python:机器学习(四)(特征工程及模型聚合)
文章所用数据:https://download.csdn.net/download/m0_64596200/86513715
特征工程:
- 最大限度地从原始数据中提取特征以供算法和模型使用
- 数据和特征决定了机器学习的上限,模型和算法只是逼近这个上限
特征工程方法:
数据预处理
- 缺失值处理(均值,众数,中位数)
- 字符编码数据处理(独热编码)
- 归一化处理
1、空值处理(均值、众数、中位数)
对得到的数据进行查看:
data_df = pd.read_csv("data/train.csv")
print(data_df.head(),data_df.shape)
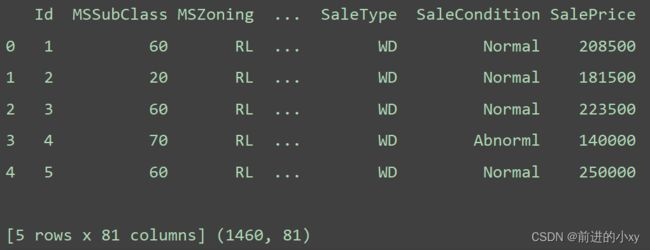
结果看出共有1460行,81列
查看数据存在的空值
print(data_df.isnull().sum())
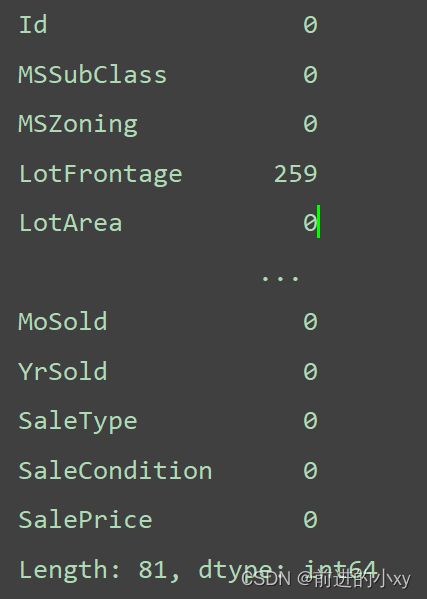
LotFrontage列存在259行,数据间。。。省略了多条数据
显示数据所有行
pd.set_option("display.max_rows", None)
# 显示所有列
pd.set_option("display.max_columns", None)
发现其他列也具有空值:
LotFrontage 259
Alley 1369
BsmtQual 37
BsmtCond 37
BsmtExposure 38
BsmtFinType1 37
BsmtFinType2 38
FireplaceQu 690
GarageType 81
GarageYrBlt 81
GarageFinish 81
GarageQual 81
GarageCond 81
PoolQC 1453
Fence 1179
MiscFeature 1406
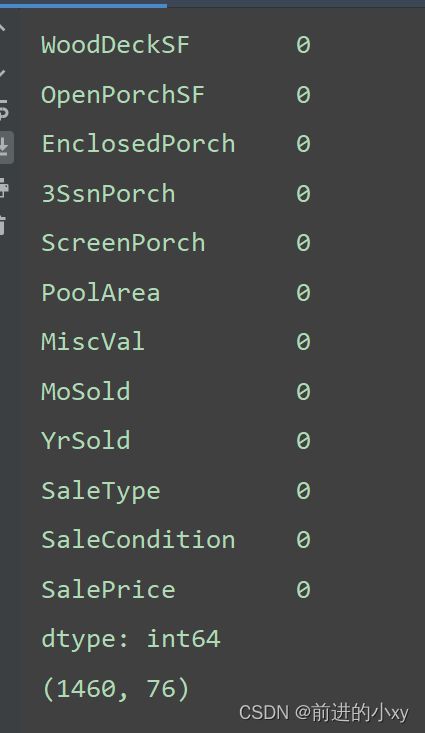
当数据空值超过了1/3行都是空值删除列(共1460行)
data_df.drop(columns=['Alley', 'FireplaceQu', 'PoolQC', 'Fence', 'MiscFeature'], axis=1, inplace=True)
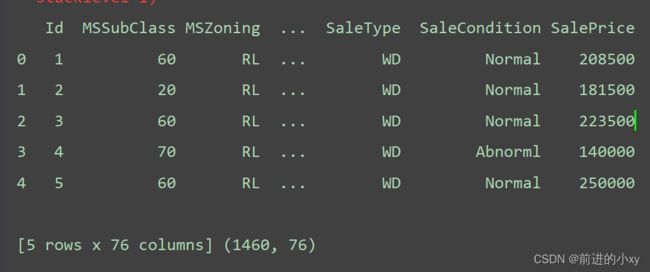
这里只剩76列
均值填充(数据是数字)
data_df['LotFrontage'].fillna(data_df['LotFrontage'].mean(), inplace=True)
中位数填充(int或float)
data_df['GarageYrBlt'].fillna(data_df['GarageYrBlt'].median(), inplace=True)
独热编码(字符)
# 这一列有空的放入list容器中
mis_col_list = data_df.isnull().any()[data_df.isnull().any().values == True].index.tolist()
得到哪些列为空
![]()
获取它们的数据也放入容器中
mis_list = []
for i in mis_col_list:
# 数据要进行拍平
mis_list.append(data_df[i].values.reshape(-1, 1))
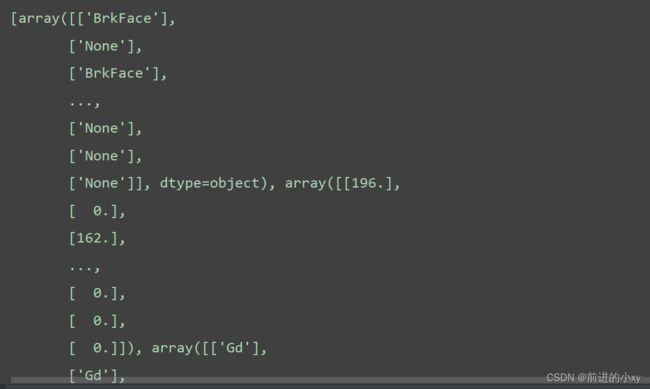
字符可以进行众数填充,并替换至原来的数据中
for i in range(len(mis_list)):
im_most = SimpleImputer(strategy="most_frequent")
# 众数填充
im_most.fit_transform(mis_list[i])
# 替换
data_df.loc[:, mis_col_list[i]] = im_most
对字符集进行独热编码
找到字符的列
ob_feature = data_df.select_dtypes(include=['object']).columns.tolist()
![]()
此处共39列
提取这些列进行独热编码
提取:
ob_data = data_df.loc[:, ob_feature]
独热编码:
OneHot = OneHotEncoder(categories='auto')
res = OneHot.fit_transform(ob_data).toarray()

字符串变数字
将这些数据重新并入原数据中
OneHotnames = OneHot.get_feature_names().tolist()
onehot_df = pd.DataFrame(res, columns=OneHotnames) #39列多出194列
# 独热编码结束
# 删除原来字符了列,并入编码后的列
data_df.drop(columns=ob_feature, inplace=True)
data_df = pd.concat([onehot_df, data_df], axis=1) # 行合并
提取主要特征方法
1、方差过滤
var_index = VarianceThreshold(threshold=0.1)
data = var_index.fit_transform(data_df)
获取留下的列索引
index_ = var_index.get_support(True).tolist()
data_df = data_df.iloc[:, index_]
2、相关系数分析 前面特征列与label的相关系数
收集相关系数大于0.5的列名
fname_list = []
for i in range(0, len(feature_name)-1):
if abs(pearsonr(data_df[feature_name[i]], data_df[feature_name[-1]])[0]) > 0.5:
fname_list.append(feature_name[i])
![]()
共12列
3、热力图----每一列之间的关系
plt.figure(figsize=(12,12))
sns.set(font_scale=1.5)
corr = np.corrcoef(data_df[fname_list].values.T)
sns.heatmap(corr,cbar=False,annot=True,square=True,fmt='0.2f',yticklabels=fname_list,xticklabels=fname_list)
plt.show()
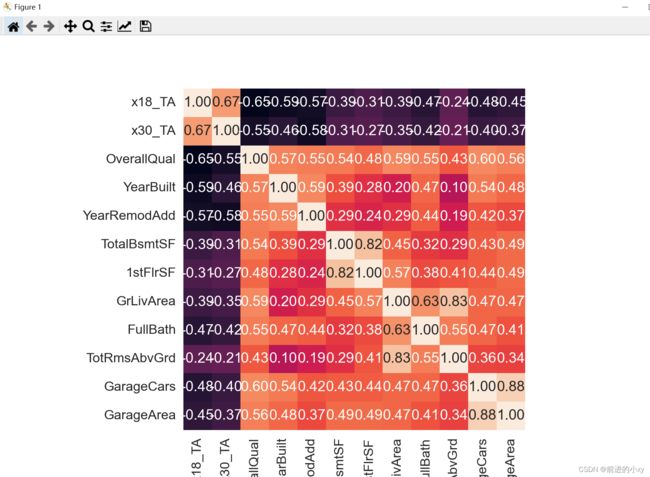
删除相关度超过80%的,相似度较高
fname_list.append('SalePrice')
data_df = data_df[fname_list]
data_df.drop(columns=['GarageArea', 'TotRmsAbvGrd', '1stFlrSF'], inplace=True)
数据分割 获取前9列
feature_data = data_df.iloc[:, :-1].values
label_data = np.ravel(data_df.iloc[:, -1:].values) # 拍平
x_train, x_test, y_train, y_test = train_test_split(feature_data,label_data,test_size=0.3,random_state=6)
数据的归一化处理:有写数据大,有些数据小,模型训练时w,b算不准确
std = StandardScaler()
x_std_train = std.fit_transform(x_train)
x_std_test = std.fit_transform(x_test)
之后再做:
- 选择算法
- 超参调试
- 模型训练
- 模型评分
后面步骤可间之前的文章
所有代码:
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.feature_selection import VarianceThreshold
from scipy.stats import pearsonr
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn.model_selection import train_test_split
# 显示数据所有行
pd.set_option("display.max_columns", None)
pd.set_option("display.max_rows", None)
# 加载数据
data_df = pd.read_csv("data/train.csv")
# print(data_df.head(),data_df.shape)
# 删除空值超过1/3的列
data_df.drop(columns=['Alley', 'FireplaceQu', 'PoolQC', 'Fence', 'MiscFeature'], axis=1, inplace=True)
# print(data_df.head(),data_df.shape)
# 空值查看
# print(data_df.isnull().sum())
# 剩余列填充 均值填充
data_df['LotFrontage'].fillna(data_df['LotFrontage'].mean(), inplace=True)
# 中位数填充
data_df['GarageYrBlt'].fillna(data_df['GarageYrBlt'].median(), inplace=True)
# 缺失值列 集中处理----独热编码 值--字符
mis_col_list = data_df.isnull().any()[data_df.isnull().any().values == True].index.tolist()
# print(mis_col_list)
# 将它们的数据也放入
mis_list = []
for i in mis_col_list:
mis_list.append(data_df[i].values.reshape(-1, 1))
# print(mis_list)
for i in range(len(mis_list)):
im_most = SimpleImputer(strategy="most_frequent")
# 众数填充
im_most.fit_transform(mis_list[i])
# 替换
data_df.loc[:, mis_col_list[i]] = im_most
# print(data_df.isnull().sum())
# print(data_df.shape)
# 找到字符的列
ob_feature = data_df.select_dtypes(include=['object']).columns.tolist()
# print(ob_feature,len(ob_feature))
# 得到字符列进行独热编码
ob_data = data_df.loc[:, ob_feature]
# print(ob_data)
# 独热编码
OneHot = OneHotEncoder(categories='auto')
res = OneHot.fit_transform(ob_data).toarray()
# print(res)
# print(res.shape)
# 并入原数据中
OneHotnames = OneHot.get_feature_names().tolist()
# print(OneHotnames,len(OneHotnames))
onehot_df = pd.DataFrame(res, columns=OneHotnames) #39列多出194列
# 独热编码结束
# 删除原来字符了列,并入编码后的列
data_df.drop(columns=ob_feature, inplace=True)
data_df = pd.concat([onehot_df, data_df], axis=1) # 行合并
# print(data_df.shape)
# 方差过滤
var_index = VarianceThreshold(threshold=0.1)
data = var_index.fit_transform(data_df)
# print(data, len(data))
# 获取留下的列的索引
index_ = var_index.get_support(True).tolist()
data_df = data_df.iloc[:, index_]
# print(data.shape)
# 获得剩下的列
feature_name = data_df.columns.tolist()
# print(feature_name, len(feature_name))
fname_list = []
# 相关系数分析 前面特征列与label的相关系数
for i in range(0, len(feature_name)-1):
if abs(pearsonr(data_df[feature_name[i]], data_df[feature_name[-1]])[0]) > 0.5:
fname_list.append(feature_name[i])
print(fname_list, len(fname_list))
# 删除超80%的
fname_list.append('SalePrice')
data_df = data_df[fname_list]
data_df.drop(columns=['GarageArea', 'TotRmsAbvGrd', '1stFlrSF'], inplace=True)
# print(data_df.shape)
# 数据分割
feature_data = data_df.iloc[:, :-1].values
label_data = np.ravel(data_df.iloc[:, -1:].values) # 拍平
x_train, x_test, y_train, y_test = train_test_split(feature_data,label_data,test_size=0.3,random_state=6)
# 数据归一化处理
std = StandardScaler()
x_std_train = std.fit_transform(x_train)
x_std_test = std.fit_transform(x_test)
# 绘制热力图
# plt.figure(figsize=(12,12))
# sns.set(font_scale=1.5)
# corr = np.corrcoef(data_df[fname_list].values.T)
# sns.heatmap(corr,cbar=False,annot=True,square=True,fmt='0.2f',yticklabels=fname_list,xticklabels=fname_list)
# plt.show()