CSS反爬系列一(某知名租房平台)
注意
本文仅用于学习,如果冒犯请联系作者!!!!
问题场景
在浏览租房网站时候,凭借本能反应,打开了开发者工具,对页面元素进行检查看看能不能顺利采集。
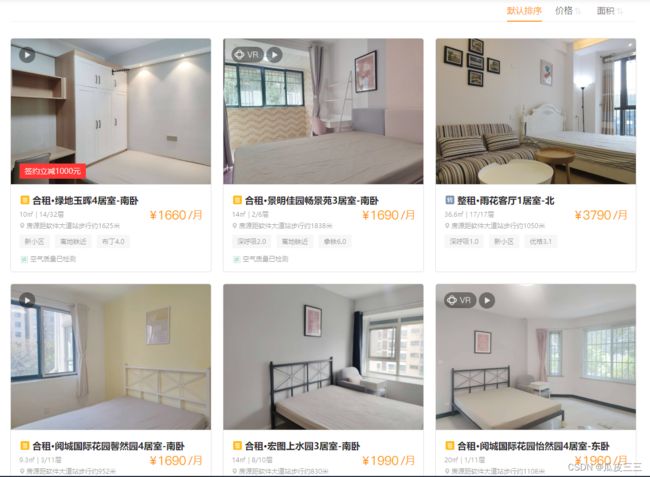
然后先看一下这些信息在什么地方,是通过xhr交互ajax发送,还是在页面源代码里,或者在其他地方呢??
我们打开,开发者工具检查元素,
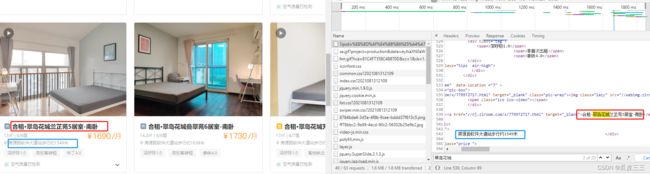
这里可以看到通过搜索关键字我们轻松找到数据来源在源代码里,这样就可以直接拿到页面源代码通过元素定位分别拿到对应数据了。
可是??
定睛一看这个价格好像有问题,
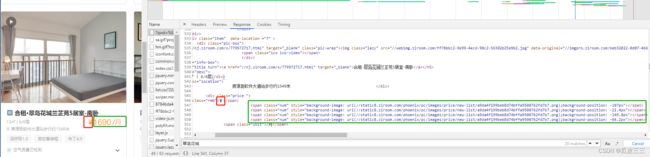
这里的价格通过背景图片,再用css定位这样我们就拿不到了,那该怎么解决呢???
思路整理
我们先看一下图片
复制里面的url,粘贴到浏览器导航栏

可以看到就是从0-9的数字只不过通过定位,让前端呈现不同的效果而已。
我们可以找一下规律,

这里展现的是:1 6 9 0 对应的是 -107 -21.4 -149.8 -64.2
这几位个定位都是21.4的倍数
21.4 * 5 = 107
21.4 * 1 = 21.4
21.4 * 7 = 149.8
21.4 * 3 = 64.2
也可以看出5 1 7 3 对应的索引位置就是 1 6 9 0
我们到页面试一试

这里我们按照规律我将1改为3,3是图片中的最后一位也就是第九位 21.4 * 9 = 192.6
但一定要是带负号的。
这样看来我们到问题要就解决了一大半了,接下来就是图片识别问题,我们怎么知道这个图片就是对应是什么呢,这就用到了ocr图像识别,还是推荐识别库,ddddocr

将图片下载下来用,第三方库识别可以看到完全正确,这种清晰数字的还是很好识别的。
接下来写代码实现功能。
代码展示
这需要80行代码就完成了,租房信息的采集
import re
import os
from parsel import Selector
import requests
import ddddocr
ocr = ddddocr.DdddOcr(show_ad=False)
url = "https://nj.ziroom.com/z/p{page}/?qwd={addr}"
headers = {
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
def get_page(page, addr):
response = requests.get(url.format(page=page, addr=addr), headers=headers)
selector = Selector(text=response.text)
item_list = selector.xpath('//div[@class="item"]').getall()
detail_list = []
for item in item_list:
item_selector = Selector(text=item)
item_dict = {}
# 条目名称
name = item_selector.xpath("//h5/a//text()").get()
# 楼层和面积
floor = item_selector.xpath('''//div[@class="desc"]/div[1]//text()''').get()
# 具体位置
location = item_selector.xpath('''//div[@class="location"]//text()''').get().replace("\t", "").replace("\n", "").strip()
# 标签
webtag_list = item_selector.xpath('''//div[@class="tag"]//span//text()''').getall()
# 金额
unit = item_selector.xpath('''//span[@class="unit"]//text()''').get()
rent_style = item_selector.xpath('''//span[@class="num"]//@style''').getall()
rent_list = []
for rent in rent_style:
css_url_image = re.search('image: url\\((.*?)\\);background-position: -(.*)', rent).group(1)
image_name = css_url_image.split("/")[-1]
if image_name not in os.listdir():
img_bytes = requests.get(url="http:"+css_url_image).content
with open(image_name, "wb") as f:
f.write(img_bytes)
else:
with open(image_name, 'rb') as f:
img_bytes = f.read()
# dddd识别
res = ocr.classification(img_bytes)
# 距离像素
postion = re.search('image: url\\((.*?)\\);background-position: -(.*)', rent).group(2).replace("px", "")
# 获取索引
index = int(float(postion) / 21.4)
# 获取每个位金额
num = res[index]
rent_list.append(num)
# 将金额拼接加上单位
rent = "".join(rent_list) + unit
item_dict["name"] = name
item_dict["floor"] = floor
item_dict["location"] = location
item_dict["webtag_list"] = webtag_list
item_dict["rent"] = rent
print(item_dict)
detail_list.append(item_dict)
if __name__ == '__main__':
for page in range(1, 7):
get_page(page, "软件大道")
结果展示:

这里我们只爬取列表页,
数据成功被我们爬取到,主要是css反爬分析,拿到数据后无论存储表格中还是数据库中都可以。