BERT and beyond
BERT
背景前言
注意力机制-transformer
https://mp.weixin.qq.com/s?__biz=MzIwMTc4ODE0Mw==&mid=2247486960&idx=1&sn=1b4b9d7ec7a9f40fa8a9df6b6f53bbfb&chksm=96e9d270a19e5b668875392da1d1aaa28ffd0af17d44f7ee81c2754c78cc35edf2e35be2c6a1&scene=21#wechat_redirect 讲的很详细
attention is all your need 介绍
seq-seq 的encoder -decoder模型
所谓编码,就是将输入序列转化成一个固定长度的向量;解码,就是将之前生成的固定向量再转化成输出序列。编码器和解码器都不是固定的。
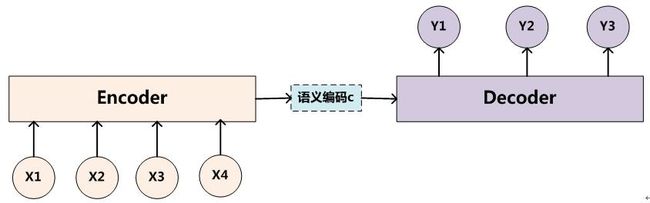
传统的encoder用rnn,但是rnn不适用于并行计算。
attention is all your need
Transformer是第一个完全依靠Self-attention而不使用序列对齐的RNN或卷积的方式来计算输入输出表示的转换模型。
Attention函数是一个查询(query)到一系列(键key-值value)对的映射,如下图。Attention的本质就是加权。
attention 定义
Self-attention即K=V=Q,例如输入一个句子,那么里面的每个词都要和该句子中的所有词进行attention计算。目的是学习句子内部的词依赖关系,捕获句子的内部结构。
Multi-head attentionQuery,Key,Value首先进过一个线性变换,然后输入到放缩点积attention,注意这里要做h次,其实也就是所谓的多头,每一次算一个头。而且每次Q,K,V进行线性变换的参数W是不一样的。然后将h次的放缩点积attention结果进行拼接,再进行一次线性变换得到的值作为多头attention的结果。多头进行多次计算而不仅仅算一次的好处是可以允许模型在不同的表示子空间里学习到相关的信息。
优点:可以捕获长距离依赖关系
李宏毅老师的ppt 真的清楚
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML19.html
transformer
transformer 结构解读
rumer transformer 解读
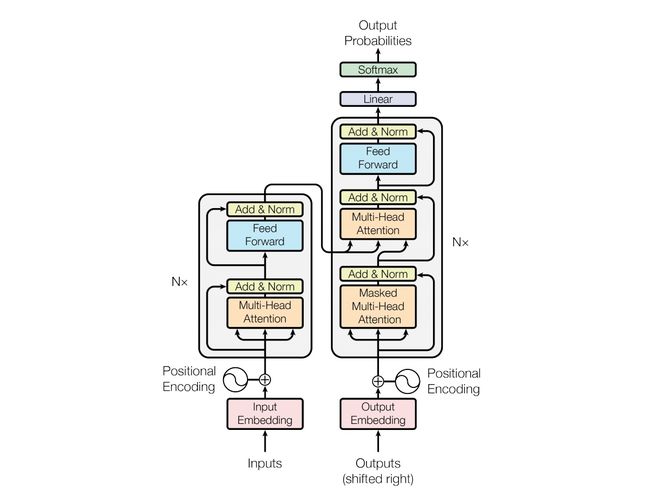
encoder: 6 x (两个子层,第一个是多头注意力,第二层是FFN,FFN的作用就是空间变换。FFN包含了2层linear transformation层,中间的激活函数是ReLu。)add &norm 是残差+归一化。
decoder:Decoder端的Mask的功能是为了保证训练阶段和推理阶段的一致性。token是按照从左往右的顺序推理的。也就是说,在推理timestep=T的token时,decoder只能“看到”timestep < T的 T-1 个Token, 不能和timestep大于它自身的token做attention(因为根本还不知道后面的token是什么)。
**layer normalization **:通用技术,规范优化空间,加速收敛。始终保持左图的样子
**positional encoding:**位置编码是Transformer框架中特有的组成部分,补充了Attention机制本身不能捕捉位置信息的缺陷。


Positional Embedding的成分直接叠加于Embedding之上,使得每个token的位置信息和它的语义信息(embedding)充分融合,并被传递到后续所有经过复杂变换的序列表达中去。Positional Encoding(PE)是正余弦函数,位置(pos)越小,波长越长,每一个位置对应的PE都是唯一的。之所以选用正余弦函数作为PE,是因为这可以使得模型学习到token之间的相对位置关系:因为对于任意的偏移量k, [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YagVE4Hs-1629472899314)(https://www.zhihu.com/equation?tex=PE_%7Bpos%2Bk%7D)] 可以由 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dmujLu6P-1629472899316)(https://www.zhihu.com/equation?tex=PE_%7Bpos%7D)] 的线性表示:
多注意力:
![]()

实验结果:WMT2014的英德和英法机器翻译任务上
Google 论文的主要贡献之一是它表明了内部注意力在机器翻译(甚至是一般的 Seq2Seq 任务)的序列编码上是相当重要的,而之前关于 Seq2Seq 的研究基本都只是把注意力机制用在解码端。
BERT论文
介绍视频
bert 使用代码详解博客
模型
bert 使用 Transfomer Encoder部分
框架:无标签文本上不同任务的预训练 + 初始化预训练参数后,基于下游任务的有标签数据上的finetune。
multi-layer bidirectional Transformer encoder。
BERTBASE (L=12, H=768, A=12,Total Parameters = 110M)。BERTLARGE (L=24, H=1024, A=16, Total Parameters=340M).
- 问题:每一层有什么用呢?有论文认为,浅层关注语法知识;深层关注语义知识。
对weighted sum的权重可视化分析:
WordPiece:数据预处理,把单词分成piece,精简词表、清晰。 比如BPE方法:loved、loving、loves。“lov”,“ed”,“ing”,“es”。所以BERT的词表有30000个token,包括[CLS]对应的最后一层隐层输出作为聚合句子表示、[SEP]然后每个token有segment 嵌入,分辨属于A还是属于B。
输入encoder表示(长度512):
- WordPiece 嵌入[6]:WordPiece是指将单词划分成一组有限的公共子词单元,能在单词的有效性和字符的灵活性之间取得一个折中的平衡。例如图4的示例中‘playing’被拆分成了‘play’和‘ing’;【中文的字相当于piece】
- 位置嵌入(Position Embedding):位置嵌入是指将单词的位置信息编码成特征向量,位置嵌入是向模型中引入单词位置关系的至关重要的一环。位置嵌入的具体内容参考我之前的分析;
- 分割嵌入(Segment Embedding):用于区分两个句子,例如B是否是A的下文(对话场景,问答场景等)。对于句子对,第一个句子的特征值是0,第二个句子的特征值是1。
每一个token的表示 = corresponding token 嵌入 + segment embedding(句子a还是句子b) + 位置嵌入
深层双向模型【深层怎么理解??】】
task 1:MLM
15%的wordpiece被随机mask,实验次数中的每个句子,有80%直接替换为[mask],10%替换为其他任意单词,10%保留token,然后进行预测原始token的概率,交叉熵作为损失。
【消融实验如下】:如果全部mask,模型不含有词汇的信息了,所以100%mask的效果不好。
对于采样比例做的实验:基于特征的方法是,将BERT后四层的输出作为特征。【【【实验怎么做的?看代码】】】基于finetune的方法,就是加上MLP,预测token。
task 2 :NSP
二分类预测,句子间的下一句关系。用[CLS]。
data:
BooksCorpus (800M words) 。English Wikipedia 的纯文本(2,500M words)。[着重指出需要长的连续的文本]
featured-based 和 finetuning 方法
https://zhuanlan.zhihu.com/p/46833276
**feature-based **:
利用语言模型的中间结果也就是LM embedding, 将其作为额外的特征,引入到原任务的模型中,例如在TagLM[1]中,采用了两个单向RNN构成的语言模型,将语言模型的中间结果
引入到序列标注模型中,如下图1所示,其中左边部分为序列标注模型,也就是task-specific model,每个任务可能不同,右边是前向LM(Left-to-right)和后向LM(Right-To-Left), 两个LM的结果进行了合并,并将LM embedding与词向量、第一层RNN输出、第二层RNN输出进行了concat操作。
通常feature-based方法包括两步:
- 首先在大的语料A上无监督地训练语言模型,训练完毕得到语言模型
- 然后构造task-specific model例如序列标注模型,采用有标记的语料B来有监督地训练task-sepcific model,将语言模型的参数固定,语料B的训练数据经过语言模型得到LM embedding,作为task-specific model的额外特征
ELMo是这方面的典型工作,ha请参考[2]。
好处:1.仅仅transformer表达效果不够。2.在大型LM词表示的基础上进行训练,有很多好处,很大增益。(因为大型LM可以看作很好的初始化)。
finetune:
单个线性层+非线性函数输出(如softmax)。
token级
句子级别的判断,用[CLS]。
比较两者:
CoNLL-2003 Named Entity Recognition (NER) task
使用场景
case1:输入:句子; 输出:类别 情感分析、文章分类
输入句子,给定输出的标签,两部分一起学:线性分类层从头学,bert只需要微调(finetune)。
case2:输入:句子 ;输出:每一个单词的类别 slotfilling
case:输入:两个句子;输入:类别 NLI 句子关系推理:给定前提,假设对/错/无法判断
用CLS输入线性层进行分类
case5:抽取式问答 输入:语段文件,问题;输出:答案的span(文段中的开始位置s、结束位置e)
[CLS]问题[SEP]文段 ,学习两个embedding【s和e】,将s、e分别和d中的token做注意力点积匹配,得到一个标量,再做softmax。图中s匹配的第二个位置分数最高,则第二个是答案开始。同理第三个位置是答案结束。答案span为d2d3。
learn from scratch指重新学 ,bert只需要finetune
编程
[PAD]:zero padding 遮罩,將長度不一的輸入序列補齊方便做 batch 運算。[UNK]:沒出現在 BERT 字典裡頭的字會被這個 token 取代。
bert编码实践
embedding:1 token tensors 识别每个token的索引值,用 tokenizer 轉換即可;2.segments_tensor: 用來識別句子界限。第一句為 0,第二句則為 1。另外注意句子間的 [SEP] 為 0。3. masks_tensor: 用來界定自注意力機制範圍。1 讓 BERT 關注該位置,0 則代表是 padding 不需關注。
[PAD]:輸入序列長短不一,為了讓 GPU 平行運算我們需要將 batch 裡的每個輸入序列都補上 zero padding 以保證它們長度一致。另外 masks_tensor 以及 segments_tensor 在 [PAD] 對應位置的值也都是 0。
每個藍色字體都對應到一個可以處理下游任務的模型,而這邊說的模型指的是已訓練的 BERT + Linear Classifier。
# 載入一個可以做中文多分類任務的模型,n_class = 3
from transformers import BertForSequenceClassification
PRETRAINED_MODEL_NAME = "bert-base-chinese"
NUM_LABELS = 3
model = BertForSequenceClassification.from_pretrained(
PRETRAINED_MODEL_NAME, num_labels=NUM_LABELS)
clear_output()
# high-level 顯示此模型裡的 modules
print("""
name module
----------------------""")
for name, module in model.named_children():
if name == "bert":
for n, _ in module.named_children():
print(f"{name}:{n}")
else:
print("{:15} {}".format(name, module))
一行程式碼就初始化了一個可以用 BERT 做文本多分類的模型 model。我也列出了 model 裡頭最 high level 的模組,
包括:bert 的embedding模块;encoder ;一个[CLS]在所有层的表示的BertPooler。dropout层;回传3个类别的线性分类器 classifier:因为是句子分类任务,所以将CLS的表示做一个线性变换。
bert 能力总结:
- BERT的encoder框架很适合做自然语言理解NLU任务,但是如文章摘要等自然语言生成任务NLG,不太适合。抽取式摘要:BertSum 在 CNN/Dailymail 取得 SOTA 的研究。
- UniLM通过注意力[MASK]可以在预训练阶段同时训练3种语言模型,针对finetune NLG任务。
- 最近最好的NLP模型是XLNet,但是花费很多。
- 巨人脊髓已经掌握了,我们墙外见吧。
bert family
PTMs的分类标准:
- 表示类型:上下文无关和上下文相关;
- 架构:LSTM (例如ELMo), Transformer的encoder (例如BERT),Transformer的Decoder (例如GPT),以及同时使用Transformer的Encoder和Decoder (例如, Seq2Seq MLM)。
- 预训练任务类型,如传统自回归LM,Masked-LM,Permuted-LM, DAE, CTL, 等。
- 扩展:例如,知识强化的PTMs,多语言或者单语言PTMs,多模态PTMs,特定领域PTMs(例如Healthcare, Finance等),以及压缩PTMs。
- albert的参数比bert小,但是效果比bert稍微好一点。
-
ELMO:94m
双向的LSTM,正逆向的模型没有交会。任务是预测下一个token。无法同时编码双向的信息。

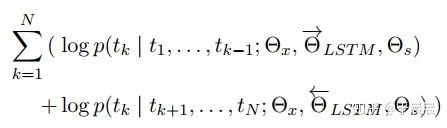
最大化前&后向似然函数。前后向网络共享参数(embedding 的X 和LSTM的S)
嵌入 由所有层【原始token+第一层lstm+第二层lstm】的前向后向加权sum,然后作为任务模型的输入。其中这个权重是和任务模型一起由任务学出来的(task-specific)。
ERNIE:为中文设计。wwm
在bert基础之上引入外部知识图谱的信息,增强模型对于专有名词的解释。文本编码层和知识信息混合编码层进行融合。类似模型:K-BERT,knowBERT。
在信息抽取等一些需要知识信息的任务上有提升。
GPT-2:1542m 非常巨大
架构就是transformer 的decoder,从左到右由已生成的输出。
神迹:zero-shot 不需要训练资料可以达到任务高准确率。
阅读理解很好,文本摘要很差。生成任务很好!
可视化分析:
demo: 只用了小版本的GPT2 (大概和bert 差不多)大的GPT2没放出来。https://app.inferkit.com/demo
multilingual BERT:104种语言
学会了语言的对应关系。自动可以将不同语言的任务进行迁移。
语言模型
三种预训练语言模型的类型:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xonmwyZc-1629472899326)(C:\Users\朱朱\AppData\Roaming\Typora\typora-user-images\image-20210613230714602.png)]
不同预训练语言模型的任务
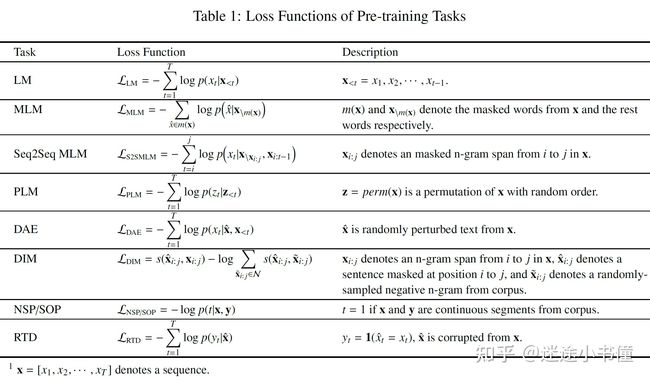
- LM = 自回归语言模型, auto-regressive language models
- MLM = 遮掩语言模型,masked language models
- Seq2Seq MLM=序列到序列的遮掩语言模型,Sequence-to-Sequence Masked Language Model;
- PLM = Permutated language model, 重新排列语言模型
- DAE = 去噪自编码器,denoising auto-encoder
- DIM = Deep InfoMax,深度-信息-最大化?不好翻译
- NSP/SOP=next sentence prediction, sentence ordering prediction, 下一个句子预测,句子顺序预测;
- RTD = replaced token detection, 被替换掉的token的检测
2维位置编码:
对于自回归模型,将分类任务转化为生成任务。
-
[RoBERTa] (RoBERTa: A Robustly Optimized BERT Pretraining Approach)
动态mask改进BERT
-
XLMs
跨语言语言模型,在双语序列上执行MLM。对翻译任务,把双语的两句话通过[sep]连接输入,进行MLM。
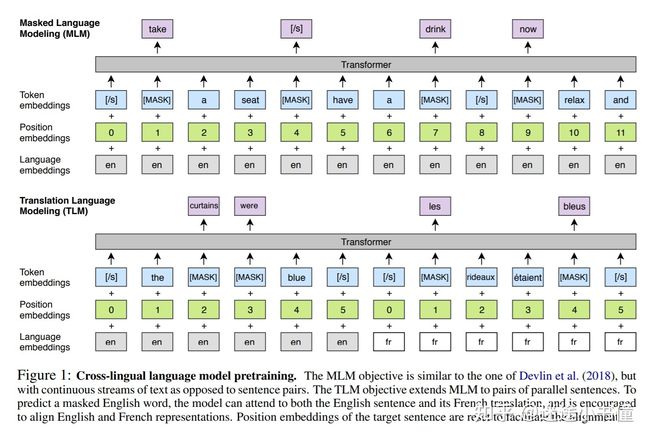
-
spanBERT
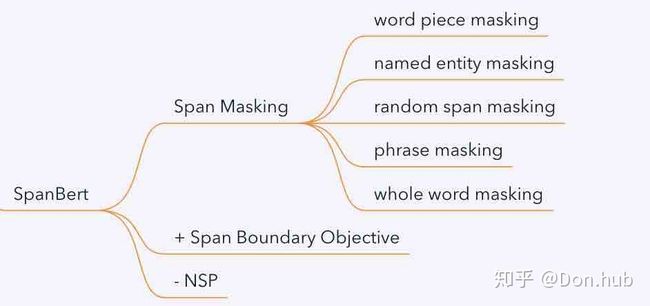
**相对于bert的改进:**去掉NSP任务:albert中说明NSP任务太简单,只学会了top的信息。
1 span masking:没有segment embedding ;预测一个范围span内的所有的token,而不是随机选择若干相对独立、不连续的tokens。
2 MLM+SBO :**span-SBO **Span Boundary Objective:编码信息有:左边嵌入、右边嵌入、数字(预测第几个位置)。假设:左右两边的token能包含整个span的资讯。
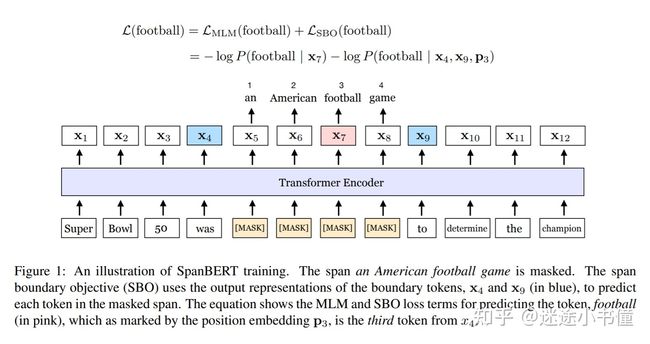
loss:mask位置的loss -log(true token|LM 在该位置输出的token)加上SBO的loss:-log(true token| 左边界嵌入,右边界词嵌入,对应位置的输出)
span 选择:概率分布的期望
wwm:一次掩盖一整个word,预测wwm。phrase-level、entity-level:ERNIE。spanbert:一次随机选举长度的token序列。spanbert比较了不同的。
pretrain 的方式会有特定表现好的几个任务。
引入语言的结构信息
-
structBERT:类似DAE的思想
将word-objective 和 MLM-objective联合训练。“word-objective”:给定一个被打乱顺序的序列,尝试预测每个被移位的词的原始正确的位置。

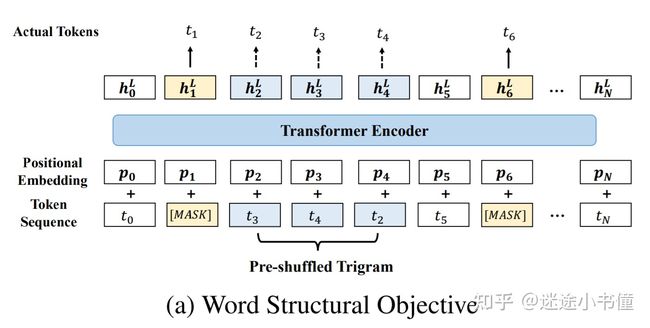
-
XLNet
XLNet:transformer-XL !!Permuted Language Modeling (PLM):随机mask会导致整个词的token是独立的。方法:打乱语料的token顺序,不给看mask,但是给mask的位置。对一个输入序列构造所有可能的全排列,然后选择其中一个全排列,此后,该全排列中的若干词被选择为target,而模型被训练为预测这些targets, 基于的是:剩余的tokens以及targets的原始的正确的位置信息。【主要是预测的顺序改变】
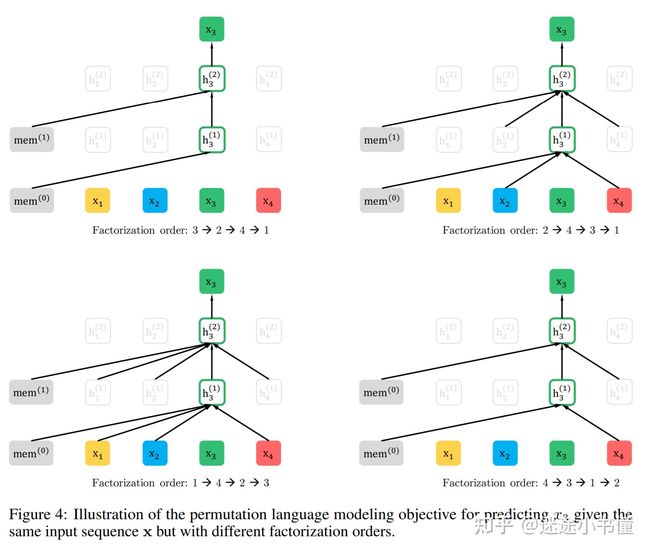
首先说BERT:
bert不擅长生成任务? 不适合seq2seq的任务【因为是mask训练的,所以只适合当encoder,decoder就不合适】,不适合autoregressive (自回归)任务
MASS/BART:seq2seq结构 的目标:重构句子结构(破坏的句子——原始句子)
MASS:随机mask(mass)/
bart:自监督的训练任务。训练端到端的模型
删除 / 旋转/打乱/text infilling(插入多个mask,或者掩盖多个token,模型自己猜)还原mask的地方。旋转和打乱效果不好。text infilling效果好。
既解决文本理解任务,也解决文本生成任务。
T5:将下游任务统一为类似生成任务。基于海量数据(C4)进行训练,相较于BART 更为强悍(鲁棒)。
MoE:混合多个专家的处理能力,共同执行任务。增长参数但是不增长计算量。expert为一个模型,多个专家共同解决问题,基于可信度构成结果。
MoE +lstm (google)
switch transformer 万亿。模型的系数程度变高,空心的。性能不如同样参数量的实心模型,但是比小的实心模型效果好。
UniLM:既是编码也是解码,可以同时进行三种训练。但是有一些规则。
ELECTRA:不做预测,回答二分类问题。不做mask,而是置换成其他的token,预测有没有被置换。每一个token都有error 。训练数据集:smallBERT产生语法没有问题,语义怪怪的问题的句子。再输入ELECTRA来判别。有点像GAN。
GLUE结果:
运算量越来越多,效果越来越好。ELECTRA需要四分之一的参数,但是效果好。
sentence 嵌入:skip-thought 预测下一个句子的任务。quick-thought:避开生成,用嵌入的距离来衡量。
[CLS]:NSP:用cls来做nsp任务,二分类(需要cls向量有全句子的理解)。
roberta:nsp没有用。数据集相当于扩大。效果比bert好,说明bert当时还没收敛。
SOP sentence order prediction : 一对句子的顺序 说yes or no。ALBERT。sop任务比nsp更难。
structBERT:(alice)有类似SOP的任务。
albert:12层参数共享,效果降低不大,但是参数大大降低。
T5:谷歌,把预训练的所有方法尝试了。 其中C4是模型。
ERNIE:加入外部知识
audio-bert
如何产生好的词向量:模型、语料、参数
模型: 简单的模型(Skip-gram)在小语料下表现好,复杂的模型在大语料下略有优势。(不过现在都是bert)
语料:语料的领域比语料的大小更重要。
参数:迭代次数和词向量的维度。
师兄分析了很多实验的对比。我学到的:设定任务来选择最好的词向量,不如直接根据下游任务,设计和下游任务一致的目标,直接把实际任务的验证集作为终止条件。同时
那如果词向量和下游探测任务相关度这么大,
prompt tuning
假设:模型已经足够聪明,只是诱导的方式不够好。
方式:加入 prompt,it was ____(预测)
PET:pattern-exploiting training
人工定义多个模板,转化为MLM的问题,多个模板训出的模型之间ensemble(同时的)。
autoprompt
自动构建的模板效果不如手动构建的。
类似于梯度的在离散的空间搜索,但是效果比LAMA和LPAQA要好。
思考:能否放到连续空间取搜索最优解。
P-tuning:连续空间搜索最优解
连续:将离散的词变为可以学习的连续的向量。 64.2%
learning how to ask 自动模板的分析
GPT understand,too :构建模板加入GPT,在理解任务上的性能甚至好于bert
PTR :用rules 构建prompt
谷歌的工作:随机扔进token ,自动学模板,在模型很大时学到的效果很好。
P-tuning (插入连续向量)预训练语言模型与小样本理解
想法:GPT在NLU任务上表现不佳
- 是都是因为finetune 不适合GPT
- 是都是仅仅因为基于embedding的分类方法不适合GPT
GPT在生成任务上: stanford
在transformer的每一层插入连续的向量,可以独立训练的,超过finetune的效果
几乎都超过finetune
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qrTpxMhk-1629472899327)(C:\Users\朱朱\AppData\Roaming\Typora\typora-user-images\image-20210613224348111.png)]
super-glue 上的验证
P-TUNING之后,GPT 的效果立马超过bert。对于bert也有少量的提升。
bert在大量参数的情况下的问题:百亿参数情况下没法finetune;会出现很强的不稳定性。
所以提升GPT在理解上的能力提升很有意义
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F2iPbJAk-1629472899329)(C:\Users\朱朱\AppData\Roaming\Typora\typora-user-images\image-20210613224508974.png)]
构造更小的小样本测试集。 p-tuning 都远超pet。
p-tuning 相对于人工模板的优点:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z5yFxnjF-1629472899331)(C:\Users\朱朱\AppData\Roaming\Typora\typora-user-images\image-20210613225131768.png)]
超大模型finetune的代价太大。但是p-tuning的参数需要的很少。
finetune 在模型参数增加之后慢慢达到饱和,但是p-tuning 始终线性增长。百亿效果差相当了。因为p-tuning的参数需要量很少。
华为的盘古千亿模型采取的p-tuning的方式进行下游迁移。
问题:对于不同scale模型的参数选择:向量输入prompt-encoder(LSTM:处理序列+提供很好的非线性性),不同任务表现不一样。token数量:lama个位数(9/8)。super-glue。大参数的模型需要一百多个token。
【稳定性】搜的sead 足够多,模型能够得到足够的提升。
probing
大模型知识含量是很高的【论文呢?????】
大模型知识量够了,重要的是【诱导】模型发挥效果。
CPM 盘古 等中文模型,怎样控制输出的随机性:微调可以实现一定的可控。需要具体的任务输入引导。
预训练模型做理解任务(分类)效果比较好,但是做生成任务效果不好(需要加额外的东西,没有逻辑)。
/>
finetune 在模型参数增加之后慢慢达到饱和,但是p-tuning 始终线性增长。百亿效果差相当了。因为p-tuning的参数需要量很少。
华为的盘古千亿模型采取的p-tuning的方式进行下游迁移。
问题:对于不同scale模型的参数选择:向量输入prompt-encoder(LSTM:处理序列+提供很好的非线性性),不同任务表现不一样。token数量:lama个位数(9/8)。super-glue。大参数的模型需要一百多个token。
【稳定性】搜的sead 足够多,模型能够得到足够的提升。
probing
大模型知识含量是很高的【论文呢?????】
大模型知识量够了,重要的是【诱导】模型发挥效果。
CPM 盘古 等中文模型,怎样控制输出的随机性:微调可以实现一定的可控。需要具体的任务输入引导。
预训练模型做理解任务(分类)效果比较好,但是做生成任务效果不好(需要加额外的东西,没有逻辑)。