PYInfer: Deep Learning Semantic Type Inference for Python Variables Python类型推断
Abstract
在本文中,提出了端到端的PYInfer,基于深度学习的类型推断工具,可自动生成Python变量的类型注释。推断变量类型时上下文代码语义非常重要。对于每一个变量的使用,在它的上下文范围内收集一些tokens,然后设计神经网络预测变量类型。由于很难去收集高质量的人工标定的数据集,采用已有的静态分析工具对源码中的变量生产ground truth.
将类型推断作为一个分类问题,PyInfer能处理用户自定义类型以及为每个变量推断类型概率。
Introduction
变量类型不一致是动态语言中常见的错误,由于Python的动态属性,解释器无法和静态编程语言编译器一样去检查类型的不一致性,Python的类型检查器利用注释检查类型的一致性。这些工具都需要使用开发者手动写入的类型注释,这个其实很难提供。
为方便用户编程和检查类型错误,变量类型推断是一个必要的步骤。深度学习已经应用到使用TypeScript进行JavaScript的类型推断,从而产生包含大量精确注释的语料库。Python和JavaScript数据集的质量相差较多。
应用静态分析或动态分析的类型推断工具分析时不需要对其进行标记注释类型推断。然而,它们是不精确的,并且忽略了源代码中丰富的自然语言语义。
本篇论文提出PyInfer,对Python变量类型进行推断,因为人工标定的变量数据集不可用,因此采用PySonar2对Python GitHub项目自动产生初始类型注释,然后我们使用一系列的数据清洗技术改进数据集的质量,我们进一步提供注释和上下文信息用来训练深层神经网络的信息,它有效地为每种类型的概率排序。

注释数据集的收集
分析变量类型的源码上下文语义需要大量标注的数据集,我们使用PySonar2生成的包含大量数据类型结果的数据集并使用数据清洗技术提高数据集的质量。
用户自定义类型
由于Python的灵活性,类型可以是用户自定义的并且可以在运行时改变,我们把Python的类型推断作为一个分类任务,在500多个普通类型中覆盖了用户自定义类型。作为一个分类任务,我们的模型为每一个类型提供了置信度。
源码嵌入
源码中包含了大量的变量名和变量使用的语义信息和类型信息,这对类型推断很有帮助。之前的工作使用了word embedding(词嵌入),这些嵌入方式可能会产生OOV问题(超出词表问题),为了解决这个问题,我们使用了BPE算法(字节对编码算法).
上下文代码语义
我们的方法的一个主要观点就是为变量类型推断使用上下文代码语义。我们假设在一个确定的上下文margin内有相关的语义信息来描述变量,我们的方法能够分析变量的语义以及结构语法和语法信息。margin的设置如图所示

对于每一个变量,在它的上下文范围内收集它的源码序列,采用基于attention mechanism(注意力机制)的GRU(门神经网络)分析上下文语义。
把以上集成到一起,我们发明了一个端到端的,高质量的,高效的框架静态推断Python的变量类型。我们的框架还可以扩展到function argument推断,因为我们的方法是基于语义而不是图结构,它可以很容易扩展到其他动态类型语言的变量注释以及检测语义错误。
PyInfer框架
PyInfer模型框架示意图:

把类型推断看作一个分类问题,我们测试了基于出现频率排名的前500种类型,并在一个确定的范围内分析了上下文语义,BPE算法用来获取向量表示,进而使用这些向量嵌入到基于注意力机制的门神经网络中,从上下文中抽取代码语义。然后使用softmax层为每种类型进行概率分类。PyInfer包含四个组件:数据收集与生成,源码嵌入,设计模型,训练模型
A:数据收集与生成
为了将变量类型分类,我们需要一个足够大的标注了类型的数据集。人工标注不可取,使用PySonar2产生初始类型注释,因为PySonar2的分析比较保守,我们忽略了所有不能进行类型推断的变量,并假设剩下的变量的结果就是ground truth,我们也分析了typeshed,probPY和TypeWriter数据集。
表I展示了数据集 Original和Valid表示了在数据清洗及去重之前和之后的数量,typePY是从4577个Github库中收集的源码数据集,probPY是Xu et al工作中提到的数据集,typeshed是人工标定的数据集,只包含了function参数和return values的注释。
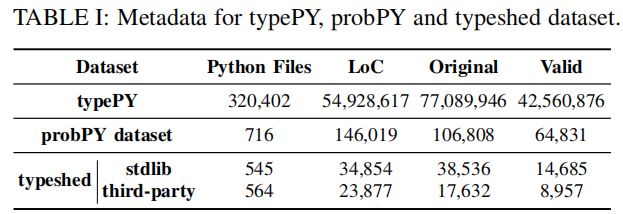
我们通过注释top-star的github仓库的Python源码收集typePy,对每一个变量,我们保存它的仓库链接,文件名,变量名,开始和结束的token位置,类型注释以及相关源码。为了获得类型注释,我们采用PySonar2推断每个变量类型。收集数据之后进行数据清洗,消除所有无意义的类型,比如”question mark“,和”None“类型,并且去重。最终获取到42560876种有效注释。
对于probPY数据集,我们利用PySonar2的结果和动态分析相结合的数据,propPY数据集提供了变量名,注释和源码来生成适用于我们的模型的上下文信息。
typeshed数据集包含对Python标准库和第三方包的人工标定的类型注释,然而它只包含function parameters和返回值类型的注释,并且因为频繁的代码更新而没有上下文信息,我们提取参数的注释去评估我们的模型的上下文代码语义的重要性,在合并第三方库和标准库的注释时,对【变量名,类型注释】pairs去重
B:源码嵌入
传统的嵌入方法是对频繁使用的tokens建立一个字典,对词表中的每个token生成嵌入表示,这种方法保证了输入到模型时,每个token都保持完整。许多已经存在的方法,如对word进行表示的Word2Vec和Global Vectors(GloVe),为每个token计算向量表示。然而,词嵌入(word embedding)方法并不适合源码,因为有大量的用户定义的变量名和function名,这些方法会出现超出词表问题,训练数据观察不到的一些稀有词,OOV问题使得模型不能获取到词表之外的token信息,一种方法是使用<UNK>表示未知词,但这样不合适,会丢失语义信息。
为了获取变量和函数名的语义,使用BPE算法生成源码嵌入。BPE算法是以压缩算法得名并在很多使用神经网络的程序分析中很有效,这个算法通过合并最经常出现的字节对成为一个新的字节来解决OOV问题。以一个单个字符开始,我们把用户自定义tokens分割成小块放入字典中,采用自下而上的聚类方法,初步生成所有字符的单字符,然后迭代计算字符出现的频率,然后使用一种贪婪近似法最大化模型的似然估计,从而为最频繁出现的字节对生成新的字节。
我们在源码语料库上训练BPE模型,并得到了19,995个不同的base word,和传统的嵌入方法比较,BPE嵌入充分利用了上下文代码语义。使用蛇形命名法和驼峰命名法的变量名可使用BPE有效嵌入。
C:设计模型
这个工作的一个主要亮点是把上下文信息带入模型中。源码中的上下文不仅携带了有意义的语义信息,还传达一些变量功能性的信息。我们设置范围m来表示有多少上下文信息应该被考虑,对于每一个变量![]() ,i ∈ [1..n],我们把当前变量所在的处理为当前行,标记为
,i ∈ [1..n],我们把当前变量所在的处理为当前行,标记为![]() ,在当前行之前有m个tokens,标记为
,在当前行之前有m个tokens,标记为![]() ,当前行之后的m个tokens,标记为
,当前行之后的m个tokens,标记为![]() ,当前变量名记作
,当前变量名记作![]() ,上下文信息提供了变量的局部语义,这已经足够对变量类型进行推断,BPE算法为
,上下文信息提供了变量的局部语义,这已经足够对变量类型进行推断,BPE算法为![]() ,最终变量
,最终变量![]() 的嵌入向量
的嵌入向量![]() 为
为![]()
我们特意在嵌入的最后一部分设置了变量名,这个设置能使我们通过在GRU网络的抽取最后一层的模式来获取语义表示。为了更清晰地表示向量特征,我们采用门控循环单元(GRU)---一个循环神经网络,和双向循环神经网络有相似性能但具有更低的计算复杂度,对于每一个变量,GRU结合变量名分析上下文信息的特征,它能够每t步时使用递推公式处理向量序列。最初,当t=0时有一个输出向量![]() ,假设嵌入之后的变量
,假设嵌入之后的变量![]() 的tokens数量为
的tokens数量为![]() ,每一个输入源码token
,每一个输入源码token![]() ,在嵌入向量
,在嵌入向量![]() 中
中![]() ,则
,则
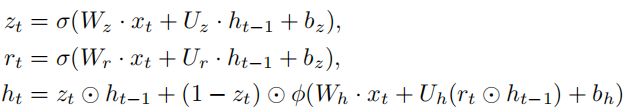
![]() 是带有上下文信息的输入嵌入向量,
是带有上下文信息的输入嵌入向量,![]() 是变量
是变量![]() 的输出向量,
的输出向量,![]() 是更新门,
是更新门,![]() 是重置门,W,U,b是模型中的参数,
是重置门,W,U,b是模型中的参数,![]() 代表激活函数(sigmoid函数),
代表激活函数(sigmoid函数),![]() 代表双曲正切函数,为了使模型具有更好的表现力,还加入了注意力机制。因为变量名加入到了嵌入向量的最后一个位置,我们可以在输出向量
代表双曲正切函数,为了使模型具有更好的表现力,还加入了注意力机制。因为变量名加入到了嵌入向量的最后一个位置,我们可以在输出向量![]() 抽取最后一层来描述变量
抽取最后一层来描述变量![]() ,向GRU中添加dropout层(dropout layer),这个设计是为了解决过度拟合的问题(Dropout技术是通过随机减少神经网络中相互连接的神经元的数量来实现的。在每一个训练步骤中,每个神经元都有可能被排除在外(从连接的神经元中被剔除)。在某种意义上,层内的神经元学习的权重值不是基于其相邻神经元的协作)。最后我们对GRU的输出添加一个全连接层(fully connected layer)增加模型学习上下文语义的灵活性。
,向GRU中添加dropout层(dropout layer),这个设计是为了解决过度拟合的问题(Dropout技术是通过随机减少神经网络中相互连接的神经元的数量来实现的。在每一个训练步骤中,每个神经元都有可能被排除在外(从连接的神经元中被剔除)。在某种意义上,层内的神经元学习的权重值不是基于其相邻神经元的协作)。最后我们对GRU的输出添加一个全连接层(fully connected layer)增加模型学习上下文语义的灵活性。
我们把Python类型推断作为一个分类问题解决用户自定义类型,为了获取每一个类型的概率,我们在GRU模型的输出中所提取的特征上使用softmax回归函数。对于GRU神经网络的输出![]() ,
,
argmax是返回最大概率位置的函数,![]() 是每一个变量
是每一个变量![]() 的每一种可能类型的概率集合,这个函数用来近似一个目标整数
的每一种可能类型的概率集合,这个函数用来近似一个目标整数![]() ,
,![]() 代表类别数量,softmax函数
代表类别数量,softmax函数![]()
产生一个带有每种类型的概率![]() 的标量输出
的标量输出 ![]() 。
。
有了softmax层,我们可以生成每个变量的带有类型分布概率![]() 的类型注释。PyInfer基于具有最大概率的类型来注释变量类型,返回的是
的类型注释。PyInfer基于具有最大概率的类型来注释变量类型,返回的是![]() ,我们能够对置信度添加一个阈值,随着置信度的增加,模型的精确度也会随之增加。
,我们能够对置信度添加一个阈值,随着置信度的增加,模型的精确度也会随之增加。
D:训练模型
此模型中,采用交叉熵作为损失函数,使用对数softmax(前文提到的P())函数推导类型推断的置信度,在softmax结果上添加最大似然代价函数(NLLLoss),因此,损失函数为
![]() 代表模型的损失函数,通过计算每种类型注释损失的叠加,常量n是注释的数量,
代表模型的损失函数,通过计算每种类型注释损失的叠加,常量n是注释的数量,![]() 代表分类数量,变量
代表分类数量,变量![]() 的ground truth 类型由
的ground truth 类型由![]() 表示,当变量
表示,当变量![]() 的注释为
的注释为![]() 时,设置
时,设置![]() = 1,否则,
= 1,否则,![]() = 0。
= 0。![]() 定义了变量
定义了变量![]() 的所属类别
的所属类别![]() 的对数softmax结果。
的对数softmax结果。
EVALUATION
这一部分,我们通过以下几个问题评估PyInfer
RQ 3: 阈值是如何影响PyInfer模型的?
RQ 1:模型有效性及baseline比较
1)数据集及实验配置
分析typePy数据集中500个常用类型,除了所有python中的内置类型,也考虑了大量的用户自定义类型,整体的数据语料库按60%,20%,20%的比例随机分成训练数据,验证数据以及测试数据。
所有实验都在
2)实现细节和结果
我们以下表中的参数训练模型得出测试结果
为了分析上下文语义信息,我们通过分析源码中每一部分带有margion进行分割的上下文语义,通过抽取以变量名作为最后一部分的GRU神经网络的最后一层获取向量表示。
我们添加了一个dropout层来解决过拟合问题。上表中参数![]() 和
和![]() 代表了GRU神经网络隐藏层(把输入数据的特征,抽象到另一个维度空间)的大小,设置超参
代表了GRU神经网络隐藏层(把输入数据的特征,抽象到另一个维度空间)的大小,设置超参![]() 消除一些特别长的嵌入,这通常是一段源代码包含大量看不见的token的情况。我们也收集了嵌入长度的分布,数据集中99.9%的注释的嵌入长度在1000以内,因此我们可以采用有长度限制的注释来训练模型。
消除一些特别长的嵌入,这通常是一段源代码包含大量看不见的token的情况。我们也收集了嵌入长度的分布,数据集中99.9%的注释的嵌入长度在1000以内,因此我们可以采用有长度限制的注释来训练模型。
使用上述所有设置,我们微调参数和将准确性用作我们模型的评估矩阵之一。精确度计算为:
![]() 代表当前待处理的嵌入,
代表当前待处理的嵌入,![]() 代表变量
代表变量![]() 的ground truth类型,
的ground truth类型,![]() 返回概率最大的注释。我们的模型最终在测试数据上有81.195%的精确度。
返回概率最大的注释。我们的模型最终在测试数据上有81.195%的精确度。
因为每一种类型的分布是不均匀的,我们也使用加权精度和召回率评估我们的模型,以及根据它们计算f-1分数。
3)Baseline Analysis and Insights
4)和TypeWriter比较
TypeWriter使用神经网络从包含部分已经注释的代码库中有效地推断function级别的类型,参数类型和返回值类型,它在源码的参数名,参数使用,function级别的comments的tokens的类型信息上使用LSTM.对于数据集,TypeWriter和Github上的mypy依赖一样使用内部代码库,它处理了1137个Github库,预测了16492个返回值类型注释和21215个参数类型注释。
和TypeWriter相比,我们的目标略有不同并且应用了不同的框架。TypeWriter推断函数参数类型及返回值类型,然而PyInfer针对Python变量。在方法层,TypeWriter采用传统的Word2Vec嵌入,然而PyInfer采用BPE嵌入获取上下文代码语义。关于神经网络的设计,TypeWriter在源码的tokens和function comments上使用LSTM模型,而PyInfer使用基于注意力机制的GRU神经网络来解决局部语义问题。
我们的工作和TypeWriter是互补的。TypeWriter采用全局的function级别的特征,function源码,注释,和参数使用去推断返回值和参数类型。这些全局特征对完整的function提供了一个全面的视角,从而更容易推断function级别的类型。TypeWriter相比于NL2Type和DeepTyper对于参数的类型预测性能有所提升,但是很难推断function内部的变量类型,而这些变量级别的信息是非常有效的。而PyInfer使用包含确定范围的源码语义提供变量级别的注释更有竞争力。主要的原因是PyInfer模型利用了局部的变量级别的特征,即特定范围内的变量名和上下文语义。对于变量和参数的类型推断,局部特征更重要,因为它们表明了变量是如何定义及使用的。
RQ 2:基本类型或更多类型
经观察,Python内置类型:[str, int, dict, bool, flfloat, list, tuple, object, complex, set, type]
对这11种类型进行分类会更易于管理,比500种更精确,但是很多用户自定义类型无法被预测到,考虑了500种类型的模型覆盖了大多数的用户自定义类型,使其可泛化为实际场景。
RQ 3:阈值
因为模型提供了带有概率的类型注释,因此在置信度上测试不同的阈值。从0.1到0.9,我们提供了注释数量,准确率和召回率,f-1 score。可以将阈值设置为合理值,以实现我们想要获得的注释数量和所希望拥有的准确性之间的平衡。
ANALYSIS
这一部分,有以下两个问题
RQ 5:BPE嵌入比其他基于学习的嵌入突出吗?
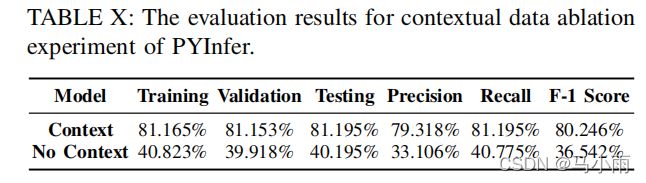
RQ 4: 上下文语义的消融分析
对上下文数据进行消融实验,研究没有上下文语义的PyInfer。没有上下文的特征,我们的模型只能利用变量名,省略变量的使用及上下文的逻辑关系,上下文信息在表征源码语义中起着关键作用。结果如表所示,效果差。
为了更近一步的研究上下文语义重要性,对人工标定的typeshed数据集进行实验,一个特定格式的pyi文件中包含着类型信息,这广泛用于类型检查和类型推断中。一个pyi文件中包含函数参数和返回值的类型注释。如下图,为变量safe提供了_Str和AnyStr两种类型,因为没有上下文语义,不能确定具体的类型。

RQ 5: 源码嵌入的优势
除了上下文信息和类型,我们的模型采用BPE嵌入也有优势。源码中包含大量用户自定义变量和function名,BPE算法充分利用上下文语义信息解决OOV问题。
DISCUSSION
A:PyInfer的优势和劣势
PyInfer比其他类型推断工具突出的原因主要是我们拥有足够大的已经标注了类型的数据集,并且把变量的上下文语义信息编码到了深度学习模型中。margin的设置会影响PyInfer的表现。
PyInfer也有一些限制。尽管PyInfer能够处理用户自定义类型,但是和内置类型对比,因为有限的用户自定义类型的训练数据导致一些推断结果是不正确的。和许多静态分析器一样,PyInfer要求访问源码,这有时候可能因为机密问题而不太现实。
B:与PySonar2相比的优势
RELATED WORK
A:Python类型推断
B:动态类型语言的类型推断
已存在的基于学习的类型推断的工具主要是针对JavaScript的,它的类型信息可以通过TypeScript获得。LambdaNet使用图神经网络预测类型,其中包含涉及上下文提示的命名和变量使用。它定义了类型依赖关系图并在图神经上传播类型信息。LambdaNet 探索使用图神经网络嵌入进行类型推断的潜力。和图嵌入相比,生成基于token的源码更高效。它可以利用源代码语义以及更容易应用于其他语言。NL2Type提出基于学习的方法预测有自然语言支持的function的类型特征。.Hellendoorn等人的工作中使用300个维度的词嵌入的深度学习模型推断JavaScript类型。
C:基于学习的源码分析
C:基于学习的源码嵌入
基于token的源码嵌入:word2vec,doc2vec,BPE
基于图嵌入:Code2Vec,基于路径的表示,类型依赖图。这些嵌入首先考虑源码结构,
hehe