进化计算(八)——MOEA/D算法详解Ⅱ
MOEA/D论文阅读笔记Ⅱ
- MOEA/D vs. MOGLS(Neighbor&TEP)
-
- MOGLS
- MOGLS vs. MOEA/D(Complexity)
- 多目标0-1背包问题—MOKP
- 两种算法的MOKP具体实施
-
- 修复方法
- MOGLS的实施方案
- MOEA/D的实施方案
- 参数设置
- 实验结果
-
- 评价指标
- 结果
- MOEA/D vs. NSGA Ⅱ
-
- 利于实验对比的MOEA/D变体
- NSGA-Ⅱ vs. MOEA/D(Complexity)
- 参数设置
- 实验结果
- 对MOEA/D算法的一些改进
-
- 采用PBI分解方法的MOEA/D算法
- 采用目标函数归一化的MOEA/D算法
- Scability, Sensitivity, and Small Population in MOEA/D
-
- 对T的敏感性分析
- 小种群的MOEA/D算法
- 扩充性
- Conclusion
- 参考文献及链接
写在前边:本文依然是自己的理解笔记,仅用作本人学习记录。写博客的时候主要参考了原文,具体链接在文末。
MOEA/D vs. MOGLS(Neighbor&TEP)
选取MOGLS用来对比的原因是MOGLS采用了分解策略,且它在大量多目标0/1背包问题的有名算法中表现出了较好的性能。
MOGLS
MOGLS算法被Ishibuchi和Murata提出,后又被Jaszkiewicz改进。其主要思想是将MOP转换为同时优化所有加权切比雪夫函数或者所有加权和函数。下边简要描述Jaszkiewicz版本的MOGLS算法。
符号及参数定义:
在每一次迭代,MOGLS算法包括:
- 一组当前解CS和这些解的适应度值 F F F-values;
- 一个外部种群EP,用于存储非支配解;
- 使用切比雪夫方法的MOGLS算法还应包括 z = ( z 1 , . . . . , z m ) T z=(z_1,....,z_m)^T z=(z1,....,zm)T,其中 z i z_i zi是目标函数 f i f_i fi迄今为止找到的最大值;
MOGLS需要两个控制参数 K K K和 S S S。其中 K K K是临时精英种群的大小, S S S是 C S CS CS的初始大小。 m m m是目标函数个数。
输入输出
INPUT:MOP;停止迭代的条件;K;S。
OUTPUT:EP。
初始化
- 随机生成 S S S个初始解。 C S = x 1 , . . . , x S CS={x^1,...,x^S} CS=x1,...,xS;
- 初始化 z ⃗ = ( z 1 , . . . , z m ) T \vec{z}=(z_1,...,z_m)^T z=(z1,...,zm)T;
- 初始化 E P EP EP为 C S CS CS所有非支配解 F F F-values的集合。
迭代循环
- 基因重组:均匀随机生成一个权重向量 λ \lambda λ。
- 针对使用权重向量 λ \lambda λ的切比雪夫聚合函数 g t e g^{te} gte,从 C S CS CS中选出 K K K个最优解形成临时精英种群 T E P TEP TEP;
- 从 T E P TEP TEP中随机选取两个解作为生成算子的输入生成新解 y y y。
- 改善:对 y y y运用启发式方法进行改善,生成 y ′ y^\prime y′;
- 更新 z z z:对 j = 1 , 2 , . . . , m j=1,2,...,m j=1,2,...,m,如果 z j < f j ( y ′ ) z_j
- 更新 T E P TEP TEP中的解:
- 针对使用权重向量 λ \lambda λ的切比雪夫聚合函数 g t e g^{te} gte,如果 y ′ y^\prime y′比 T E P TEP TEP中的最差解好并且和TEP中所有解的 F F F-values都不同,就将其添加进 C S CS CS集合。
- 如果 C S CS CS集合大小大于 K × S K × S K×S,删除 C S CS CS中最旧的解(存在时间最长的解)。
- 更新EP:从EP中移除 F ( y ′ ) F(y^\prime) F(y′)的支配向量;如果EP中不存在支配 F ( y ′ ) F(y^\prime) F(y′)的向量就将 F ( y ′ ) F(y^\prime) F(y′)加入EP。
停止迭代: 满足停止条件后,停止迭代。否则,重新进入迭代循环步骤。
MOGLS vs. MOEA/D(Complexity)
- Space Complexity:在进行搜索时,MOEA/D算法需要保留内部种群的 N N N个解以及外部种群。而MOGLS需要存储 C S CS CS集合, C S CS CS大小会一直增加直到最大边界 K × S K × S K×S。因此,如果 K × S K × S K×S比 N N N大且两种算法生成了相同数量的非支配解时,MOEA/D的空间复杂度小。
- Computational Complexity:重要的复杂计算集中在迭代循环步骤。
- 基因重组步骤, ∣ C S ∣ |CS| ∣CS∣非常大时,MOGLS的计算复杂度远高于MOEA/D:
MOGLS:需要生成 T E P TEP TEP。一是计算 C S CS CS中所有点的目标函数值 f j ( x ) f_j(x) fj(x),需要 O ( m × ∣ C S ∣ ) O(m×|CS|) O(m×∣CS∣);二是在选择 T E P TEP TEP时需要计算 g t e g^{te} gte值, O ( K × ∣ C S ∣ ) O(K×|CS|) O(K×∣CS∣);
MOEA/D:只需要随机选取两个用于生成算子的解。 - 改善新解 y y y和更新参考点向量 z z z步骤,两者相同;
- 更新 T E P TEP TEPvs.更新邻居解:MOEA/D需要 O ( T ) O(T) O(T);MOGLS需要 O ( K ) O(K) O(K)【计算 T T T个邻居解的 g t e g^{te} gte或者计算 K K K个 T E P TEP TEP解的 g t e g^{te} gte】。当 T T T和 K K K的值选取接近时,两算法差别不大。
综上,大概可以判断MOEA/D的计算复杂度小。【主要由于基因重组生成新解步骤】
多目标0-1背包问题—MOKP
给定 n n n个物品和 m m m个背包,在满足容量限制的条件下使收益最大化。MOKP的数学描述为:
m a x m i z e f i ( x ) = ∑ j = 1 n p i j x j , i = 1 , . . . , m s . t . ∑ j = 1 n w i j x j ≤ c j , i = 1 , . . . , m x = ( x 1 , . . . , x n ) T ∈ { 0 , 1 } n ( 1 ) maxmize\quad f_i(x)=\sum_{j=1}^{n}p_{ij}x_j,i=1,...,m\\s.t.\quad \sum_{j=1}^{n}w_{ij}x_j\le c_j,i=1,...,m\\x=(x_1,...,x_n)^T \in \left\{0,1\right\}^n\quad (1) maxmizefi(x)=j=1∑npijxj,i=1,...,ms.t.j=1∑nwijxj≤cj,i=1,...,mx=(x1,...,xn)T∈{0,1}n(1)
其中:第 i i i个背包中第 j j j个物品的价格 p i j ≥ 0 p_{ij}\ge 0 pij≥0;第 i i i个背包中第 j j j个物品的重量 w i j ≥ 0 w_{ij}\ge 0 wij≥0; c i c_i ci是第 i i i个背包的容量; x i = 1 x_i=1 xi=1时意味着物品 i i i被选中并且将其放进所有的背包中。
关于该问题的9个测试实例被广泛用于多目标启发式算法的测试。在大量的MOEA算法中,MOGLS针对这些测试实例展现出了较为杰出的性能。
两种算法的MOKP具体实施
修复方法
修复方法主要是为了修正启发式算法所搜索到的非可行解。令 y = ( y 1 , . . . , y n ) T ∈ { 0 , 1 } n y=(y_1,...,y_n)^T\in \left\{0,1\right\}^n y=(y1,...,yn)T∈{0,1}n为 M O P ( 1 ) MOP(1) MOP(1)的一组不可行解。一种方法可以将某些 y i y_i yi由1改成0使得 w i j ≥ 0 , p i j ≥ 0 w_{ij}\ge 0, p_{ij}\ge 0 wij≥0,pij≥0。Jaszkiewicz提出了一种贪心修复算法。
- INPUT&OUTPUT:
Input:MOP,解 y y y,待最大优化的目标函数 g : { 0 , 1 } n ⟶ R g:\left\{0,1\right\}^n\longrightarrow R g:{0,1}n⟶R;
Output:可行解 y ′ = ( y 1 ′ , . . . , y n ′ ) T y^\prime=(y_1^\prime,...,y_n^\prime)^T y′=(y1′,...,yn′)T - Step(1):如果 y y y是可行的,令 y ′ = y y^\prime=y y′=y并返回 y ′ y^\prime y′;
- Step(2):令 J = { j ∣ 1 ≤ j ≤ n and y j = 1 } J=\left\{j|1\le j\le n \text { and } y_j=1\right\} J={j∣1≤j≤n and yj=1}且 I = { j ∣ 1 ≤ j ≤ m and ∑ j = 1 n w i j x j > c j } I=\left\{j|1\le j\le m\text { and }\sum_{j=1}^{n}w_{ij}x_j>c_j\right\} I={j∣1≤j≤m and ∑j=1nwijxj>cj}
- Step(3):选择 k ∈ J k\in J k∈J例如 k = a r g m i n j ∈ J g ( y ) − g ( y j − ) ∑ i ∈ I w i j k=arg\underset{j\in J}{min}\frac{g(y)-g(y^{j-})}{\sum_{i\in I}w_{ij}} k=argj∈Jmin∑i∈Iwijg(y)−g(yj−)
其中, y j − y^{j-} yj−仅与 y y y在 j j j处的值不同【例如:对所有的 i ≠ j , y i j − = y i ∧ y j j − = 0 ( y j = 1 ) i\ne j,y_i^{j-}=y_i\wedge y_j^{j-}=0(y_j=1) i=j,yij−=yi∧yjj−=0(yj=1)】。令 y k = 0 y_k=0 yk=0并返回Step(1)。
这种方法中,在这种方法中,物体被一个一个移除直到 y y y为可行解。过重背包中拥有较重质量( ∑ i ∈ I w i j \sum_{i\in I}w_{ij} ∑i∈Iwij)以及对 g ( x ) g(x) g(x)贡献小的物体( g ( y ) − g ( y j − ) g(y)-g(y^{j-}) g(y)−g(yj−))更可能被移除。
MOGLS的实施方案
修复算法使用Jaszkiewicz提出的贪心算法。使用切比雪夫方法的MOGLS算法细节如下:
- 初始化 z = ( z 1 , . . . , z m ) T z=(z_1,...,z_m)^T z=(z1,...,zm)T:针对每一个目标函数 f i f_i fi随机生成一个点,应用修复算法将其修正为可行解。将该点的 f i f_i fi值定为 z i z_i zi。
- 初始化 E P 、 C S EP、CS EP、CS:初始化 E P 、 C S EP、CS EP、CS为空集,然后将下列步骤重复 S S S次。
1. 使用论文中描述的采样算法随机生成权重向量 λ \lambda λ;
2. 随机生成解 x = ( x 1 , . . . , x n ) T ∈ { 0 , 1 } n x=(x_1,...,x_n)^T\in \left\{0,1\right\}^n x=(x1,...,xn)T∈{0,1}n,其中 x i = 1 x_i=1 xi=1(即被选中)的概率是0.5;
3. 将 − g t e ( x ∣ λ , z ) -g^{te}(x|\lambda,z) −gte(x∣λ,z)设为修复算法的目标函数,对 x x x使用修复算法得到可行解 x ′ x\prime x′;
4. 将 x ′ x\prime x′添加进 C S CS CS。从 E P EP EP中移除所有被 F ( y ′ ) F(y\prime) F(y′)支配的目标向量。如果原EP中不存在支配 F ( y ′ ) F(y\prime) F(y′)的向量,将 F ( y ′ ) F(y\prime) F(y′)加入EP。 - 生成算子:单点交叉算子和标准变异算子。单点交叉生成子代解child solution,变异算子以每个点为0.01的变异概率对子代解进行变异操作生成新解 y y y。
- 改善修复算法:Jaszkiewicz提出的贪心算法。
MOEA/D的实施方案
使用与MOGLS相同的生成算子、 z z z的初始化方法以及改善修复算法。第 i i i个子问题的初始解 x i x^i xi的初始化方法:将 − g t e ( x ∣ λ , z ) -g^{te}(x|\lambda,z) −gte(x∣λ,z)设为目标函数,对随机生成的解应用修复算法。令 x i x^i xi为修复后的解。
采用加权和分解方法时,两个算法的具体实施过程基本一致。除了修复算法中将 g w s g^{ws} gws作为目标函数以及不保留 z z z。
参数设置
MOGLS:设置 K = 20 K=20 K=20,针对不同的实例设置不同的 S S S;
MOEA/D:设置 T = 10 T=10 T=10, N N N和 λ 1 , . . . , λ N \lambda^1,...,\lambda^N λ1,...,λN的设定与参数 H H H有关。每一个权重值取自 { 0 H , 1 H , . . . , H H } \left\{\frac{0}{H}, \frac{1}{H},...,\frac{H}{H} \right\} {H0,H1,...,HH}。因此,权重向量个数 N = C H + m − 1 m − 1 N=C_{H+m-1}^{m-1} N=CH+m−1m−1。
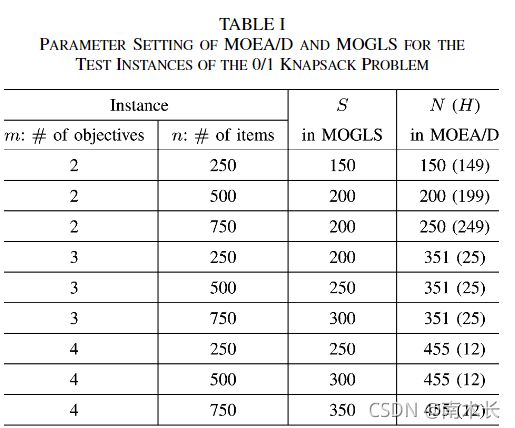
实验结果
每个测试函数在MOGLS和MOEA/D算法中独立运行30次。
评价指标
覆盖率——C-metric:
令 A A A和 B B B是一个MOP中两个PF的近似解集,定义 C ( A , B ) C(A,B) C(A,B)如下:
C ( A , B ) = ∣ { u ∈ B ∣ ∃ v ∈ A : v dominates u } ∣ ∣ B ∣ C(A, B)=\frac{|\{u \in B \mid \exists v \in A: v \text { dominates } u\}|}{|B|} C(A,B)=∣B∣∣{u∈B∣∃v∈A:v dominates u}∣
其中, C ( A , B ) ≠ 1 − C ( B , A ) C(A,B)\ne1-C(B,A) C(A,B)=1−C(B,A)。 C ( A , B ) = 1 C(A,B)=1 C(A,B)=1意味着 B B B中所有的解都被 A A A中的某些解支配了, C ( A , B ) = 0 C(A,B)=0 C(A,B)=0意味着 B B B中没有解被 A A A中的解支配。 C ( A , B ) C(A,B) C(A,B)越大就证明 A A A中的解对 B B B中解的支配度越高,即 A A A中的解越优于 B B B中的解。
距离度量——D-metric:
令 P ∗ P^* P∗为一组均匀分布在PF上的点的集合, A A A是PF的近似解集。 P ∗ P^* P∗到 A A A的平均距离定义为:
D ( A , P ∗ ) = ∑ v ∈ P ∗ d ( v , A ) ∣ P ∗ ∣ D\left(A, P^{*}\right)=\frac{\sum_{v \in P^{*}} d(v, A)}{\left|P^{*}\right|} D(A,P∗)=∣P∗∣∑v∈P∗d(v,A)
其中, d ( v , A ) d(v, A) d(v,A)是 v v v点和 A A A中某点的最小欧氏距离。如果 P ∗ P^* P∗足够大( P ∗ P^* P∗中解的个数足够多),说明其可以很好的代表PF。 D ( A , P ∗ ) D\left(A, P^{*}\right) D(A,P∗)可以在某种意义上评估 A A A的收敛性和多样性。 D ( A , P ∗ ) D\left(A, P^{*}\right) D(A,P∗)值越小,就说明 A A A越接近PF,收敛性越好。
结果
作者直接使用Jaszkiewicz求解的upper approximation of the PF作为真实的PF点。通过对比平均CPU运行时间和评价指标的均值与标准差,得出如下结论:
- CPU time:
- 横向对比:针对2/3/4目标函数实例,MOEA/D算法的运行时间都远小于(大约是1/7)MOGLS,印证了MOEA/D计算复杂度小这一特征;
- 纵向对比:MOEA/D——2/3目标函数下加权和分解方法运行速度快,4目标函数下切比雪夫方法运行速度快;MOGLS——2目标函数下,切比雪夫方法运行速度快,3/4目标函数下加权和方法运行速度快。
- 对所有的测试实例,使用加权和或者切比雪夫方法的MOEA/D算法可以在更少次修复下达到最小化D-metric的目的。
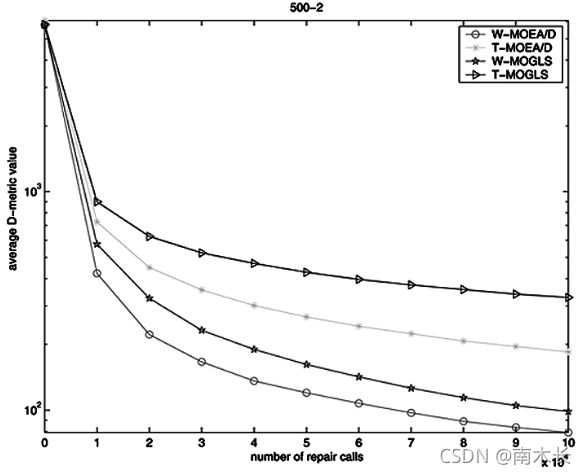
- 对于C-metric值和D-metric值(及标准差值):
- C-metric值:选取解集 A A A为MOEA/D算法求解的解集,解集 B B B为MOGLS算法求解的解集。实验结果显示两种方法下绝大部分 C ( A , B ) C(A,B) C(A,B)明显大于 C ( B , A ) C(B,A) C(B,A)(尤其是切比雪夫分解方法),即MOEA/D算法得出的解集支配MOGLS算法得出的解集。
- D-metric值:MOEA/D算法的值均小于MOGLS算法的D值,且绝大多数标准差也更小,MOEA/D算法的收敛性更好。
- 从收敛性来看,切比雪夫分解方法下两种算法收敛性能更好。
综上,在多目标背包问题中MOEA/D算法性能很好的体现了其计算复杂度低的特点,同时其收敛性也明显优于MOGLS算法。
MOEA/D vs. NSGA Ⅱ
测试函数:ZDT1~ZDT4、ZDT6,DTLZ1、DTLZ2[跳转]。
NSGA-Ⅱ基础理论知识:跳转。
利于实验对比的MOEA/D变体
为了保证两者有一个公平的对比,对MOEA/D算法做出了如下变动:
- 取消EP:将内部种群产生的最终迭代解返回为算法所得的PF近似解,因此也就不存在更新EP这一步骤;
- 不使用修复方法,因此不存在改善这一步骤;
- 更新邻居解时使用 g t e g^{te} gte,即使用切比雪夫分解方法。
加权和方法无法处理非凸解,所以此处采用切比雪夫分解方法。
NSGA-Ⅱ vs. MOEA/D(Complexity)
Space:与NSGA-Ⅱ相比,MOEA/D算法额外的内存需求仅多了存储 z z z,而 z z z的大小是 O ( m ) O(m) O(m),与种群大小相比 z z z很小。因此两者空间复杂度相近。
Computational:NSGA-Ⅱ的复杂度为 O ( m N 2 ) O(mN^2) O(mN2)[跳转],MOEA/D的计算复杂度为 O ( m N T ) O(mNT) O(mNT)。MOEA/D算法的计算复杂度主要集中在迭代循环步骤:移除了改善步骤和更新EP步骤后,基因重组步骤随机选取两个解、更新 z z z步骤计算 y y y对应的m个目标函数值用于更新 z z z— O ( m ) O(m) O(m)、更新邻居解步骤需要计算 T T T个邻居解的 g t e g^{te} gte值(计算一个邻居解就需要m次)— O ( m T ) O(mT) O(mT)。针对 N N N个子问题求出最优解组成最终的PF近似解集— O ( m N T ) O(mNT) O(mNT)。因此,它们的计算量每一代的复杂性为 O ( m N T ) O ( m N 2 ) = O ( T ) O ( N ) \frac{O(mNT)}{O(mN^2)}=\frac{O(T)}{O(N)} O(mN2)O(mNT)=O(N)O(T)
由于 T T T远小于 N N N,因此MOEA/D比NSGA-II计算复杂度低。
参数设置
种群规模:2目标函数设为100;3目标函数设为300;
迭代次数:设为250。
种群初始化:在可行域内均匀随机采样。
z i z_i zi初始化:设置为初始种群中 f i f_i fi的最小值。
生成算子:SBX & polynomial mutation,分布参数设为20。
交叉概率:设为1。
变异概率:设为 1 / n 1/n 1/n,其中 n n n是决策变量个数。
权重向量的生成:同MOGLS对比实验时的生成方法(N、H)。
T:设为20。
每次对比试验运行30次。
真实PF:2目标函数选取了PF上的500个均匀分布的解;3目标函数选取了PF上990个均匀分布的解。
实验结果
- CPU time:对2目标测试函数,MOEA/D算法是NSGA-Ⅱ算法的两倍快;对3目标测试函数,MOEA/D算法是NSGA-Ⅱ算法的八倍快。
- D-metric的收敛速率:在ZDT4/6和DTLZ1/2测试函数上,MOEA/D最小化D-metric值的速率更快。在其他几个测试函数上,与NSGA-Ⅱ持平或稍慢。
- C-metric值:选取解集 A A A为MOEA/D算法求解的解集,解集 B B B为NSGA-Ⅱ算法求解的解集。实验结果显示两种方法下绝大部分 C ( A , B ) C(A,B) C(A,B)明显大于 C ( B , A ) C(B,A) C(B,A)(除了ZDT4),即MOEA/D算法得出的解集支配MOGLS算法得出的解集。
- D-metric值:MOEA/D在ZDT4/6和DTLZ1/2上所求D-metric值小于NSGA-Ⅱ。在其他几个测试函数上,略差于NSGA-Ⅱ。
- 解的分布性及收敛性:在ZDT1/2/6和DTLZ1/2测试函数上,MOEAD算法的分布性更好。在ZDT4函数上,两者分布性近似。在ZDT3函数上,NSGA-Ⅱ表现更好,MOEA/D找到的解少于NSGA-Ⅱ。
综上,使用切比雪夫方法的MOEA/D算法运行速度快。对于搜索到的解的质量,两者在2目标函数上表现近似,MOEA/D算法在3目标函数上的表现性能要明显优于NSGA-Ⅱ。
对MOEA/D算法的一些改进
通过对目标函数归一化可以使解的分布性得到明显改善。易判断,ZDT3测试函数是不连续的,DTLZ1/2问题中有两个问题是自然上升的。为了改善解的分布性,作者使用采用PBI方法的MOEA/D对DTLZ1/2进行优化,使用对目标函数归一化的MOEA/D对ZDT3进行优化。改善后结果如下:
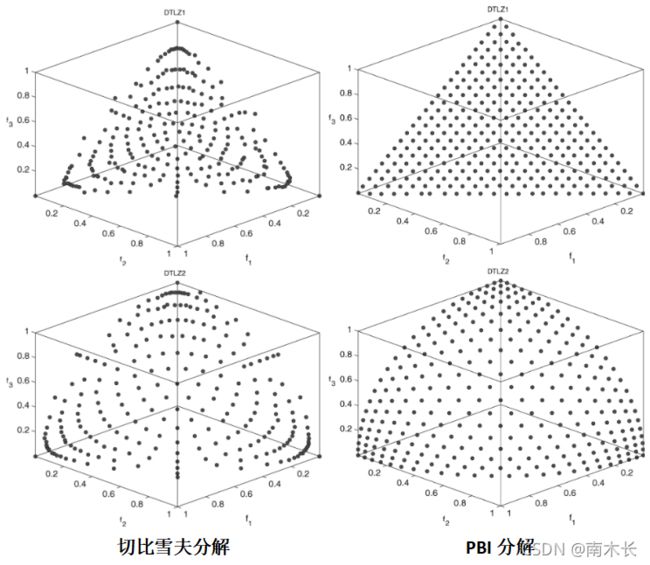
采用PBI分解方法的MOEA/D算法
作者使用PBI分解方法在两个3目标问题上进行测试,选取惩罚因子 θ = 5 \theta = 5 θ=5,其他参数设置和采用切比雪夫方法的MOEA/D算法相同。实验结果显示,采用PBI分解方法的D-metric值最小。且由实际解集分布(下图)可看出,PF近似解的分布性得到了明显的改善。因此,在MOEA/D框架中采用更为先进的分解方法解决3及以上目标函数的多目标问题是值得研究的。
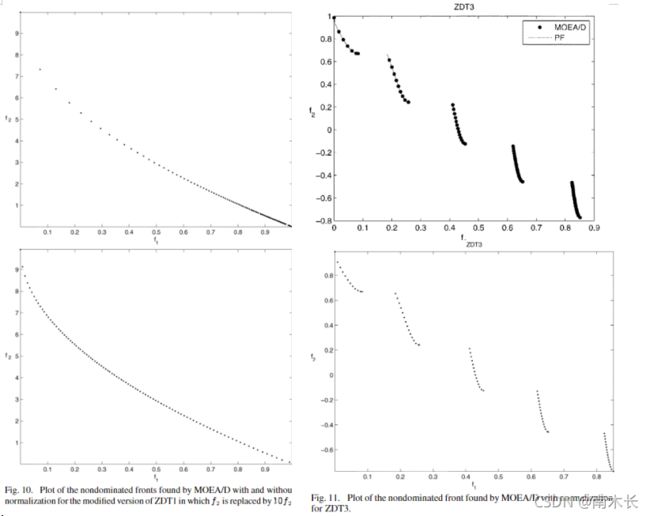
采用目标函数归一化的MOEA/D算法
作者仍采用基于切比雪夫分解方法的MOEA/D算法且不对参数做任何修改,仅在实施过程中对目标函数归一化。最简单的归一化方法是令(多目标问题为最小化问题)
f i = f ˉ i = f i − z i ∗ z i n a d − z i ∗ f_i=\bar{f}^i=\frac{f_i-z_i^*}{z_i^{nad}-z_i^*} fi=fˉi=zinad−zi∗fi−zi∗
其中, z ∗ = ( z 1 ∗ , . . . , z m ∗ ) T z^*=(z_1^*,...,z_m^*)^T z∗=(z1∗,...,zm∗)T为参考点, z n a d = ( z 1 n a d , . . . , z m n a d ) T z^{nad}=(z_1^{nad},...,z_m^{nad})^T znad=(z1nad,...,zmnad)T为目标空间的最低点。例如, z i n a d = m a x { f i ( x ) ∣ x ∈ P S } z_i^{nad}=max\left\{f_i(x)|x\in PS\right\} zinad=max{fi(x)∣x∈PS}。换句话说, z n a d z^{nad} znad定义了PF的上界,PF前沿。易判断, f i − z i ∗ ≤ z i n a d − z i ∗ f_i-z_i^*\le z_i^{nad}-z_i^* fi−zi∗≤zinad−zi∗。由此就将每一个目标函数的范围转化到了[0,1]范围内。
但是,预先计算 z n a d z^{nad} znad和 z ∗ z^* z∗是困难的。作者以 z z z代替 z ∗ z^* z∗[前文中提到的初始化 z z z及更新 z z z的方法所产生的 z z z即为 z ∗ z^* z∗的替代],以 z ~ i n a d \tilde{z}_i^{nad} z~inad(当前种群下 f i f_i fi的最大值)代替 z i n a d z_i^{nad} zinad。因此,计算 g t e g^{te} gte的式子由 m a x 1 ≤ i ≤ m { λ i ( f i − z i ) } \underset{1\le i\le m}{max}\left\{\lambda_i(f_i-z_i)\right\} 1≤i≤mmax{λi(fi−zi)}变为 m a x 1 ≤ i ≤ m { λ i ∣ f i − z i z ~ i n a d − z i ∣ ) } . \underset{1\le i\le m}{max}\left\{\lambda_i\left |\frac{f_i-z_i}{\tilde{z}_i^{nad}-z_i}\right |)\right\}. 1≤i≤mmax{λi∣∣∣∣z~inad−zifi−zi∣∣∣∣)}.
实验结果显示,通过对目标函数归一化可以对不同缩放程度的目标函数所构成的MOP解的分布性得到明显改善。
Scability, Sensitivity, and Small Population in MOEA/D
对T的敏感性分析
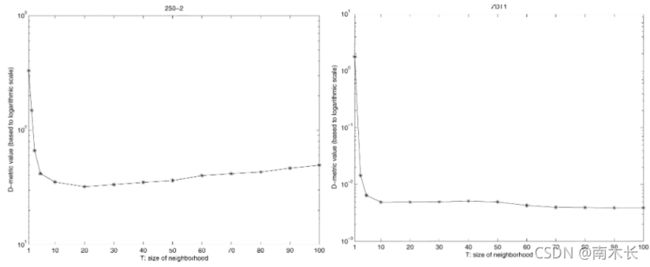
作者采用控制变量法对T进行敏感性分析。分别对250-2背包问题和ZDT1进行敏感性分析。结果显示,T在10到50范围内MOEA/D对250-2背包问题表现得性能都较好。对ZDT1,MOEA/D在除了特别小的值之外所有T值情况下表现性能都很好。可以说,MOEA/D对T的设置不敏感(至少在相似问题下不敏感)。
在250-2背包问题中,T过大过小表现都不好: T T T太小,子代解和父代解会十分接近,从而使得算法缺乏探索其他搜索区域的能力; T T T太大,生成算子的两个输入解性能会很差,从而导致子代解性能也很差,影响算法的搜索能力。此外,T太大也会在更新邻居解步骤时产生较大的计算复杂度。
而在ZDT1问题中,T过大算法的表现性能依旧不错,可能是因为即使两个子问题的权重向量十分不同,但是它们相关子问题的最优解还是十分相似的。
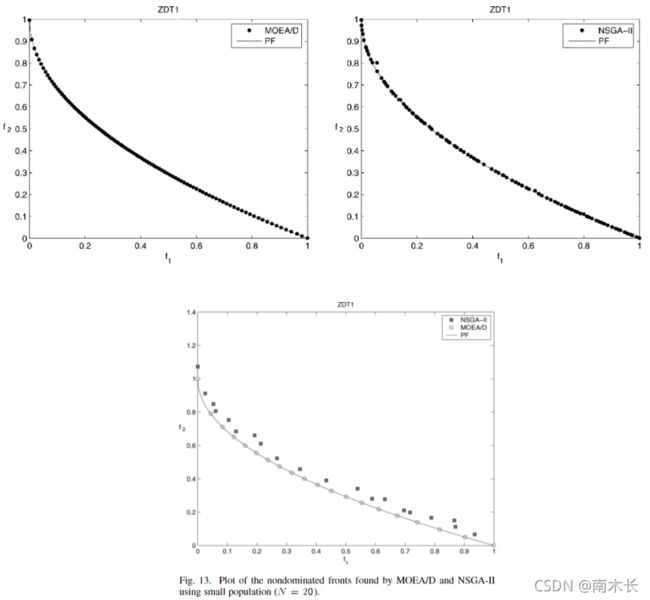
小种群的MOEA/D算法
通常决策者并不需要消耗大量计算能力的大量Pareto最优解,他们只希望在小的计算复杂度情况下获得均匀分布的少量Pareto最优解。小种群的MOEA/D算法仍能获得在PF上均匀分布的解。作者以ZDT1为例,并采用前文相似的切比雪夫方法,仅将 N N N设为20(前文是100)。结果显示, N = 20 N=20 N=20情况下得到的Pareto最优解仍是在PF上均匀分布,而NSGA-Ⅱ算法则无法在相同迭代次数下找到最优解。
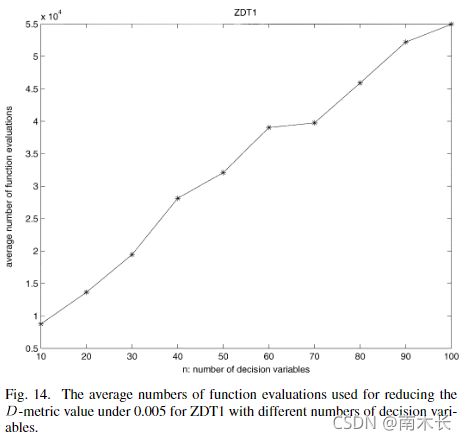
扩充性
为了观察在将D-metric降低到相同水平时决策变量个数与函数计算的平均次数之间的关系,作者在ZDT1上进行了实验。除了迭代次数变为1000次(最大函数计算次数为 1 0 5 10^5 105),其他参数设置与前文MOEA/D算法相同。结果显示,随着决策变量个数的增加,函数计算次数线性增加。
Conclusion
MOEA/D算法首先将MOP分解为一组单目标子问题。然后利用EA同时对这些子问题进行优化。MOEA/D种群中的每一个个体解都和一个子问题相关联。所有子问题之间的邻居关系定义为它们的权重向量之间的距离。在MOEA/D算法中,使用当前子问题的邻居子问题当前解对当前子问题进行优化。
作者将MOEA/D算法与MOGLS算法和NSGA-Ⅱ算法进行比较。结果显示MOEA/D算法拥有更低的计算复杂度,且在大多数测试问题中,MOEA/D算法所求解的质量更好。
作者通过PBI分解和目标函数归一化方法改进MOEA/D,体现了MOEA/D算法的可优化性。
作者采用控制变量法得出了MOEA/D算法对T不敏感,小种群下的MOEA/D算法同样可以得到均匀分布的解以及随着决策变量个数的增加MOEA/D的计算复杂度会线性增加的结论。
参考文献及链接
[1]Qingfu Zhang, Hui Li.MOEA/D: A Multiobjective Evolutionary Algorithm
Based on Decomposition[J].IEEE TRANSACTIONS ON EVOLUTIONARY COMPUTATION,2007(6):712-731