?spm=1001.2014.3001.5502