Alpha-Beta 剪枝搜索实现黑白棋AI
完整代码可以在 我的AI学习笔记 - github 中获取
游戏规则
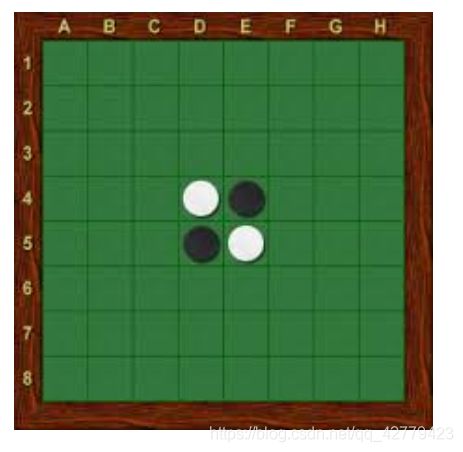
棋局开始时黑棋位于 E4 和 D5 ,白棋位于 D4 和 E5,如图所示。
黑方先行,双方交替下棋。
一步合法的棋步包括:
在一个空格处落下一个棋子,并且翻转对手一个或多个棋子;
新落下的棋子必须落在可夹住对方棋子的位置上,对方被夹住的所有棋子都要翻转过来,
可以是横着夹,竖着夹,或是斜着夹。夹住的位置上必须全部是对手的棋子,不能有空格;
一步棋可以在数个(横向,纵向,对角线)方向上翻棋,任何被夹住的棋子都必须被翻转过来,棋手无权选择不去翻某个棋子。
如果一方没有合法棋步,也就是说不管他下到哪里,都不能至少翻转对手的一个棋子,那他这一轮只能弃权,而由他的对手继续落子直到他有合法棋步可下。
如果一方至少有一步合法棋步可下,他就必须落子,不得弃权。
棋局持续下去,直到棋盘填满或者双方都无合法棋步可下。
如果某一方落子时间超过 1 分钟 或者 连续落子 3 次不合法,则判该方失败。
使用Alpha-Beta 剪枝搜索实现
class AIPlayer:
"""
AI 玩家
"""
weight = [
[70, -20, 20, 20, 20, 20, -15, 70],
[-20,-30,5,5,5,5,-30,-15],
[20,5,1,1,1,1,5,20],
[20,5,1,1,1,1,5,20],
[20,5,1,1,1,1,5,20],
[20,5,1,1,1,1,5,20],
[-20,-30,5,5,5,5,-30,-15],
[70,-15,20,20,20,20,-15,70]
]
deepth = 0
maxdeepth = 6
emptylistFlag = 10000000
def __init__(self, color):
"""
玩家初始化
:param color: 下棋方,'X' - 黑棋,'O' - 白棋
"""
self.color = color
def calculate(self,board,color):
if color == 'X':
colorNext ='O'
else:
colorNext ='X'
count = 0
for i in range(8):
for j in range(8):
if color == board[i][j]:
count += self.weight[i][j]
elif colorNext == board[i][j]:
count -= self.weight[i][j]
return count
def alphaBeta(self,board,color,a,b):
# 递归终止
if self.deepth > self.maxdeepth:
return None, self.calculate(board,self.color)
if color == 'X':
colorNext ='O'
else:
colorNext ='X'
action_list = list(board.get_legal_actions(color))
if len(action_list) == 0:
if len(list(board.get_legal_actions(colorNext))) == 0:
return None,self.calculate(board,self.color)
return self.alphaBeta(board,colorNext,a,b)
max = -9999999
min = 9999999
action = None
for p in action_list:
flipped_pos = board._move(p,color)
self.deepth += 1
p1, current = self.alphaBeta(board,colorNext,a,b)
self.deepth -= 1
board.backpropagation(p,flipped_pos,color)
# print(p,current)
# alpha-beta 剪枝
if color == self.color:
if current > a:
if current > b:
return p,current
a = current
if current > max:
max = current
action = p
else:
if current < b:
if current < a:
return p,current
b = current
if current < min:
min = current
action = p
# print(color,action,max,min)
if color == self.color:
return action,max
else:
return action,min
def get_move(self, board):
"""
根据当前棋盘状态获取最佳落子位置
:param board: 棋盘
:return: action 最佳落子位置, e.g. 'A1'
"""
if self.color == 'X':
player_name = '黑棋'
else:
player_name = '白棋'
print("请等一会,对方 {}-{} 正在思考中...".format(player_name, self.color))
# -----------------请实现你的算法代码--------------------------------------
action_list = list(board.get_legal_actions(self.color))
# action, weight = self.maxMin(board,self.color)
action, weight = self.alphaBeta(board,self.color,-9999999,9999999)
if len(action_list) == 0:
return None
print(action_list)
print(action)
return action
# ------------------------------------------------------------------------