TANE算法:一种发现函数和近似依赖关系的有效算法
文章目录
-
- 一、TANE算法介绍
-
- 1.1. 函数依赖定义:
- 1.2. 近似函数依赖
- 二、划分和依赖关系
-
- 2.1. 划分
-
- 等价类概念
- 划分概念
- 2.2. 划分细化
-
-
- 引理2.1
- 引理2.2
-
- 2.3. 近似依赖
- 三、搜索
-
- 3.1. 搜索策略
- 3.2. 简化搜索空间
-
- 3.2.1. Rhs候选
-
- 修剪规则
- 3.2.2. Rhs+候选修剪
-
- 引理3.1
- 引理3.2
- 引理3.3
- 3.2.3. 键修剪
-
- 引理3.4
- 3.3. 计算与分区
-
- 3.3.1. 剥离分区
-
- 引理3.5
- 3.3.2. 边界条件e
- 3.3.3. 计算分区
- 四、TANE算法
-
- 4.1. TANE主要算法
- 4.2. 生成级别
- 4.3. 计算依赖
- 4.4. 修剪格子
-
- RHS+修剪
- 键修剪
-
- 引理4.2
- 引理4.2推论
- 4.5. 计算分区
- 4.6. 近似依赖
- 五、TANE理解
-
- 5.1. 高效性
- 5.2. 正确性
-
- 计算函数依赖
- 剪枝过程
- 5.3. 合理性
- 六、总结
一、TANE算法介绍
1.1. 函数依赖定义:
若对于R(U)的任意两个可能的关系r1、r2,若r1[x]=r2[x],则r1[y]=r2[y],或者若r1[y]不等于r2[y],则r1[x]不等于r2[x],称X决定Y,或者Y依赖X。
我们考虑的中心任务:给定一个关系,找到r中所有的最小的非平凡依赖关系
1.2. 近似函数依赖
如何定义依赖项相似性,我们使用的定义是基于需要从关系r中删除,X->A才在r中成立的最小元组数(基于…的数量)。用需要删除的最小元组数,除以r的阶,即r中元组数表示近似的程度,比值越小,说明近似依赖性越高

该算法关于属性数量的最坏情况下的时间复杂度是指数级的。然而,对于元组的数量,时间复杂度只是线性的(前提是依赖关系集不会随着元组数量的增加而变化)。线性,使得TANE特别适合与大量元组的关系。
我们的搜索策略:
- 计算关于属性集的重要信息:划分
- 根据信息,得出依赖关系
二、划分和依赖关系
2.1. 划分
如果所有同意X的元组也同意A,则依赖项X→A成立。这句话的等价说法是,如果若对于R(U)的任意两个可能的关系r1、r2,若r1[X]=r2[X],则r1[A]=r2[A],则依赖项X→A成立
等价类概念
属性集X的某一等价类[t]X是指在给定关系实例中,所有与元组t在X上取值相等的元组的集合。
划分概念
属性集X上的划分的 π x \pi _{x} πx的含义是在给定关系实例r中,X的所有等价类的集合。
这就是说 π x \pi _{x} πx是一组不相交的元组的集合(等价类)的集合。这样, 每个集合(等价类)内部的元组在属性集X中的取值是相等的,并且,这些集合的并集就等于关系实例r。
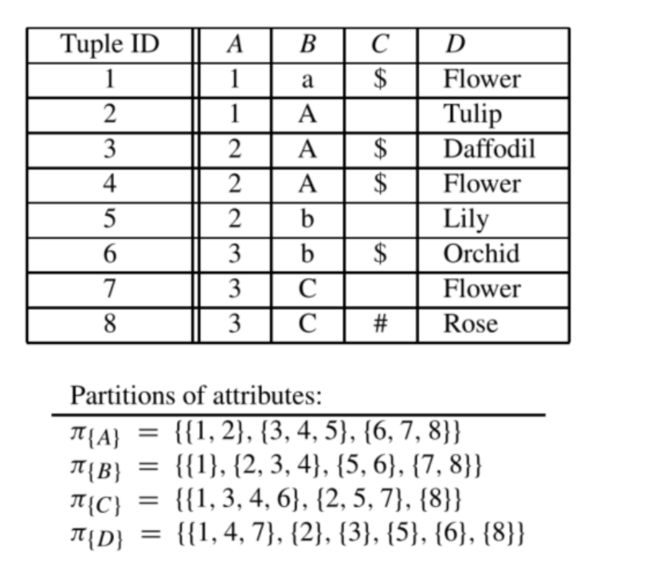
2.2. 划分细化
划分细化的概念几乎直接给出了函数依赖关系。如果π{X}中的每个等价类都是π{A}相应唯一一个等价类的子集,那么分区π{X}细化另一个划分π{A}。

如果每一种着色代表着一个等价类的话,着色相同则代表取值相同,则左图π{X}细化了π{A},但右图由于元组5的存在,所以π{X}并非细化了π{A}
引理2.1
当且仅当划分π{X}细化划分π{A}时,函数依赖X->A成立。因为π{X}中每一个等价类都是π{A}的相应等价类的子集,因此,认同X成立的元组也都认同A成立。
引理2.2
当且仅当|π{X}|=|π{XU{A}}|时,函数依赖X->A成立。
证明:属性集每多一个属性就多一个约束条件,所以对XU{A}划分所得结果必是对X所划分的结果的子集,即π{XU{A}}天然是对π{X}的细化。除非π{XU{A}}与π{X}相等,否则不可能有相同数量的等价类。
二者相等说明什么:认同X成立的元组也都认同A成立。
2.3. 近似依赖
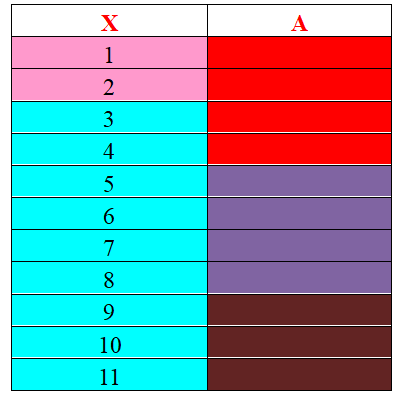
error e (X->A)是需要从关系r中删除,使得X->A在r中成立的最小元组的比例。可以根据π{X}、π{XU{A}}来计算e,πX任何等价类c都是πXU{A}的一个或多个等价类c1、c2,…的并集,要使得X->A成立,保留一个等价类,其余ci中的所有元组全部删除。对于上图而言,保留的一个等价类是{3,4},删除5元组。
因此,要删除的最小元组数是c的大小减去ci中最大的大小。ํ对πX的所有等价类求和,得到要删除的元组总数。

理解:删除的最小元组数是c的大小减去ci中最大的数量。下图中,最大的为5678,数量为4,因此最小删除元组数为9-4=5,即删除的是3491011
三、搜索
3.1. 搜索策略
要找到所有最小的非平凡依赖关系,TANE的工作原理如下。它从单个属性集开始搜索,然后逐级通过集合包含格来搜索更大的属性集。当算法处理集合X时,它测试形式为X \ {A} -> A的依赖关系,其中A∈X。这保证了只考虑非平凡的依赖关系1。算法由从小到大的方向可以用来保证只有最小的依赖关系得到输出。它还可以用于有效地精简搜索空间(参见图2)。
一种类似的大小搜索策略,即水平算法,已成功地应用于许多数据挖掘应用。除了有效的剪枝外,水平算法的效率还是基于使用以前层次的结果来减少每个层次的计算。
在本节中,我们考虑了搜索的不同方面,包括TANE中水平算法的有效剪枝标准,以及分区的快速计算。这两个任务都可以通过使用来自以前级别的信息来有效地解决。根据本节中提供的材料,在第4节中给出了精确的算法。
3.2. 简化搜索空间
3.2.1. Rhs候选
TANE通过格子工作,直到找到保持的最小依赖关系。为了测试潜在依赖项X \ {A}→A的最小值,我们需要知道Y \ {A}→A对于X的某个真子集Y是否成立。我们把这个信息存储在Y的右边候选的集合C(Y)中。

对于给定的集合X,如果A∈C(X),则A不依赖于X的任何真子集(∵A不依赖X)。更准确地说,某一集X的初始rhs候选项的集合为C(X) = R\ C ( X ) ‾ \overline{C(X)} C(X), C ( X ) ‾ \overline{C(X)} C(X)={A ∈ X | X \{A} → A holds}。
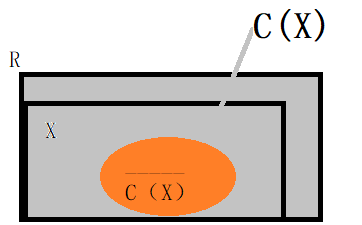
C ( X ) ‾ \overline{C(X)} C(X)为X中满足X\A->A的属性集合。
①A∉C(X)即A∈ C ( X ) ‾ \overline{C(X)} C(X):A属于X,且A依赖X
②A∈C(X):A不属于X或A属于X,但A不依赖X(X\A->A不成立)。
要找到最小的依赖项,只需测试依赖项X \ {A}→A,其中A ∈ X 且对所有B ∈ X,有A ∈ C(X \ {B})。目的是保证,对于X的真子集Y,Y \ {A}→A不成立。
已知A ∈ X 对于所有B属于X,可以拆分成:
①B!=A,A ∈ C(X \ {B}) ⟹ \Longrightarrow ⟹ A属于X\B,但A不依赖X\B
②B = A,A ∈ C(X \ {B}) ⟹ \Longrightarrow ⟹A不属于X\A(天然成立)
A不依赖X\{A}的真子集,所以X\A->A是最小非平凡函数依赖
例2、为了说明初始rhs候选集,假设TANE正在考虑集合X = {A, B,C}并且{C}→A是一个有效的依赖项。既然{C}→A成立,则有A ∉ \notin ∈/C({A,C}) = C(X\{B}),这就告诉TANE {B,C}→A不是最小值。C(X\{B}) = C{A,C} = {A,B,C,D} \ {A} = {B,C,D}
∵ C{A,C} = R\ C ( A , C ) ‾ \overline{C(A,C)} C(A,C) = {A,B,C,D} \ {A} = {B,C,D}
∴对于这里的B属于X,A ∉ \notin ∈/C(X\{B}),即使得A依赖X\B ⟺ \Longleftrightarrow ⟺∵A依赖X的真子集
所以X\A–A不是最小值。
修剪规则
对TANE中的搜索空间进行剪枝时,假设C(X) =∅,则所有X的超集Y都是C(Y) =∅,这样就不存在Y \ {A}→A形式的依赖,也不需要处理集合Y。在集合包含格中的广度优先搜索可以有效地使用该信息,如图2所示。
C(X)为空,则 C ( X ) ‾ \overline{C(X)} C(X)为R,(由于A属于X,则这种情况应该只在X=R时成立)即所有属性都依赖于X。那么所有属性肯定会依赖X超集Y,C(Y) =∅,Y不用考虑,到X为止。
疑问?从X=R的角度,X的超集不存在。这里实在没看懂,感觉C(X)应该定义为X\ C ( X ) ‾ \overline{C(X)} C(X)
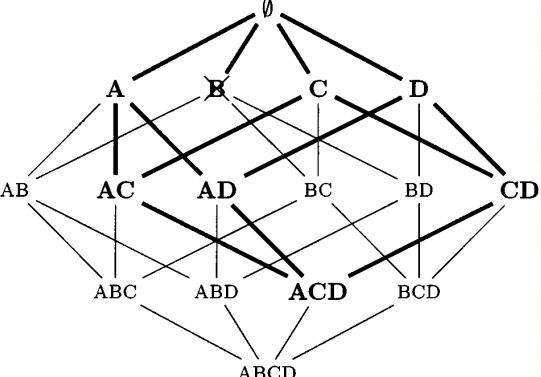
FIGURE 2. A pruned set containment lattice for {A, B,C, D}. Due to the deletion of B, only the bold parts are accessed by the levelwise algorithm.
3.2.2. Rhs+候选修剪
虽然初始的rhs候选足以保证发现依赖的最小化,但我们将使用改进的rhs+候选C+(X)来更有效地修剪搜索空间:
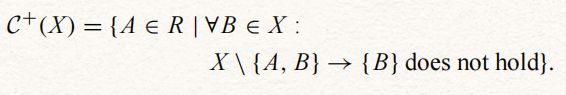
请注意,A可以等于B。下面的引理表明,我们可以使用rhs+候选对象来测试依赖性的最小性,就像我们将使用初始rhs候选对象一样。
引理3.1
设A∈X,且X\{A}->A为有效函数依赖,当且仅当对于all B ∈X,我们有A∈C+(X\{B})时,X\{A}->A为最小函数依赖。
A∈C+(X\{B})表示A不依赖X的子集。
如果我们用C(X\{B})替换C+(X\{B}),引理将成立,但是rhs+候选比初始rhs候选有两个优势。首先,我们可能会遇到一个具有B,使得A ∉ \notin ∈/C+(X\{B}),并提前停止检查,从而节省一些时间。其次,也是更重要的是,对于某些B,C+(X\{B})可以为空,而C(X\{B})不能为空。那么对于rhs+候选对象,由于修剪,集合X永远不会被处理。
如何理解???
对C+(X)的定义是基于函数依赖性的一个基本性质,如下引理所述。
这部分阐述的是从初始rhs到rhs+的过渡
引理3.2
设B属于X,且X \ {B}→B为有效依赖项。如果X->A成立,则X\ {B}→A成立。
引理允许我们从初始rhs候选集C(X)中删除额外的属性。假设X{B}->B对于某些B∈X成立。那么,根据引理,X在左边的依赖关系不可能是最小的,因为我们可以在不改变依赖的有效性的情况下从左边移除B。因此,我们可以安全地从C(X)中删除以下集合:
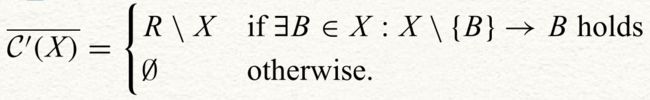
例3

引理3.3
3.2.3. 键修剪
如果没有两个元组同意X,即分区πX只由单例等价类组成,则属性集合X就是一个超键。
(数据表中的主键,对元组具有唯一标识作用!)
如果集合X是一个超键,并且没有一个真子集是超键,那么它是一个键。在搜索相关项过程中找到键时,可以应用其他修剪方法。在搜索依赖项过程中找到键时,可以应用其他修剪方法。
引理3.4
设B∈X,且X \ {B}→B为有效依赖项。如果X是一个超键,那么X \ {B}是一个超键。
一般在处理X∪{A}时,对一个依赖项X→A, A∉X进行检验,因为检验其有效性需要π[XU{A}]。但是,如果X是超键,那么X→A总是有效的,我们不需要X∪{A}。
现在,考虑一个不是键的超键X。很明显,对所有A∉X,依赖X→A不是最小的。此外,如果A ∈ X和X \ {A} → A成立,那么,根据引理3.4, X\{A}是一个超键,我们不需要πX来检验X \ { A }→A的有效性。换句话说,在寻找最小依赖关系时,我们不使用X或πX。因此,我们可以删除所有键及其超集。
为什么要删除所有键及其超集?如何直观理解
- 若Cplus(X)=φ,则删除X----X无用,剪掉是为了不再考虑超集
- 若X为(超)键,则删除X----X有用,但已经用过了,剪掉是为了不再考虑超集
3.3. 计算与分区
剥离分区与误差e
我们接下来介绍两种方法来减少使用分区的时间和空间需求。
-
第一种用更紧凑的表示来代替分区,“剥离分区”。
-
第二种是快速逼近e误差的方法。
这些方法优化了下一节中描述的算法。然后,我们描述了如何在逐级TANE算法中有效地计算分区。
对于这两种优化,我们都需要近似超键的概念。误差测度可以推广到关系的其他性质;具体来说,它可以扩展到作为超键的属性集的属性。我们将e(X)定义为需要从关系r中移除的元组的最小分数,以使X成为超键。如果e(X)很小, 那么X就是一个近似超键。 使用等式e(X)=1- |π[x]/|r|,很容易从分区π[x]计算出误差e(X)。
近似超键程度: X能够决定关系R中其他属性R\X的能力,所以需要移除的元组比例越小,越近似超键
若X为超键,则 |π[x]=|r|,则e(X)=0
3.3.1. 剥离分区
用 π ^ \hat{π } π^代表分区π的剥离版本,删除大小为1的等价类。丢弃单例等价类的一个直观解释是,单例等价类(左侧)不能破坏任何依赖关系。
剥离的分区包含与完整分区相同的信息。例如,值e(X)很容易使用方程从剥离分区计算:
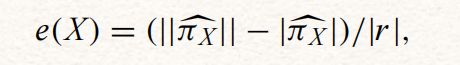
- ∣ π X ^ ∣ \left|\widehat{\pi_{X}}\right| ∣πX ∣表示剥离分区的阶:内部有多少个等价类
- ∥ π X ^ ∥ \left\|\widehat{\pi_{X}}\right\| ∥πX ∥表示剥离分区 π X ^ \widehat{\pi_{X}} πX 中所有等价类的大小的和
此外,分区的细化关系是相同的,因此引理2.1也适用于剥离的分区。
引理2.2对于剥离分区不成立
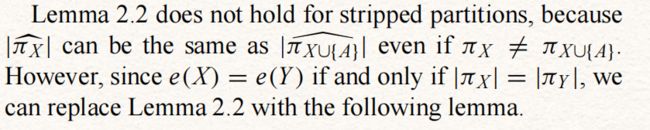
引理3.5
一个函数依赖X→A成立当且仅当e(X)= e(XU { A })。
通过分区,可以计算剥离分区,通过剥离分区可以计算误差e(X),从而验证X→A
3.3.2. 边界条件e
通过下面这种优化,可以节省判断近似函数依赖性的时间,因为有些e(X->A)不需要计算。
对于①,误差超过阈值,近似不成立;对于②,误差在阈值范围内,近似成立

3.3.3. 计算分区
每个属性集都不会从头开始计算分区。相反,当TANE通过晶格运行时,它将一个分区计算为以前计算过的两个分区的乘积。( it computes a partition as a product of two previously computed partitions)
两个分区 π’和 π" 的乘积,用π’.π’’ 表示,是同时细化分区π’ 和 π’’ 的最小细化分区 π。我们有以下结果:
引理3.6:
![]()
TANE算法计算分区如下图:
①计算每个属性的分区
②计算属性集至少为两个的分区,拆分成大小为|X|-1的两个不同子集,保证并集为X

一旦TANE有了分区πX,它将计算错误e(X),这将用于基于引理3.5的有效性测试。仅在计算下一级分区才需要完整的分区。
在为所有A∈R的第一个分区π{A}初始设置之后,TANE只处理元组标识符。这就提供了两个优势。首先,可以丢弃(还是区分)不同的属性类型和值,并且实际上是对整数进行计算的。因此,在分区上的操作非常简单而快速。其次,在计算近似依赖关系时,异常元组的标识符很容易获得。
这段话啥意思?没明白。
四、TANE算法
TANE’s的搜索空间修剪是基于这样一个事实,即对于一个完整的结果,只需要发现最小的函数依赖性。为了有效地修剪,该算法为每个属性组合X存储一组右侧候选对象C+(X)。
集合C+(X)={A∈R|∀B∈X:X \ {A,B}→B不成立}, 集合C+(X)包含仍然可能依赖于集合X的所有属性
4.1. TANE主要算法
为了找到所有有效的最小非平凡依赖关系,TANE以一种水平的方式搜索集包含格。Li级是大小为i的属性集的集合,这样Li中的属性集就可以用于基于前面各部分的考虑因素来构造依赖关系。TANE从L1={{A}|A∈R}开始,根据算法期间获得的信息,L2由L1计算得到、L3由L2计算得到,以此类推。
算法:TANE
输入:模式R上的关系r
输出:在r成立的最小非平凡函数依赖

步骤梳理:
-
其中Li级别包含大小为i的所有属性组合
-
每个属性组合X存储一组右侧候选对象C+(X)
-
第6行compute_dependencies(Li)用于在该层中找到并输出左侧的最小依赖关系、计算更新该层的候选函数依赖。
-
第7行prune( Li )进行剪枝操作,通过删除Li中的集合,修剪搜索空间
对于第 Li 层中的每个属性集 X,如果 C+ ( X) 为空,则从 Li中删除这个属性集 X; 如果X是一个键,那么对于属于 C+ ( X) \X这一集合中的每个属性 A:
如果 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-82dUVr20-1629358621235)(D:/OneDrive/文档/Assets/image-20210715101931011.png)],
则输出 X → A,最后,从第 Li 层中删除属性集 X。
-
第8行通过generate_next_level所有 i i i层结点生成相应 l l l层结点。
-
从这个总体过程可以看出TANE算法与Apriori算法的总体结构是类似的
-
从第1级(大小为1 属性集)开始,然后逐级向上移动
4.2. 生成级别
generate_next_level(Li)程序从Li层计算生成Li+1层。级别Li+1将只包含大小为i+1的属性集,所有大小为i的所有子集均在Li层中。剪枝方法保证不会丢失任何依赖关系。generate_next_level(Li)的规范为:即比len(Y)=len(X)-1,则Y为L[i-1]
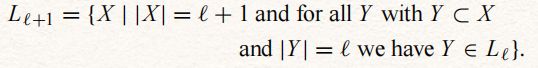
算法如下:

步骤梳理:
- 第2行的PREFIX_BLOCK(Li)是指对Li逻辑上按共同的前缀进行分组。
- 第3~4行体现的是同一具共同前缀组中两个不同结点,两两合并形成一个下层结点。
- 第5行对于刚生成的阶L[i+1]的结点依次检查,确定它所有阶为i的真子集结点是否都存于L[i]中。若都是存在,则将这个阶为i+1的结点纳入到L[i+1]集合中。
前缀块概念:
prefix_blocks(Li)过程将Li分成不相交的块,如下所示。【考虑一个集合X∈Li是一个已排序的属性集,如果两组X、Y∈Li具有长度为i−1的公共前缀,则属于同一前缀块,也就是说,它们只有一个属性不同,而不匹配属性是X和Y中的最后一个属性。】每个前缀块以L[i]的词典顺序形成一个连续的块,因此,前缀块很容易从词汇顺序的Li中计算出来。
为什么要有前缀块的概念?这样可以保证生成的X,只比上一层的属性集的阶多1。
生成原理:
首先令 L[i+1] 这一层为空集,对于 Li 这一层中的每一个前缀块 K 进行如下操作: 对于每一对包含于前缀块 K 中的两个不同的属性集 Y、Z,将 Y ∪ Z 的结果赋给 X,并判断如果对于所有属于属性集 X 中的属性 A,都有从 X 中去掉属性 A 之后,余下的属性仍然属于第 Li层这一结果,那么就将 L[i+1] ∪ { X} 的结果赋给 L[i+1] ,以生成第 L[i+1] 层。
当找出了给定的数据集存在的所有满足非平凡、最小条件的函数依赖之后,算法会终止,不再继续生成下一层。
举例:
图二中,AB,AC,AD属于同一个前缀块K,则存在的{Y,Z}组合有{AB,AC}(生成X=ABC)、{AB,AD}(生成X=ABD)、{AC,AD}(生成X=ACD)、
4.3. 计算依赖
下面是TANE算法的计算依赖过程:

通过引理3.12,步骤2、4和5保证该过程的输出正好是形式X\{A}—>A的最小依赖关系,其中为X∈Li和A∈X。
COMPUTE DEPENDENCIES(Li)的作用:
①在Li中找到左侧的最小依赖项②计算所有X ∈ \in ∈Li的集合C+(X)。(C+(X)集合的是包含仍然可能依赖于集合X的所有属性,即取得理论意义的最大值。)
步骤梳理:
- 第1,2行正是前述的通过上层结点的C+(X\A)来计算下层结点的初始C+(X)的做法:

这一步如何直观理解?为什么由上层的C+(X)可以计算下一层,原理是什么?
找所有可能依赖X\A(A∈X)的共同属性,求同。若X\A1的Cpus中不能决定某属性,则X也必不可能。
-
第3行可以看出是依次处理Li层的结点
-
第4-8行充分体现了引理3.1 以及C+(X)的内在含义。
原理:
-
A的取值为X与右方集交集,右方集为右侧候选对象
-
如果X\{A}->A成立,则X\{A}->A为最小函数依赖,输出,依据引理3.12
如果
- A∈X,X\{A}->A依赖成立
- A∈C+(X),A不依赖X的子集。
-
在C+(X)剪掉A,以及所有属于C+(X)\X的属性===在 C+(X)删掉所有属于R\X即不属于X的元素,即所留下的Cpuls只留下属于X的。
(减掉所有Z∈C+(X),使得X\Z->Z为最小值,或一定不是最小值的Z)换句话说,如果X包含FD X\A→A,则任何FD X→B都不能是最小值,因为A使X成为非最小值,即X\{A,B}->B一定成立。请注意,此定义还包括A=B。

注意:为什么不把X也排除,也就是说让右方集为空,因为剩下的元素为X子集,若X\{B}->B成立,无法判断是否为最小值,因此保留。
-
-
第5行的有效性测试基于引理3.53
-
第8行实现了C+(X)和C(X)之间的差异。如果删除了这一行,算法将正确工作,但修剪可能不那么有效。(暂时先不理解)
-
Q:通过compute_dependencies过程C+(X)只保留了X中的元素,那么,C+(X)\X不就是空了吗,为什么prune过程还要从中取元素呢?
A: 不空只能说明,对于所有属于X与C+(X)交集的A,X\A->A均不成立。否则,若有一项成立,根据line8,C+(X)只保留了X中的元素,排除不属于X中的元素。为什么这样做呢?因为注定不是最小了。所以对Cplus进行修剪,去掉没有希望的B,以及去掉已经实现愿望的A。
但是,如果对于所有属于X与C+(X)交集的A,X\A->A均不成立,那就有希望啊。但为什么一定是在键剪枝的时候才会成立呢?(不懂)

4.4. 修剪格子
下面是TANE算法的修剪格子过程:剪掉不满足条件的属性集X

步骤梳理
- 第1、2、3行体现的关于右方集的剪枝策略
- 第4-8行体现的是关于键的剪枝策略
- 由下文的引理4.2,假设X是一个超键,则函数依赖X\{A}->A是成立且是最小的,当且仅当X \ {A}是键且对所有B∈X, A∈C+(X \ {B})。由些可知,第7行的输出是正确的。
该过程修剪实现了第3节中描述的两个修剪规则。
①RHS+剪枝
②键值剪枝
RHS+修剪
根据第一个规则,如果C+(X)=∅,则会删除X;根据第二条规则,如果X是一个键,则会删除X。在后一种情况下,该算法也可能输出一些依赖关系。我们将证明剪枝不会导致算法错过任何依赖关系。
让我们首先考虑用空的C+(X)进行修剪。
如果C+(X)=∅,则计算函数依赖 compute_dependencies过程中第4-8行的循环计算依赖关系,和该修剪过程中第5-7行的循环将根本不会执行,即不会有新的FD输出。由于C+(Y)=∅也适用于所有的Y⊃X,删除X将对算法的输出没有影响。
现在让我们考虑修剪键。修剪的正确性基于以下引理。
键修剪
引理4.2
设X是超键,设A∈X 。依赖项X \ {A}→A是有效且最小的,当且仅当X \ {A}是键且对所有B∈X, A∈C+(X \ {B})时。
如果X为超键,A∈X ,如何确定X\{A}->A是否为最小函数依赖呢?
当且仅当:
X\A->A是有效的(有效性测试):X\A只能是键,X\A->A是才有效的。反之,如果X\A不是键,则X\A->A必然不成立。(有效性测试—非平凡的)
最小性:A不依赖X的真子集,可以等价于
- 所有B∈X,(X\{A,B})->B不成立
- 所有B∈X,所有B∈X, A∈C+(X \ {B})(由cplus定义)
- A不依赖X的真子集(也是由cplus定义可知)
综上,符合引理3.1的内容,即X\A->A是有效的,所有B∈X,所有B∈X, A∈C+(X \ {B}),所以X\A->A是最小的。
注意:引理4.24其实是引理3.12和引理3.45的综合。
由引理4.2引出下面这句关键的话,也是本次对键修剪过程中的核心思路:
引理4.2推论
在修剪prune过程中,依赖X→A在第7行输出◆当且仅当◆如果X是超键,A∈C+ (X)\X 并且对于所有的B∈X而言,A∈C + ((X+A)\ {B})。
当然,对于后半句对于所有的B∈X而言,A∈C + ((X+A)\ {B})可以解释为如下:
A ∈ ⋂ B ∈ X C + ( X ∪ { A } \ { B } ) A \in \bigcap_{B \in X} \mathcal{C}^{+}(X \cup\{A\} \backslash\{B\}) A∈B∈X⋂C+(X∪{A}\{B})
Question:这句话如何解释?A∈C+ (X)\X 是啥意思?如何与引理4.2扯上关系。
Answer:进行到prune这一步时,C+(X)内属于X的属性均已经考虑过(并且均不成立,如果成立的话C+ (X)\X 就是空了),因此需要考虑不属于X的属性,即C+ (X)\X,那么,既然X是超键,则X+A也是超键,(X+A)相当于引理4.24中的((X))那么X相当于引理4.2中的((X\A)),B与4.2中B相同,(显然这里B!=A),因此((X \ {A}))→A为最小,即X->A为最小!
引理4.2表明,这种依赖是有效的和最小的。引理还表明,如果最小依赖项X \ {A}→A(这里A不一定∈X)由于pruning(准确的说应该是忽略了Cplus\X)而没有在计算依赖过程compute_dependencies中输出,那么它将在剪枝过程prune中输出。因此,修剪工作是正确的。
4.5. 计算分区
上面的算法不包含对分区的引用。然而,在计算依赖关系过程的第5行上实现中心测试需要知道e(X)和e(X \ {A})。同时,对剪枝过程第4行进行的超键测试也是基于e(X)。
e(X)定义为需要从关系r中移除的元组最小分数,以使X成为超键。如果e(X)很小,则X为近似超键。
在TANE中,这些值通过公式(1)计算,这也是这一节的意义所在,也就是实现依赖性测试以及超键测试。
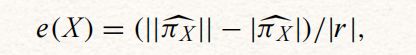
从剥离分区中计算,分区的计算如下:
一开始,直接从关系r针对单例属性集计算分区。从列r[A]计算分区π{A},如下所示。
什么是单例属性集:意思应该是属性X为单个
首先,将列的值替换为整数1、2、3、…使等价关系不变,即用相同的整数代替相同的值,用不同的整数代替不同的值。这可以在线性时间内完成,使用trie或哈希表等数据结构将原始值映射到整数。至此,值t[A]就是π{A}的等价类[t]{A}的标识符,并且π{A}易于构造。
问题:这一步的意义在哪?用整数代替原来的值----可能是方便计算剥离分区的乘积
最后,将π{A}中的单例等价类剥离,形成剥离分区 π A ^ \widehat{\pi_{{A}}} πA 。
当在生成级别过程的第6行中将X添加到其级别时,将计算关于更大属性集X的分区。其中集合X为Y∪Z, π x为πY与πZ的乘积。
在线性时间内,用下列方法计算分区πY与分区πZ的乘积。
似乎不重要,没有读这部分的代码

4.6. 近似依赖
对于给定的阈值ε,可以修改TANE算法以计算e(X → A) ≤ ε的所有最小近似依赖关系X → A。关键的修改是将“计算依赖”程序第5行的有效性测试改为:
改之前:
![]()
改之后:

此外,剪枝不得不稍微减弱(降低要求),通过将第8行的“计算依赖”程序:
改之前:
![]()
改之后:
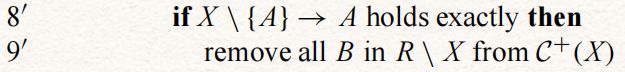
上述算法只返回最小的近似依赖关系。在某些应用程序中,了解不是最小但误差较小的近似依赖关系可能也很有用。我们把必要的修改留给读者去做。
TANE试图通过使用边界条件(2)来解决第5行的测试。对于①,误差超过阈值,近似不成立;对于②,误差在阈值范围内,近似成立
如果失败,则使用以下过程从分区计算e的确切值e(X\{A} → A)。

请注意与“剥离乘积”程序的相似之处。在这里,表T必须一次全部初始化为0,但之后不需要重新初始化。
五、TANE理解
5.1. 高效性
TANE 基于根据属性值对行集进行分区,这使得即使对于大量元组也能快速测试函数依赖的有效性。分区的使用还使得近似函数依赖的发现变得容易和高效,并且可以轻松识别错误或异常行。
5.2. 正确性
如何保证不会丢失任何依赖关系?
计算函数依赖
因为:Cplus中存储了所有可能依赖X的属性,我们考虑的函数依赖仅仅是A∈X,X\{A}->A为最小,故只需要对所有属于 X ∩ C p l u s X∩Cplus X∩Cplus的元素A逐一判断,若X->A成立,则X->A为最小函数依赖。这样不会错过在属性集X上的非平凡&最小函数依赖。
注意:compute_dependencies过程中,输出的FinalFD为X\{A}->A,其中A∈X
剪枝过程
剪枝过程主要目的是修剪当前层的属性集X,将X去掉。去掉是因为其超集一定不会产生最小函数依赖,可以节省时间!注意调用prune之前,Li层仅由上一层生成,调用之后,Li被修剪,这样继续生成下一层时候,就不用生成太多了,也会节省一部分时间。
(a)右方集剪枝
若Cplus(X)=φ,则删除X----X无用,剪掉是为了不再考虑超集
(b)键剪枝
注意:prune过程(准确的说是键剪枝)中,输出的FinalFD为X->A,【A∈C+ (X)\X 并且对于所有的B∈X而言,A∈C + ((X+A)\ {B})】
Question1 :为何prune过程中要输出函数依赖,compute_dependencies过程没有输出完吗?
Answer:如果最小依赖项X \ {A}→A(这里A不一定∈X)由于没有考虑Cplus\X的部分,而没有在计算依赖过程compute_dependencies中输出,仅仅考虑了Cplus中属于X的那些属性A,那么它将在剪枝过程prune中输出。
Question2 prune输出FinallistFD的合理性
Answer:引理4.2及引理4.2推论
Question3 考虑Cplus\X时,为何确保X为(超)键呢,如果不是,Cplus\X找不出A吗
(不清楚,脑子不够用了qaq)
5.3. 合理性
针对算法中,分区计算、生成级别等部分,理解代码运行的机理。
六、总结
我们提出了一个新的算法,TANE,用于发现函数和近似依赖关系。该方法基于考虑关系的分区,并从分区中导出有效的依赖关系。该算法以广度优先或水平优先的方式搜索依赖性。我们展示了如何有效地修剪搜索空间,以及如何有效地计算分区和依赖关系。实验结果和比较表明,该算法在实际应用中速度较快,其放大性能优于以往的方法。该方法适用于多达几十万个元组的关系
当依赖关系相对较小时,该方法处于最佳状态。当(最小)依赖的大小大约是属性数量的一半时,依赖的数量是属性数量的指数,这种情况对任何算法来说或多或少都是不好的。当依赖性大于这个值时,从小的依赖性开始搜索的水平方向方法显然离最优值更远。原则上,水平搜索可以从大的依赖关系开始。然而,分区不能被有效地计算。
还有其他有趣的分区数据挖掘应用程序。属性-值对之间的关联规则可以通过对当前算法的小修改来计算。等价类则对应于属性集的特定值组合。通过比较等价类而不是全分区,可以找到关联规则。一个可能的未来研究方向是使用分区为函数依赖和关联规则提供的统一视图,以找到两者的适当推广,并开发发现这种规则的算法。
注:下文中所说的依赖均为非平凡函数依赖,A依赖X,即X\A->A成立。 ↩︎
引理3.1 设A∈X,且X\{A}->A为有效函数依赖,当且仅当对于all B ∈X,我们有A∈C+(X\{B})时,X\{A}->A为最小函数依赖。 ↩︎ ↩︎ ↩︎
引理3.5 一个函数依赖X→A成立当且仅当e(X)= e(Xn{ A })。 ↩︎
设X是超键,设A∈X 。依赖项X \ {A}→A是有效且最小的,当且仅当X \ {A}是键且对所有B∈X, A∈C+(X \ {B})时。 ↩︎ ↩︎
引理3.4 设B∈X,且X \ {B}→B为有效依赖项。如果X是一个超键,那么X \ {B}是一个超键-。 ↩︎