神经网络的解释方法之GAP、CAM、Grad-CAM、Grad-CAM++的理解
目录
- GAP&CAM
- Grad-CAM
-
- 实践部分
- Grad-CAM++
卷积神经网络的解释方法之一是通过构建类似热力图 (heatmap) 的形式,直观展示出卷积神经网络学习到的特征,当然,其本质还是从像素的角度去解释卷积神经网络。
在深度学习的可解释性研究中比较经典的研究方法是采用反卷积(Deconvolution)和导向反向传播(Guided-backpropagation)等。而随着Network In Network网络的提出,GAP(全局平均池化)的概念被我们所熟知。基于此,论文Learning Deep Features for Discriminative Localization中提出了CAM(类激活映射)用于可视化卷积神经网络的热力图。由于CAM方法需要替换全连接层为 GAP 层,需要重新训练模型。为解决CAM的该缺陷,论文Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization提出了Grad-CAM(直译为梯度加权类激活映射)。Grad-CAM 和 CAM 基本思路一样,区别就在于Grad-CAM通过梯度的全局平均来计算每个特征图的权重(论文中论证了Grad-CAM与CAM两种获取权重方法是否等价的详细过程)。在论文Grad-CAM++: Generalized Gradient-based Visual Explanations for Deep Convolutional Networks中阐述了Grad-CAM++相对于Grad-CAM 而言,其效果更好,尤其是在某一分类物体在图像中不止一个的情况下。其主要的变动是在对应于某个分类的特征映射的权重中加入了激活函数和权重梯度。
GAP&CAM
参考:
- global-average-pooling-layers-for-object-localization
- Learning Deep Features for Discriminative Localization
如果要了解CAM,前提要先了解一下什么是GAP。GAP (Global Average Pooling,全局平均池化),在Network In Network (arxiv.org)中提出,用于避免全连接层的过拟合问题。GAP层,顾名思义,就是对整个特征映射应用平均池化,换句话说,是一种极端激进的平均池化,将一个channel的特征进行池化操作,最终生成一个特征。如下图,将原本 h × w × d h \times w \times d h×w×d 的三维特征图,具体大小为 6 × 6 × 3 6 \times 6 \times 3 6×6×3,经过GAP池化为 1 × 1 × 3 1 \times 1 \times 3 1×1×3输出值。也就是每一个channel的 h × w h \times w h×w平均池化为一个值。
当然除了GAP外,还有GMP(Global Max Pooling,全局最大池化),对每个channel进行最大池化操作,池化为一个值。

特征图经过 GAP 处理后每一个特征图包含了不同类别的信息,其具体效果如下图的 Class Activation Mapping 中的图片所示。其中 f k f_k fk表示经过卷积操作后的第 k k k个channel所代表的feature map(也即在GAP之前的所对应的第 k k k个channel)。而 ω k \omega_k ωk则表示经过GAP后分类概率最大的神经元所对应连接的第 k k k个神经元的权重(这里需要注意,只对单物体而言的)。CAM也就是利用特征图权重叠加的原理获得热力图。
在一段时间内,很多分类问题的网络结构在描述时都是由两部分构成:特征提取(features)+分类器(classifier)。常用的特征提取是卷积神经网络,而分类器则是将特征提取后的feature map进行展平处理,并使用全连接来映射为类别信息。而在Network In Network网络中,随着GAP的提出,将分类器由原来的展平处理改为GAP。能够有效的减少参数,且能够避免过拟合等情况。
一个深层的卷积神经网络,通过层层卷积操作,提取空间和语义信息。但是网络后面一般存在其他更难理解的层,例如分类的全连接层、softmax层等,很难以利用可视化的方式展示出来。因此考虑使用卷积层的最后一层feature map提取出CAM。
基于该理论,以github中ResNet50为例,代码使用Keras中tensorflow.keras.applications.resnet50网络实现的热力图。在网络实现过程中,前面部分是残差卷积块+GAP+predictions。(通过打印出最后一层的卷积模块与GAP模块(其实就是avg_pool)以及predictions模块的结构查看一下。)
from tensorflow.keras.applications.resnet50 import ResNet50
ResNet50().summary()
输出:
*****
__________________________________________________________________________________________________
conv5_block3_3_conv (Conv2D) (None, 7, 7, 2048) 1050624 conv5_block3_2_relu[0][0]
__________________________________________________________________________________________________
conv5_block3_3_bn (BatchNormali (None, 7, 7, 2048) 8192 conv5_block3_3_conv[0][0]
__________________________________________________________________________________________________
conv5_block3_add (Add) (None, 7, 7, 2048) 0 conv5_block2_out[0][0]
conv5_block3_3_bn[0][0]
__________________________________________________________________________________________________
conv5_block3_out (Activation) (None, 7, 7, 2048) 0 conv5_block3_add[0][0]
__________________________________________________________________________________________________
avg_pool (GlobalAveragePooling2 (None, 2048) 0 conv5_block3_out[0][0]
__________________________________________________________________________________________________
predictions (Dense) (None, 1000) 2049000 avg_pool[0][0]
==================================================================================================
Total params: 25,636,712
Trainable params: 25,583,592
Non-trainable params: 53,120
__________________________________________________________________________________________________
在代码中,需要获得GAP之前的feature map图每层 f k f_k fk与之对应的权重 ω k \omega_k ωk。
由
mode.get_layer(self, name=None, index=None)通过名字或者索引获取网络结构的某一层,通过model.layers来获取整个网络结构中的所有层的集合。基于此,我们就可以通过对层操作而获得相对应的东西。比如:layer.get_weights() # 返回该层的权重 layer.set_weights(weights) # 将权重加载到该层 config = layer.get_config() # 保存该层的配置 layer = layer_from_config(config) # 加载一个配置到该层 # 该层有一个节点时,获得输入张量、输出张量、及各自的形状: layer.input layer.output layer.input_shape layer.output_shape # 该层有多个节点时(node_index为节点序号): layer.get_input_at(node_index) layer.get_output_at(node_index) layer.get_input_shape_at(node_index) layer.get_output_shape_at(node_index)那么获取 f k f_k fk与权重 ω k \omega_k ωk的方式如下(仅适用于ResNet50,其他类似,名字或者层的索引不一定是这个,可以通过
model.summary()查看一下)# 获取feature map,三种方式一样的,注意这里是要在激活函数之前的特征图(至于理由,可以想一下激活函数的作用,主要是控制在0-1之间,方便收敛) model.get_layer(name='conv5_block3_add').output model.get_layer(index=-4).output model.layers[-4].output # 获取权重, # 通过model.get_weights()获取模型的全部参数(返回一个列表数组,第一层W,第一层b,第二层W,第二层b,...) model.layers[-1].get_weights()[0] model.get_layer(name='predictions').get_weights()[0] model.get_layer(index=-1).get_weights()[0] # 那么回到模型,如果一张图片,输入到网络中,然后预测出其为第m类,那么我只需要与最后一层中第m个神经元相连接的神经元的权重作为我们所需要的权重。即最终权重w1,w2,w3...获取如下: model.layers[-1].get_weights()[0][:, m]当获取了特征图 f k f_k fk与权重 ω k \omega_k ωk后,其热力图可根据公式
C A M = ∑ k = 1 n ω k f i CAM=\sum_{k=1}^n{\omega _kf_i} CAM=k=1∑nωkfi
但是由于特征图 f k f_k fk 是由原始图像卷积、池化等操作而来的,卷积、池化操作一般会使图像尺寸变小,因此为了能使热力图与原始图进行比较,可使用类似目标检测中的建立原图ROI与fearure map映射关系或者上采样。代码中为了简便,使用了双线性上采样,调用函数scipy.ndimage.zoom 将feature map上采样为原图大小一致。双线性上采样理论部分参考双线性插值(Bilinear interpolation) - Mr.Easy - 博客园 (cnblogs.com)# 将 (7,7,2048) --> (224,224,2048) mat_for_mult = scipy.ndimage.zoom(last_conv_output, zoom=(32, 32, 1) order=1) # zoom表示:沿轴的缩放系数,如果是浮点型,表示每个轴的缩放是相同的,如果是序列,zoom应包含每个轴的缩放值 # 这里的(32, 32, 1)表示长宽缩放系数相同,为(224/7),而channel缩放系数为1表示不缩放。如果是pytorch实现的话,因为pytorch是使用动态图,不会保存计算过程中的梯度信息,所以,对于feature map的获取没那么容易,可以自己设置保存梯度信息或者使用hook来实现,具体后面有点介绍。
其实 CAM 得到的效果已经很不错了,但是由于其需要修改网络结构且对模型需要重新训练,这样就导致其应用起来很不方便(其实在keras中,很多网络结构都摒弃了原有的将特征图展平处理,而改为GAP)。这样的处理方式对于一些没有GAP的模型是行不通的,Grad-CAM 很好的解决了这个问题,具体继续往下看。
Grad-CAM
参考:Grad-CAM: Why did you say that?
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization (arxiv.org)
说明一下,两篇论文其实差不多,第一篇主要说明分类问题。第二篇相对于第一篇加了点内容,提出只要是可微分的激活函数都可以用该方法输出热力图。
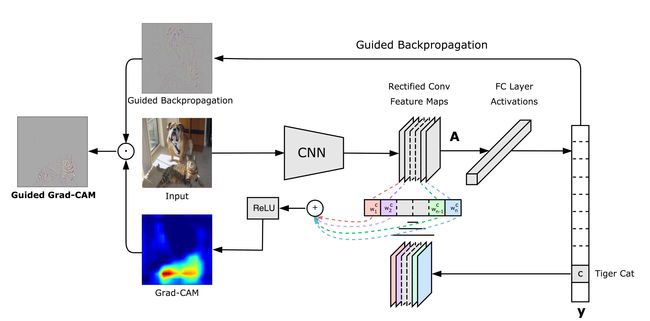
Grad-CAM 全称是:Gradient-weighted Class Activation Mapping,直译是梯度加权类激活映射。其基本思路与CAM类似,也是利用特征图权重叠加的原理获得热力图。那么问题就是如何获取特征图的权重。Grad-CAM中是通过对特征图的梯度的全局平均来计算权重。其中最重要的两个公式如下:(求取特征图的权重,以及获取Grad-CAM热力图的公式)。
ω k c = 1 Z ∑ i ∑ j ∂ y c ∂ A i j k \omega_k^c=\frac{1}{Z} \sum_i \sum_j \frac{\partial y^c}{\partial A_{i j}^k} ωkc=Z1i∑j∑∂Aijk∂yc
其中,
- ω k c \omega_k^c ωkc 表示:第 k k k 个特征图对应于类别 c c c 的权重,用于后面计算热力图的梯度
- Z Z Z 表示:特征图的像素个数。
- y c y^c yc 表示: 第 c c c 类得分的梯度.
- A i j k A_{i j}^k Aijk 表示: 第 k k k 个特征图中坐标 ( i , j ) (i, j) (i,j) 位置处的像素值;
当求得所有的特征图对应的类别的权重后进行加权求和,便可得到对应的热力图。在论文中,有解释因为热力图关心的是对分类有正面影响的特征,所以在线性组合的技术上加上了ReLU,以移除负值。公式如下:
L G r a d − C A M c = r e l u ( ∑ k ω k c A k ) L_{Grad-CAM}^c=relu\left(\sum_k \omega_k^c A^k\right) LGrad−CAMc=relu(k∑ωkcAk)
其中,
- A k A^k Ak 表示:第 k k k 个特征图
- ω k c \omega_k^c ωkc 由上述公式计算
在论文Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization (arxiv.org)中说是只要可微分的激活函数都可以用该方法输出热力图,因此该方法不仅仅应用于分类问题。具体论证可以去看一下推导过程。

对于公式怎么理解呢?
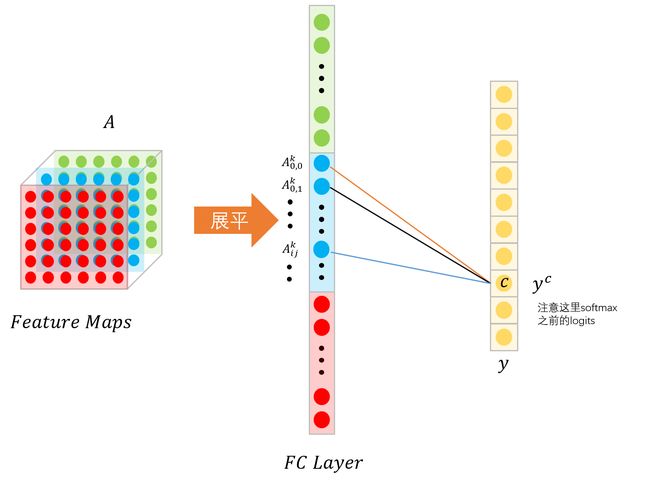
以之前的卷积后特征图展平处理来举例说明,展平处理后,假设某个特征图上的特征点被映射到神经元区间中,如图:
以上图为例,设该特征图 A A A 最终被网络预测为 c c c 类,并且输出的概率为 y c y^c yc 。那么在 y c y^c yc 中有多少是由于第 k k k 层特征图所导致的?
由第 k k k层的特征图的第 i i i行,第 j j j列的像素值为 A i j k A_{i j}^k Aijk , 那么由该像素所导致预测为 y c y^c yc的权重为 ∂ y c ∂ A i j k \frac{\partial y^c}{\partial A_{i j}^k} ∂Aijk∂yc。那么将特征图 k k k 层中每个像素点所导致预测 y c y^c yc的权重求和平均一下,也就是 1 Z ∑ i ∑ j ∂ y c ∂ A i j k \frac{1}{Z} \sum_i \sum_j \frac{\partial y^c}{\partial A_{i j}^k} Z1∑i∑j∂Aijk∂yc。
实践部分
代码参考:
对于pytorch代码实现可以查看代码(包括对CNN,Transfomation,分类,目标检测,语义分割的热力图可视化都支持):GitHub - jacobgil/pytorch-grad-cam,说明Docs。Grad-CAM的作者还将Grad-CAM和可视化所有有贡献的特征的技术Guided-Backprop结合,得到了
Guided Grad-CAM。这个时候就不是热力图了。tensorflow参考:GitHub - hiveml/tensorflow-grad-cam: Tensorflow Slim Grad-Cam to Explain Neural Network Predictions with Heatmap or Shading
也有keras代码实现:An implementation of Grad-CAM with keras
这里以pytorch代码为例进行阐述,主要是对hook编程进行说明。在pytorch前向传播的过程中,会动态生成计算图;而在反向传播过程中,对计算图中的每个模块的输入输出求解梯度,并把梯队回传到输出。在反向传播过程中为了减少内存消耗,会把传播过程中产生的梯度删除,仅保留计算图中叶子节点的梯度信息。但是CAM等任务需要在不改变网络结构的基础上有效获取中间变量以及梯度等信息,即获得神经网络中间层输入输出的梯度值。这时,需要使用hook机制实现这个目标。hook机制在pytorch中主要先注册一个钩子(hook),通过传入一个hook()函数来实现。hook()函数翻译为钩子函数:因为神经网络的主任务是反向传播更新梯度,而钩子函数就是挂在主任务上的辅任务。
hook机制主要非为两类:
- 基于Tensor的hook机制,方便追踪某个特定张量的梯度
- 基于Module的hook机制,主要用于获得某层的输入输出的梯度
主要的注册钩子方法有:
- torch.Tensor.register_hook:为某个需要梯度的中间变量注册一个钩子
- torch.nn.Module.register_forward_hook:反向传播每次经过该模块,该模块注册的钩子都会被调用。
- torch.nn.Module.register_backward_hook:为网络中某个模块注册一个反向传播钩子,用于获得反向传播时该模块的梯度,反向传播每次经过该模块,该模块注册的钩子都会被调用。
- torch.nn.Module.register_forward_pre_hook
使用的时候需要注意:钩子函数无法改变传入的实参值,但可通过新建变量的方式对传入的实参值进行相关计算从而返回新的梯度以取代原始梯度值。并且在使用完后需要及时清除:Tensor直接用
hook.remove(),网络模块使用其返回的handle然后remove即可,以便节省内存。hook的具体细节可参考:PyTorch之HOOK——获取神经网络特征和梯度的有效工具,pytorch hook机制
在GitHub - jacobgil/pytorch-grad-cam代码中,对可视化进行了封装,只要用就可以,但是如果要深入研究一下,会发现,在pytorch-grad-cam/activations_and_gradients.py代码中使用了hook,用于获取对应的feature map。
Grad-CAM++
论文参考:[1710.11063] Grad-CAM++: Improved Visual Explanations for Deep Convolutional Networks (arxiv.org)
为了说明规范,论文中的梯度权重 ω i j k c \omega_{ij}^{kc} ωijkc 替换为了 ω k , i , j c \omega_{k,i,j}^c ωk,i,jc
Grad-CAM++与Grad-CAM一样,都是基于假设:
-
对于 c c c 类的输出分数(logits,也就是在softmax之前的预测分数)获取是权重 ω k , i , j c \omega_{k,i,j}^c ωk,i,jc 和特征图 A i , j k A_{i,j}^k Ai,jk点积而来:
y c = ∑ k ∑ i ∑ j ω k , i , j c ⋅ A i , j k y^c = \sum_k \sum_i \sum_j \omega_{k,i,j}^c \cdot A_{i,j}^k yc=k∑i∑j∑ωk,i,jc⋅Ai,jk在Grad-CAM中分为 c c c 类分数由特征图第 k k k 层所导致的权重 ω k c \omega_{k}^{c} ωkc 使用 1 i × j ∑ i ∑ j ω k , i , j c \frac{1}{i \times j}\sum_i \sum_j \omega_{k,i,j}^c i×j1∑i∑jωk,i,jc 来表示。Grad-CAM++获取权重方式更加复杂而已。
-
利用特征图权重叠加的原理获得热力图。
在Grad-CAM++中,通过对像素级梯度求加权平均来获得特征图的权重,其权重获取公式如下:
ω k c = ∑ i ∑ j [ ω k , i , j c ⋅ r e l u ( ∂ y c ∂ A i j k ) ] \omega_k^c=\sum_i \sum_j [ \omega_{k,i,j}^c \cdot relu(\frac{\partial y^c}{\partial A_{i j}^k}) ] ωkc=i∑j∑[ωk,i,jc⋅relu(∂Aijk∂yc)]
其中,
- ω k c \omega_k^c ωkc 表示:第 k k k 个特征图对应于类别 c c c 的权重,用于后面计算热力图的梯度
- ω k , i , j c \omega_{k,i,j}^c ωk,i,jc 表示:权重梯度,是对于将图片分类为第c类得分对第 k k k 个特征图中坐标 ( i , j ) (i, j) (i,j) 位置处的像素的梯度(权重)。
- y c y^c yc 表示: 将图片分类为第 c c c 类得分(softmax之前的logits)
- A i j k A_{i j}^k Aijk 表示: 第 k k k 个特征图中坐标 ( i , j ) (i, j) (i,j) 位置处的像素值;
上述公式中提供了获取权重的方法,但是由于在使用过程中,该方法计算比较繁琐,论文[Improved Visual Explanations for Deep Convolutional Networks 中的Methodology中提供了一种计算梯度权重 ω k , i , j c \omega_{k,i,j}^c ωk,i,jc的方法,具体的可以去看论文,实现的话只要会用就行。
在论文中,给出了CAM、Grad-CAM++与Grad-CAM获取热力图的方式,三种方式获取的热力图都是基于特征图权重叠加的原理,只是获取权重 ω k c \omega_k^c ωkc 的方式不一致而已。

而代码实现可以参考:GitHub - jacobgil/pytorch-grad-cam