【PointRCNN深度解读【详尽版】--原理和代码结合】
PointRCNN深度解读【详尽版】
- 前言
- 网络结构
-
- *a. Bottom-up 3D Proposal Generation*
-
- Point Cloud Encoder-Decoder
- Foreground Point Segmentation
- Bin-based 3D Box Generation
- 从代码角度来解读
- *b. Canonical 3D Box Refinement*
-
- Point Cloud Region Pooling
- Canonical Transformation
- Merged Features
- Bin-based 3D box Refinement and Confidence Prediction
- 代码部分
- 总结
- 参考
前言
这周终于接触3D目标检测的内容,以前的PointNet和PointNet++都是讲述的分类和分割的问题。从PointRCNN开始难度好像一下子升级了,网络结构比较复杂,代码量巨大,花费了差不多一周的时间才理解了个大概,不敢说多,所以做个笔记再回顾下其内容,避免遗忘。还是老规矩结合代码从论文的网络结构一步步的解析。
论文: PointRCNN
代码: 点开它
网络结构

整体的思路主要分为两步:
- 前景点的分割以及3D预测框的生成
- 对框的微调优化
具体的细化过程如下:
a. Bottom-up 3D Proposal Generation
这个阶段的主要目的就是利用主干网络提取特征,分割原始点云同时从分割的前景点生成3D Proposal,基于这种自底向上的策略,可避免在3D空间中使用大量预定义的3D框,并且显著限制了生成的3D提案的搜索空间。
Point Cloud Encoder-Decoder
主干网络提取特征,作者用了PointNet++(不了解的可以点进去看我另一篇博客),另外主干网络也可以采用其他如VoxelNet等。
Foreground Point Segmentation
提取特征后分割原始点云,生成所需要的前景点,包含了预测目标位置和方向的丰富信息。另外由于前景点远比背景少,故使用Fcoal loss 来区分前景与背景,Focal loss本身是为了减少容易分类的样本的权重,将权重尽量集中于难分类样本上。

论文中 αt= 0.25,γ= 2。
Bin-based 3D Box Generation
作者在论文中提出了一种基于Bin的方法,使模型训练的时候能够更快的收敛。如下图:

可以看到,作者采用鸟瞰的方式,设定一个在X-Z平面的搜索范围S,每个搜索范围被划分成等长δ 的bins来表示不同的物体在X-Z平面的中心( x , z )。在论文中发现,对X- Z轴使用基于bin的交叉熵损失比直接使用smooth L1 loss 回归能够更加精准得出定位结果。
对于X,Z轴的定位loss由两部分组成:
- 沿着每个X,Z轴的bin分类
- 被分好类的bin中的残差回归
对于Y轴直接使用smooth L1 loss回归,因为大部分物体的y 值都在一个很小的范围内,使用L 1 loss足够获得精准的y 值。

( x ( p ) , y ( p ) , z ( p ) x^{(p)},y^{(p)},z^{(p)} x(p),y(p),z(p))是FPO I(foreground point of interest )的坐标。
( x p , y p , z p x^{p},y^{p},z^{p} xp,yp,zp)是对应物体的中心坐标。
( b i n x ( p ) , b i n z ( p ) bin_{x}^{(p)},bin_z^{(p)} binx(p),binz(p))是沿着X,Z轴分配的ground- truth bin。
( r e s x ( p ) , r e s z ( p ) res_{x}^{(p)},res_z^{(p)} resx(p),resz(p)) 是在被分配的bin中做进一步定位微调的ground-truth残差。
C 是归一化的bin长度。 然后由预测的bin和真实的bin可以得到3D边界框的回归损失。

N p o s N_{pos} Npos是前景点的数量
b i n u ( p ) ˉ , r e s u ( p ) ˉ \bar{bin_{u}^{(p)}},\bar{res_{u}^{(p)}} binu(p)ˉ,resu(p)ˉ是前景点p被预测的bin分配和残差
b i n u ( p ) , r e s u ( p ) {bin_{u}^{(p)}},res_{u}^{(p)} binu(p),resu(p)是已经计算过的ground- truth对象
F c l s F_{cls} Fcls是分类的交叉熵损失 F r e g F_{reg} Freg是smooth L1 loss
从代码角度来解读

经过RPN(region proposal network)骨干网提取后的特征生成前景掩模预测分支(rpn_cls)和三维提案回归分支(rpn_reg)来完成相应任务。
- 3D场景中的目标通常是分离互不重叠的,所有三维目标的分割掩膜都可以通过3D边界框注释直接获得。另外前景掩膜预测过程中经过两个卷积层,输出(bs, n, 1)的mask,最后的1表示这个点属于前景点的概率,值越大,属于前景点的概率越高。加一个sigmoid限制到(0,1),然后用focal loss计算损失。
# classification branch
cls_layers = []
pre_channel = cfg.RPN.FP_MLPS[0][-1] # __C.RPN.FP_MLPS = [[128, 128], [256, 256], [512, 512], [512, 512]]
for k in range(0, cfg.RPN.CLS_FC.__len__()): # __C.RPN.CLS_FC = [128]
cls_layers.append(pt_utils.Conv1d(pre_channel, cfg.RPN.CLS_FC[k], bn=cfg.RPN.USE_BN))
pre_channel = cfg.RPN.CLS_FC[k]
cls_layers.append(pt_utils.Conv1d(pre_channel, 1, activation=None))
if cfg.RPN.DP_RATIO >= 0: # __C.RPN.DP_RATIO = 0.5
cls_layers.insert(1, nn.Dropout(cfg.RPN.DP_RATIO))
self.rpn_cls_layer = nn.Sequential(*cls_layers)
- 3D提案框回归分支使用前景点回归生成3D提案(注意,虽然没有从背景点中回归box,但是因为点云网络的感受野,这些背景点也为生成box提供了支持信息)。作者提出了基于bin的回归损失估计目标的三维边界框来预测3D边界框需要预测中心位置、目标尺寸与目标方向(x,y,z,h,w,l,θ)(3+3+1=7维),故最终预测生成的rpn_reg为(bs, n, 76)。这里用76维度的特征来表示这7个量。
# regression branch
per_loc_bin_num = int(cfg.RPN.LOC_SCOPE / cfg.RPN.LOC_BIN_SIZE) * 2 # (3/0.5) * 2 = 12
if cfg.RPN.LOC_XZ_FINE: # __C.RPN.LOC_XZ_FINE = False
reg_channel = per_loc_bin_num * 4 + cfg.RPN.NUM_HEAD_BIN * 2 + 3 # __C.RPN.NUM_HEAD_BIN = 12
else:
reg_channel = per_loc_bin_num * 2 + cfg.RPN.NUM_HEAD_BIN * 2 + 3
reg_channel += 1 # reg y
reg_layers = []
pre_channel = cfg.RPN.FP_MLPS[0][-1]
for k in range(0, cfg.RPN.REG_FC.__len__()): # __C.RPN.REG_FC = [128]
reg_layers.append(pt_utils.Conv1d(pre_channel, cfg.RPN.REG_FC[k], bn=cfg.RPN.USE_BN))
pre_channel = cfg.RPN.REG_FC[k]
reg_layers.append(pt_utils.Conv1d(pre_channel, reg_channel, activation=None))
if cfg.RPN.DP_RATIO >= 0:
reg_layers.insert(1, nn.Dropout(cfg.RPN.DP_RATIO))
self.rpn_reg_layer = nn.Sequential(*reg_layers)
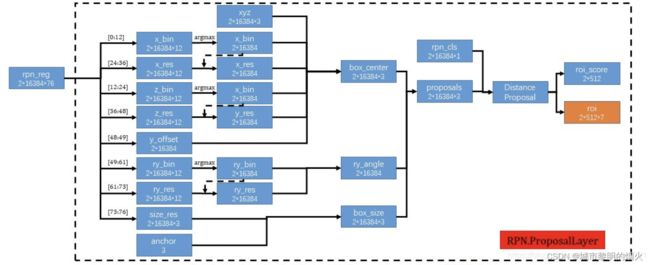
不是直接预测每个box中心点的坐标,而是预测每个前景点对于bounding box中心点的偏移,偏移了几个bin。但是这个bin是一个整数,还是无法精确定位,所以还需要中心点坐标在一个bin中的偏移量,把这个偏移量叫做res。
如图所示的76维向量预测框,前12维预测x方向上的bin,12-24预测z方向上的bin,24-36预测x方向的残差res,36-48预测z方向的残差,48-49预测y方向的距离,49-61预测角度的bin,61-73预测角度上的额残差,73-76对长宽高做出预测。基于bin的预测参数x,z,θ,我们首先选择具有最高预测信度的bin中心,并添加预测残差以获得重新定义的参数。其他参数则没有使用基于bin的预测方法。
强调:只有在预测中心点x,z轴坐标和bounding box的旋转角θ时,才用这种基于bin的思想。
这样的话,bounding box的7个关键量都得到了,但是就算每个前景点预测一个bounding box,也还是有很多个bounding box。所以下一步就要减少预测框的数量,作者利用基于鸟瞰图的IoU进行非最大值抑制(NMS)以生成少量高质量提案。具体代码在lib/rpn/proposal_layer.py中。
def distance_based_proposal(self, scores, proposals, order):
"""
propose rois in two area based on the distance
:param scores: (N)
:param proposals: (N, 7)
:param order: (N)
"""
nms_range_list = [0, 40.0, 80.0]
pre_tot_top_n = cfg[self.mode].RPN_PRE_NMS_TOP_N
pre_top_n_list = [0, int(pre_tot_top_n * 0.7), pre_tot_top_n - int(pre_tot_top_n * 0.7)]
post_tot_top_n = cfg[self.mode].RPN_POST_NMS_TOP_N
post_top_n_list = [0, int(post_tot_top_n * 0.7), post_tot_top_n - int(post_tot_top_n * 0.7)]
scores_single_list, proposals_single_list = [], []
# sort by score
scores_ordered = scores[order]
proposals_ordered = proposals[order]
dist = proposals_ordered[:, 2]
first_mask = (dist > nms_range_list[0]) & (dist <= nms_range_list[1])
for i in range(1, len(nms_range_list)):
# get proposal distance mask
dist_mask = ((dist > nms_range_list[i - 1]) & (dist <= nms_range_list[i]))
if dist_mask.sum() != 0:
# this area has points
# reduce by mask
cur_scores = scores_ordered[dist_mask]
cur_proposals = proposals_ordered[dist_mask]
# fetch pre nms top K
cur_scores = cur_scores[:pre_top_n_list[i]]
cur_proposals = cur_proposals[:pre_top_n_list[i]]
else:
assert i == 2, '%d' % i
# this area doesn't have any points, so use rois of first area
cur_scores = scores_ordered[first_mask]
cur_proposals = proposals_ordered[first_mask]
# fetch top K of first area
cur_scores = cur_scores[pre_top_n_list[i - 1]:][:pre_top_n_list[i]]
cur_proposals = cur_proposals[pre_top_n_list[i - 1]:][:pre_top_n_list[i]]
# oriented nms
boxes_bev = kitti_utils.boxes3d_to_bev_torch(cur_proposals)
if cfg.RPN.NMS_TYPE == 'rotate':
keep_idx = iou3d_utils.nms_gpu(boxes_bev, cur_scores, cfg[self.mode].RPN_NMS_THRESH)
elif cfg.RPN.NMS_TYPE == 'normal':
keep_idx = iou3d_utils.nms_normal_gpu(boxes_bev, cur_scores, cfg[self.mode].RPN_NMS_THRESH)
else:
raise NotImplementedError
# Fetch post nms top k
keep_idx = keep_idx[:post_top_n_list[i]]
scores_single_list.append(cur_scores[keep_idx])
proposals_single_list.append(cur_proposals[keep_idx])
scores_single = torch.cat(scores_single_list, dim=0)
proposals_single = torch.cat(proposals_single_list, dim=0)
return scores_single, proposals_single
解释下代码中的方法,
训练时在相机0~40m距离内的bounding box,先取得分类得分最高的6300个,然后计算bird view IOU,把IOU大于0.85的都删掉,到这里bounding box 又少了一点。然后再取得分最高的210个。在距离相机40~80m的范围内用同样的方法取90个。这样第一阶段结束的时候只剩下300个bounding box了。
300个bounding box也还是很多,于是有了第二阶段置信度打分和bounding box优化。
而在实际预测时,使用具有IOU阈值0.8的定向NMS,并且只保留前100个bounding box。
b. Canonical 3D Box Refinement
这一部分主要进行3D bounding box的优化,就是先提出大致的region proposal,再在第一阶段输出的proposal中进行搜索,得到准确的Bounding Box,这往往比one-stage更加精细,速度略逊。
Point Cloud Region Pooling
根据阶段1的3D点和所提取的特征进行池化,为了得到更精细的局部特征。具体步骤为:
-
对每一个获取的proposal(记做 b i b_{i} bi,表示为一个7维变量( x i , y i , z i , h i , w i , l i , θ i x_{i},y_{i},z_{i},h_{i},w_{i},l_{i},θ _{i} xi,yi,zi,hi,wi,li,θi)稍微放大,创造一个新的3D框 b i e b_{i}^{e} bie=( x i , y i , z i , h i + η , w i + η , l i + η , θ i x_{i},y_{i},z_{i},h_{i}+η,w_{i}+η,l_{i}+η,θ _{i} xi,yi,zi,hi+η,wi+η,li+η,θi)从环境中编码额外的信息,其中η是一个用来放大proposal的固定值。
-
判断点是否在扩大的提案内。对于每个点p = ( x ( p ) , y ( p ) , z ( p ) x^{(p)},y^{(p)},z^{(p)} x(p),y(p),z(p))执行一个内/外测试来判断这个点在不在被扩大的推荐框 b i e b_{i}^{e} bie中。如果在的话,这个点和他的特征就会被保留用来微调 b i b_{i} bi.
主要包括:
3D坐标( x i , y i , z i , h i , w i , l i , θ i x_{i},y_{i},z_{i},h_{i},w_{i},l_{i},θ _{i} xi,yi,zi,hi,wi,li,θi)
激光反射强度 r ( p ) r^{(p)} r(p)
阶段1的预测分割掩码 m ( p ) m^{(p)} m(p)
阶段1的C维学习点特征表示 f ( p ) f^{(p)} f(p)
--------------------这些结构正好是结构图中的引导线--------------------------------
Canonical Transformation
Canonical变换其实就是对每个proposal建立了一个单独的个体坐标系(如下图所示)。

这个坐标系的特点为:
1. 坐标系的原点为proposal的中点
2. X和Z轴与水平地面平行。且X轴为proposal朝向的位置
3. Y轴水平向下
规范后的中心点坐标为:
b i ~ \tilde{b_{i}} bi~ = (0, 0, 0, h i , w i , l i , 0 h_{i}, w_{i}, l_{i}, 0 hi,wi,li,0)
b i g t ~ \tilde{b_{i}^{gt}} bigt~ = ( x i g t − x i x_{i}^{gt}-x_{i} xigt−xi, y i g t − y i y_{i}^{gt}-y_{i} yigt−yi, z i g t − z i z_{i}^{gt}-z_{i} zigt−zi, h i g t , w i g t , l i g t , h_{i}^{gt}, w_{i}^{gt}, l_{i}^{gt}, higt,wigt,ligt,, θ i g t − θ i θ_{i}^{gt}-θ_{i} θigt−θi
作者仍采用bin-res的方法进行位置回归,只不过采用了更小的搜索范围S。
Merged Features
将坐标变化后的局部空间点再次卷积(改变通道数)和全局的语义特征结合优化框和置信度。另外尽管规范坐标后的点对局部空间信息鲁棒,但其不可避免的丢失了深度信息。比如,远处的目标(远离sensor)比近处的点密度小,为了补偿失去的深度信息,作者在p点的特征中包括了传感器的距离信息。
即 : d ( p ) = ( x ( p ) ) 2 + ( y ( p ) ) 2 + ( z ( p ) ) 2 d^{(p)} = \sqrt{(x^{(p)})^2 + (y^{(p)})^2 + (z^{(p)})^2} d(p)=(x(p))2+(y(p))2+(z(p))2.
Bin-based 3D box Refinement and Confidence Prediction
将所得的特征再喂入PointNet++获得接下来用于置信度分类和框优化的判别特征向量。
采用相似的基于bin回归的损失用于提案优化。一个groundtruth框被分配给提案框用来优化,如果他们的3D IoU大于0.55,因此作者假设预测角度和真实朝向的范围在 [ − π / 4 , π / 4 -\pi/4, \pi/4 −π/4,π/4] ,然后作者将这 [ π / 2 \pi/2 π/2] 划分为一个个的大小为 ω \omega ω 的bin,然后设置计算朝向的bin和res.
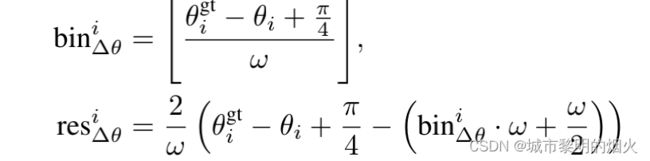
则整个二阶段子网络的全部loss为:

β \beta β是阶段1的3D proposal 几何 B p o s B_{pos} Bpos 存放着positive的回归proposals
p r o b i prob_{i} probi是估算 b i ~ \tilde{b_{i}} bi~的置信度 l a b e l i label_{i} labeli是对应的label
L b i n ( i ) ~ \tilde{L_{bin}^{(i)}} Lbin(i)~和 L r e s ( i ) ~ \tilde{L_{res}^{(i)}} Lres(i)~使用的是通过 b i g t ~ \tilde{b_{i}^{gt}} bigt~和 b i ~ \tilde{b_{i}} bi~计算的新对象
最后应用鸟瞰IoU阈值0.01的有方向的NMS去除重叠的边界框,并且生成被检测对象的三维边界框。
代码部分
阶段2的代码实现,具体的代码在lib/rpn/proposal_target_layer.py中。
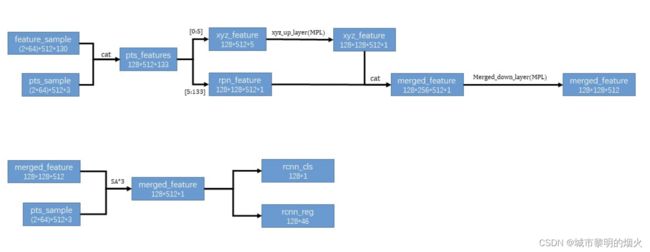
如图所示,最后得到的rcnn_cls 和 rcnn_reg的置信度结果。这个46也是基于bin的预测,跟之前的76是一个内涵,只是现在0-6表示x_bin。这部分的具体代码在lib/net/rcnn_net.py中。
总结
呼呼… 终于到最后啦,这篇论文难度迅速升级,原理花费时间还是可以看懂的,但是代码部分好复杂,真要完全理解估计得一个月起步了。后续如果真的用到,在回头仔细研读代码吧。另外本文如果有什么错误的地方欢迎大家指正。
参考
PointRCNN 学习笔记(文中图片来源)
【3D目标检测】PointRCNN深度解读
【代码阅读】PointRCNN网络可视化,代码详解
Point RCNN论文翻译及图解(里面有个图解建议大家看看)
【阅读笔记】pointrcnn