Python OpenCv 车牌检测识别(边缘检测、HSV色彩空间判断)
Python OpenCv 车牌检测识别
背景
车牌识别在交通、停车等方面有着广泛应用,在网上也有很多种基于OpenCV方案进行识别,本文是综合了两种比较流行的方案,首先是提取出疑似车牌区域的轮廓,然后再基于色彩空间进行二次判断,比之前的方案有精度更高,泛化能力更强。
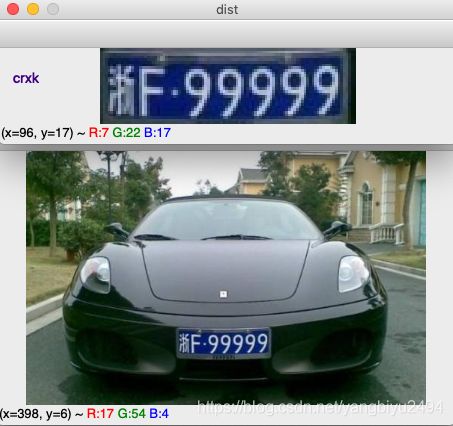
最终效果

详细过程
- 将正常图像等比例压缩并且转化为灰度图像,便于处理以后处理
img = cv2.imread('car2.jpeg')
initial_car = cv2.resize(img, (400, int(400 * img.shape[0] / img.shape[1])))
gray_car = cv2.cvtColor(initial_car, cv2.COLOR_BGR2GRAY)
- 高斯模糊,消除噪点,便于边缘提取。卷积核所选取的越大,模糊效果越明显,但是也有可能造成重要边缘信息的丢失,应该根据实际情况去调整。
blur_car = cv2.GaussianBlur(gray_car, (7, 7), 0)
- 使用cv2.Canny() 进行边缘检测 此效果强于OpenCV中的Sobel边缘检测。cv2.Canny()返回的一幅二值化的图像,可以直接用cv2.findContours()进行轮廓提取。
canny_car = cv2.Canny(blur_car, 70, 120)

4. 各种形态学操作,主要是让车牌的轮廓更加明显,消除无用的噪点。此处卷积核的选择使用横向卷积核(3,13)3行13列。因为车牌也是一个横向的长方形,这样效果更好。可根据具体情况适当增加开 闭操作的次数。
def morphological_operation(img):
kernel = np.ones((3, 13), np.uint8)
closing_img = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)
opening_img = cv2.morphologyEx(closing_img, cv2.MORPH_OPEN, kernel)
kernel_2 = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
dilated_car = cv2.dilate(opening_img, kernel_2)
return dilated_car
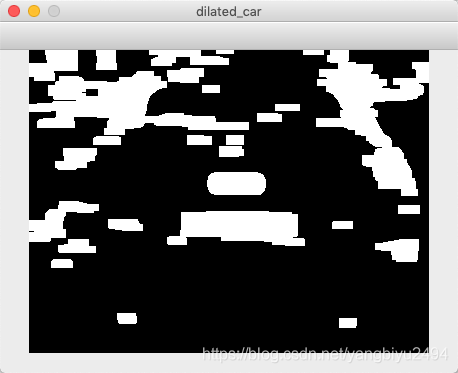
5. 提取轮廓,并且cv2.minAreaRect() 获得包裹轮廓的最小矩形,对这个矩形的长宽比进行判断,看其是否符合车牌特征。
# 对minAreaRect获得的最小外接矩形,用长宽比进行判断
def verify_sizes(rect):
error = 0.3
aspect = 3.143 # 定义的车牌长宽比 数据来源百度百科==>车牌
rmin = aspect - aspect * error
rmax = aspect + aspect * error
height, width = rect[1]
if height == 0 or width == 0:
return False
r = width/height
if r < 1:
r = height/width
if r < rmin or r > rmax:
return False
else:
return True
- 根据色彩空间进行第二次判断,识别提高精度。
# 根据色彩空间进行二次筛选,图像均值最大的为结果
def verify_color(all_contour):
dist_mean = 0
t = 0
for contour in all_contour:
t=t+1
x,y,w,h = cv2.boundingRect(contour)
# 获取矩形框里面的像素
res = initial_car[y:y+h,x:x+w,:]
hsv = cv2.cvtColor(res, cv2.COLOR_BGR2HSV)
# 蓝色车牌范围
lower = np.array([100, 43, 46])
upper = np.array([124, 255, 255])
# 色彩空间提取,在蓝色范围内为255,不在为0.
dist = cv2.inRange(hsv, lower, upper)
# 计算均值,输出最大值
mean = cv2.mean(dist)
if mean[0]>dist_mean:
dist_mean = mean[0]
dist_img = res
return dist_img
- 效果展示