6--半监督学习
本周学习内容:
- 学习特征选择与稀疏学习部分内容
- 学习半监督学习部分内容
1 特征选择
在现实任务中属性过多则会造成维数灾难的问题,若能在所有特征中选取更重要的一部分特征来进行构建模型,则该问题将会减轻,另外去除不相关的特征往往也会降低学习任务的难度。
特征选择主要是由子集搜索和子集评价来完成。产生“候选子集”并对其进行评价,基于评价结果产生下一个候选子集,重复该操作直到无法找到更好的候选子集。子集搜索一般会基于贪心搜索减少计算,寻找局部最优而非全局,前向搜索:将每个特征看作一个候选子集,逐渐增加相关特征的策略;后向搜索:从完整的特征集合开始,逐渐减少无关特征的策略;双向搜索:结合前向和后向,每轮增加选定相关特征,同时减少无关特征。而子集评价常用信息增益评价子集,类似决策树。常见的特征选择方法大致可分为三类,即过滤式(filter)、包裹式(wrapper)和嵌入式(embedding)。
-
- Relief(Relevant Features)
该算法为过滤式特征选择方法,设计了一个“相关统计量”来度量特征的重要性,该统计量是一个向量,向量的每个分量是对其中一个初始特征的评价值,特征子集的重要性就是子集中每个特征所对应的相关统计量之和,因此这个“相关统计量”也可以视为是每个特征的“权值”。可以指定一个阈值τ,只需选择比τ大的相关统计量对应的特征值,也可以指定想要选择的特征个数 k kk,然后选择相关统计量分量最大的 k 个特征。假设训练集D,对每个训练样本Xi,计算与Xi同类别的最近邻Xi,nh,计算与Xi不同类别的最近邻Xi,nm,相关统计量对应于属性j的分量为:
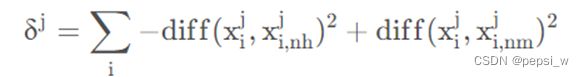
可以看出该值越大则说明该属性的分类能力越强,由于该计算公式得到的是单个样本对每个属性的评价值,将所有样本对同一个属性的评价值进行平均就得到了该属性的相关统计分量,分量值越大,分类能力就越强。
在西瓜数据集3.0上使用Relief算法来计算每个属性的统计分量,该算法中获得每个属性diff值的函数如下:
def getDiff(dataSet, i, j, mode=""):
"""
得到数据集dataSet中第i个数据的第j个属性值与其"猜中近邻"第j个属性值的距离。
对于离散型的属性j,若第i个样本的j属性值与其"猜中近邻"的j属性值相同则距离为0,反之为1。对于连续型的属性j,直接计算差的绝对值。
:param mode: "nh":猜中近邻。 "nm":猜错近邻
:param dataSet: 数据集
:param i: 第i个数据
:param j: 第j个属性
:return: 第i个数据的第j个属性值与其"猜中近邻"第j个属性值的距离
"""
exDataSet = None
if mode == 'nh':
exDataSet = dataSet[dataSet[:, -1] == dataSet[i][-1]]#选择所有的同类样本
if mode == 'nm':
exDataSet = dataSet[dataSet[:, -1] != dataSet[i][-1]]
dist = np.inf #初始值设为无穷大
if j < 6: # 前六个为离散型数据,后两个是连续型数据。
dist = 1 # 对于离散型数据,初始dist为1,当遇到相同的j属性值时,置零。
for k in range(len(exDataSet)):
if k == i: # 遇到第i个样本跳过。
continue
if exDataSet[k][j] == dataSet[i][j]:
dist = 0
break
else:
for k in range(len(exDataSet)):#在同类或者异类样本中进行便利 寻找最近的近邻
if k == i:
continue
sub = abs(float(exDataSet[k][j]) - float(dataSet[i][j]))
if sub < dist:
dist = sub
return dist运行结果如图2所示,可以看出在该数据集上,“脐部”的分类值最大,即该属性的分类能力最好,“色泽”的分类值最小,该属性分类能力最差。
 图2 Relief算法在西瓜数据集3.0上的运行结果
图2 Relief算法在西瓜数据集3.0上的运行结果
-
- LVW(Las Vegas Wrapper)
该算法是一种典型的包裹式特征选择方法,它在拉斯维加斯方法框架下使用随机策略来进行子集搜索,并以最终分类器的误差为特征子集评价准则。与前面的过滤式特征选择不考虑后续学习器不同,包裹式特征选择直接把最终要使用的学习器的性能作为特征子集的评价准则。该算法的流程如图1所示:

图1 LVW算法描述
-
- 嵌入式特征选择
嵌入式特征选择在学习器训练过程中自动地进行特征选择。嵌入式选择最常用的是L1 正则化和L2正则化。正则化项越大,模型越简单,系数越小,当正则化项增大到一定程度时,所有的特征系数都会趋于0,在这个过程中,会有一部分特征的系数先变成0。也就实现了特征选择过程。
逻辑回归、线性回归、决策树都可以当作正则化选择特征的基学习器,只有可以得到特征系数或者可以得到特征重要度的算法才可以作为嵌入式选择的基学习器。
- 稀疏矩阵、字典学习与压缩感知
学习一个字典,为普通稠密表示的样本找到合适的字典,将样本转化为合适的稀疏表示形式(用尽可能少的资源表示尽可能多的知识),从而使学习任务得以简化,模型复杂度降低,实质上是对于庞大数据集的一种降维表示。
字典学习的最简单形式为: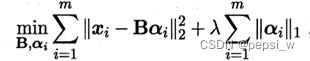
给定一个数据集,字典学习指的便是通过一个字典将原数据转化为稀疏表示,因此最终的目标就是求得字典矩阵B及稀疏表示α。
压缩感知与特征选择、稀疏表示不同的是,其关注的是如何利用信号本身所具有的稀疏性,从部分观测样本中恢复原信号。
- 半监督学习
在很多现实问题当中,一方面是由于人工标记样本的成本很高,导致有标签的数据十分稀少;另一方面,无标签的数据很容易被收集到,其数量往往是有标签样本的上百倍。半监督学习,就是要利用大量的无标签样本和少量带有标签的样本来训练分类器,解决有标签样本不足的难题,是一种介于监督学习和无监督学习之间的学习。
-
- 半监督SVM
监督学习中的SVM试图找到一个划分超平面,使得两侧支持向量之间的间隔最大,对于半监督学习,S3VM(Semi-Supervised Support Vector Machin e)则考虑超平面需穿过数据低密度的区域。TSVM的核心思想是:尝试为未标记样本找到合适的标记指派,使得超平面划分后的间隔最大化。
TSVM采用局部搜索的策略来进行迭代求解,即首先使用有标记样本集训练出一个初始SVM,接着使用该学习器对未标记样本进行打标,这样所有样本都有了标记,并基于这些有标记的样本重新训练SVM,之后再寻找易出错样本不断调整。
基于鸢尾花数据集分别使用SVM和TSVM算法对其进行训练,得到的决策平面如图2所示。
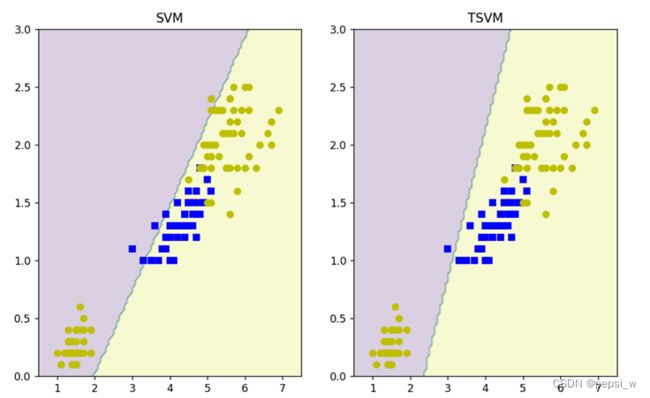
图2 SVM和TSVM分别得到的决策面
其中测试集:有标记样本:无标记样本的比例是3:6:1,且SVM算法只使用有标记样本进行训练。两个算法在测试集上运行的准确率如图3所示,可以看出当有标记样本较少时,半监督学习算法的准确率是要高于普通SVM的。

图3 SVM和TSVM在同一测试集上的准确率
-
- 图半监督学习
将数据集映射为一个图,样本点为图的顶点,将有标签和无标签的数据点进行连接,边的权重Wij表示两个样本点之间的相似度。边的权重随欧式距离的增加而降低,权重方程为: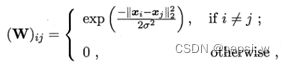 其中σ为带宽参数用来控制权重衰减的速度。该类算法在处理大规模数据时性能欠佳,并且难以直接对新样本进行分类,一般是通过将新样本加入原数据集再重新进行一次标记传播,或将有标记的样本和一句应该标记传播的无标记样本作为训练集,训练一个学习器来对新样本进行传播。
其中σ为带宽参数用来控制权重衰减的速度。该类算法在处理大规模数据时性能欠佳,并且难以直接对新样本进行分类,一般是通过将新样本加入原数据集再重新进行一次标记传播,或将有标记的样本和一句应该标记传播的无标记样本作为训练集,训练一个学习器来对新样本进行传播。
-
- 协调训练算法
协同训练(co-training)算法是多视图(multi-view)学习的代表。即每个属性集就构成了一个视图,协同训练认为单凭一个视图,训练器就能取得一个很好的性能。
首先分别在每个视图上利用有标记样本训练一个分类器,然后,每个分类器从未标记样本中挑选若干标记置信度(即对样本赋予正确标记的置信度)高的样本进行标记,并把这些“伪标记”样本(即其标记是由学习器给出的)加入另一个分类器的训练集中,以便对方利用这些新增的有标记样本进行更新。该过程不断迭代进行下去,直到两个分类器都不再发生变化,或达到预先设定的学习轮数为止。
-
- 半监督聚类
聚类任务中获得的监督信息有两种类型,一种是得到样本间“必练”和“勿连”的大致关系,另一种是拥有少量的标记样本。
- 约束k均值算法
该算法是k均值算法的扩展,在聚类过程中确保给定的“必连”和“勿连”中的约束得到满足。实现该算法的主要函数如下所示:
def sort_data(data,sample,M,C):
'''对数据进行分类
:param data: 所有样本数据
:param sample: 均值向量
:param M :约束条件集合
:param C :约束条件集合
:return: 当前簇的划分
'''
sorted_data = {}
for i in range(len(data)):
dist = {} # 用来装每个数据离每个均值向量的距离 类别:距离
for k in range(len(sample)):#分为3类 就是要计算到这三类的距离
dist[k] = distance(data[i],sample[k])
dist = sorted(dist.items(),key=lambda x:x[1])#按value 距离进行排序
if i not in M|C:#如果该元素不在约束条件里 直接放在离最近的簇
sorted_data.setdefault(dist[0][0], []).append(i)
else:
if is_mergeed(dist[0][0],i,sorted_data):#传入参数 某一簇和某个数据 判断是否和约束条件冲突
sorted_data.setdefault(dist[0][0],[]).append(i)
elif is_mergeed(dist[1][0],i,sorted_data):#最近的要是不满足约束 就放在第二近的类别
sorted_data.setdefault(dist[1][0],[]).append(i)
else:#都不满足 就放在第三近的类别
sorted_data.setdefault(dist[2][0],[]).append(i)
print("sorted_data",sorted_data)
return sorted_data该算法在西瓜数据集4.0上运行结果如图4所示:
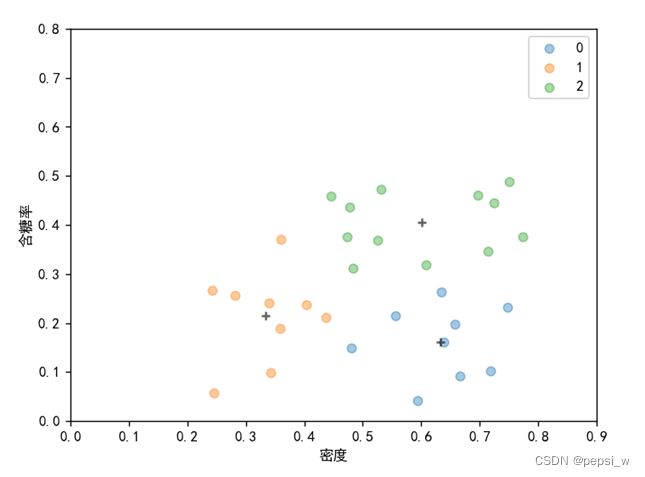
图4 约束k均值算法(k=3)最终聚类结果
- 约束种子k均值算法
在给定的样本集中存在少量的标记样本,该算法直接用这些标记样本来初始化k均值算法的k个聚类中心,并在迭代过程中不改变这些样本的隶属关系。该算法在西瓜数据集4.0上运行结果如图5所示:
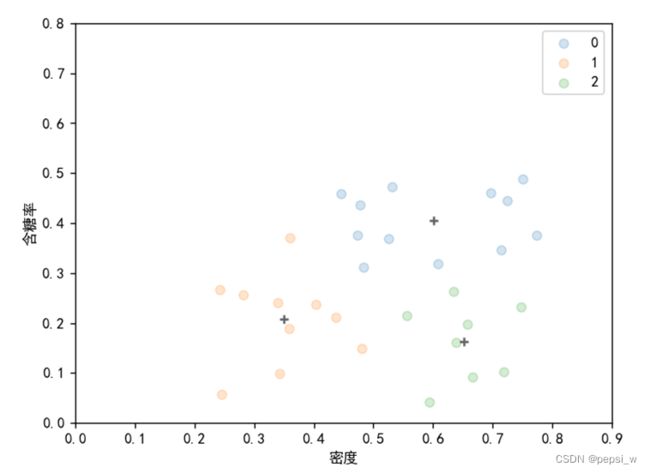
图5 约束种子k均值算法(k=3)最终聚类结果
下周计划:
- 学习概率图模型
- 学习规则学习部分
附:
约束k均值算法代码
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
M1 = [(3,24),(24,3),(11,19),(19,11),(13,16),(16,13)]
C1 = [(1,20),(20,1),(12,22),(22,12),(18,22),(22,18)]
M = []
for i in M1:
for j in i:
M.append(j)
M = set(M)
C = []
for i in C1:
for j in i:
C.append(j)
C = set(C)
def dataset():
data = [
[0.697, 0.460],[0.774, 0.376],[0.634, 0.264],[0.608, 0.318],[0.556, 0.215],[0.403, 0.237],
[0.481, 0.149],[0.437, 0.211],[0.666, 0.091],[0.243, 0.267],[0.245, 0.057],[0.343, 0.099],
[0.639, 0.161],[0.657, 0.198],[0.360, 0.370],[0.593, 0.042],[0.719, 0.103],[0.359, 0.188],
[0.339, 0.241],[0.282, 0.257],[0.748, 0.232],[0.714, 0.346],[0.483, 0.312],[0.478, 0.437],
[0.525, 0.369],[0.751, 0.489],[0.532, 0.472],[0.473, 0.376],[0.725, 0.445],[0.446, 0.459]
]
data = np.array(data)
lables = ['密度','含糖率']
return data,lables
def distance(data1,data2):
'''
计算两个样本点之间的距离 使用欧氏距离
:param data1: 样本点1
:param data2: 样本点2
:return: 距离
'''
sum = 0
for x in range(len(data1)):
sum += pow(abs(data1[x]-data2[x]),2)
dist = pow(sum,1/2)
return dist
def is_mergeed(k,num,sorted_data):
#print("yyyyyyyyyyy")
#print(sorted_data[k])
if len(sorted_data[k]) == 0:#若该簇还没有一个元素 则直接返回true
print("该簇还没有一个元素")
return True
else:
for data in sorted_data[k]:
print((num,data))
if((num,data) in M1):
return True
elif ((num,data) in C1):
return False
return True
def sort_data(data,sample,M,C):
'''对数据进行分类
:param data: 所有样本数据
:param sample: 均值向量
:param M :约束条件集合
:param C :约束条件集合
:return: 当前簇的划分
'''
sorted_data = {}
for i in range(len(data)):
dist = {} # 用来装每个数据离每个均值向量的距离 类别:距离
for k in range(len(sample)):#分为3类 就是要计算到这三类的距离
dist[k] = distance(data[i],sample[k])
dist = sorted(dist.items(),key=lambda x:x[1])#按value 距离进行排序
if i not in M|C:#如果该元素不在约束条件里 直接放在离最近的簇
sorted_data.setdefault(dist[0][0], []).append(i)
else:
if is_mergeed(dist[0][0],i,sorted_data):#传入参数 某一簇和某个数据 判断是否和约束条件冲突
sorted_data.setdefault(dist[0][0],[]).append(i)
elif is_mergeed(dist[1][0],i,sorted_data):#最近的要是不满足约束 就放在第二近的类别
sorted_data.setdefault(dist[1][0],[]).append(i)
else:#都不满足 就放在第三近的类别
sorted_data.setdefault(dist[2][0],[]).append(i)
print("sorted_data",sorted_data)
return sorted_data
def updata_mean(group,old_mean):
'''
用来更新均值向量
:param group: 每一簇的所有数据
:param old_mean: 原来的均值
:return: 新的均值
'''
new_mean = []
for i in range(len(old_mean)):#遍历每一维
sum = 0
for data in group[:,i]:
#print("group[i]:",group[i])
sum += data
new_mean.append(sum/len(group))
return np.array(new_mean)
def plot(sorted_data,data,sample,axes=[0,0.9,0,0.8]):
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# matplotlib画图中中文显示会有问题,需要这两行设置默认字体
custom_cmap2 = ListedColormap(['#7d7d58', '#4c4c7f', '#507d50'])
for i in range(len(sorted_data)):
#print(np.array(data[i]))
plt.scatter(np.array(data[sorted_data[i]][:,0]),np.array(data[sorted_data[i]][:,1]),cmap = custom_cmap2, alpha=0.4, label=i)
plt.scatter(sample[i][0], sample[i][1], marker='+', color='black', alpha=0.6)
plt.axis(axes)
plt.legend()
plt.xlabel('密度')
plt.ylabel('含糖率')
plt.show()
if __name__=='__main__':
data, lables = dataset()
sample = {}
#list = random.sample(range(0,len(data)),3)#随机选择三个整数 用来当作初始均值向量 这里为了看是否正确 复习书上的例子
list = [5,11,26]
for i in range(3):
sample[i] = data[list[i]]#将随机选择的数据 用来当作初始均值向量
print("sample",sample)
flag = 0
while flag != 3 :#直到所有均值向量不再更新时 退出循环
print("这是循环!")
flag = 0
sorted_data = sort_data(data,sample,M,C)#先对当前所有数据根据向量均值进行分簇
plot(sorted_data,data,sample)#每一轮划分好后 可视化展示
for i in range(len(sample)):#一类一类的进行更新均值
new_mean = updata_mean(np.array(data[sorted_data[i]]),sample[i])
if ((new_mean==sample[i]).all()):#当前均值保持不变 标志位+1
flag += 1
else:#当前均值更新为新的均值
sample[i] = new_mean
print(sorted_data)约束种子k均值算法
import random
import math
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
def dataset():
data = [
[0.697, 0.460],[0.774, 0.376],[0.634, 0.264],[0.608, 0.318],[0.556, 0.215],[0.403, 0.237],
[0.481, 0.149],[0.437, 0.211],[0.666, 0.091],[0.243, 0.267],[0.245, 0.057],[0.343, 0.099],
[0.639, 0.161],[0.657, 0.198],[0.360, 0.370],[0.593, 0.042],[0.719, 0.103],[0.359, 0.188],
[0.339, 0.241],[0.282, 0.257],[0.748, 0.232],[0.714, 0.346],[0.483, 0.312],[0.478, 0.437],
[0.525, 0.369],[0.751, 0.489],[0.532, 0.472],[0.473, 0.376],[0.725, 0.445],[0.446, 0.459]
]
data = np.array(data)
lables = ['密度','含糖率']
return data,lables
def distance(data1,data2):
'''
计算两个样本点之间的距离 使用欧氏距离
:param data1: 样本点1
:param data2: 样本点2
:return: 距离
'''
sum = 0
for x in range(len(data1)):
sum += pow(abs(data1[x]-data2[x]),2)
dist = pow(sum,1/2)
return dist
def sort_data(data,sample,S):
'''
对数据进行分类
:param data: 所有样本数据
:param sample: 均值向量
:param S: 约束种子
:return: 当前簇的划分
'''
sorted_data = {}
for j in range(len(S)):#用给的标记数据来初始化簇
for i in range(len(S[j])):
#print("111111111111111111111:",S[j])
sorted_data.setdefault(j,[]).append(S[j][i])
print("初始化后的sorted_data:",sorted_data)
sorted_data_values = []
#print("values : ",list(sorted_data.values()))
for a in list(sorted_data.values()):#得到已经分好簇的那些元素
for b in a:
sorted_data_values.append(b)
print("values:",sorted_data_values)
for i in range(len(data)):
if i not in sorted_data_values:#防止对初始化后分好簇再次进行划分 这里做一个判断
min = float("inf")#最小值设为无穷大
for k in range(len(sample)):#分为3类 就是要计算到这三类的距离
dist1 = distance(data[i],sample[k])
if dist1 < min:
min = dist1
min_k = k
sorted_data.setdefault(min_k,[]).append(i)
print("sorted_data",sorted_data)
return sorted_data
def updata_mean(group,old_mean):
'''
用来更新均值向量
:param group: 每一簇的所有数据
:param old_mean: 原来的均值
:return: 新的均值
'''
new_mean = []
for i in range(len(old_mean)):#遍历每一维
sum = 0
for data in group[:,i]:
#print("group[i]:",group[i])
sum += data
new_mean.append(sum/len(group))
return np.array(new_mean)
def plot(sorted_data,data,sample,axes=[0,0.9,0,0.8]):
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# matplotlib画图中中文显示会有问题,需要这两行设置默认字体
#custom_cmap2 = ListedColormap(['#7d7d58', '#4c4c7f', '#507d50']) cmap = custom_cmap2
for i in range(len(sorted_data)):
#print(np.array(data[i]))
plt.scatter(np.array(data[sorted_data[i]][:,0]),np.array(data[sorted_data[i]][:,1]), alpha=0.2, label=i)
plt.scatter(sample[i][0], sample[i][1], marker='+', color='black', alpha=0.6)
plt.axis(axes)
plt.legend()
plt.xlabel('密度')
plt.ylabel('含糖率')
plt.show()
if __name__=='__main__':
data, lables = dataset()
sample = {}
#list = random.sample(range(0,len(data)),3)#随机选择三个整数 用来当作初始均值向量 这里为了看是否正确 复习书上的例子
S = np.array([[3,24],[11,19],[13,16]])
for i in range(len(S)):
sample[i] = data[S[i]].mean(axis=0)
print("sample",sample)
flag = 0
while flag != 3 :#直到所有均值向量不再更新时 退出循环
print("这是循环!")
flag = 0
sorted_data = sort_data(data,sample,S)#先对当前所有数据根据向量均值进行分簇
plot(sorted_data,data,sample)#每一轮划分好后 可视化展示
for i in range(len(sample)):#一类一类的进行更新均值
new_mean = updata_mean(np.array(data[sorted_data[i]]),sample[i])
if ((new_mean==sample[i]).all()):#当前均值保持不变 标志位+1
flag += 1
else:#当前均值更新为新的均值
sample[i] = new_mean
print(sorted_data)