极端气候?自然灾害?【实战】机器学习预测森林火灾

作者:韩信子@ShowMeAI
机器学习实战系列:https://www.showmeai.tech/tutorials/41
本文地址:https://www.showmeai.tech/article-detail/326
声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容
2022依旧是极度不平凡的一年,全球事件频发,动荡不安。而且在全球气候上,极端天气愈发明显,全球变暖的加剧增加了热浪、干旱和野火等气候相关灾害的可能性。在全球来看,西班牙等国的高温连破纪录并引发森林火灾。而8月9日以来,我国也出现罕见的极端高温天气,连创新高,部分地区如重庆市北碚、巴南、大足、长寿、江津等地先后发生多起森林火灾。
野火是一种不可预测的、无计划的、不受控制的火灾,可能由营火(篝火)、燃烟和纵火、烟花、射击、爆炸目标或闪电等自然现象引起,而在原本极端高温的天气下,更易发难控。
在本篇内容中,ShowMeAI带大家看看机器学习如何预测森林火灾,本文采用的数据集为 NASA 的森林火灾信息数据集。

数据收集
本篇内容的数据源来自 NASA 的资源管理系统火灾信息 (FIRMS) 卫星数据和 NASA 的 MODIS(中分辨率成像光谱仪)仪器对 2021年印度森林野火案例的纪录。数据集可以在ShowMeAI的百度网盘地址直接获取。
实战数据集下载(百度网盘):公众号『ShowMeAI研究中心』回复『实战』,或者点击 这里 获取本文 [25]基于机器学习的AI森林火灾预测 『2021年印度森林火灾数据集』
⭐ ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub
# 数据理解

下面内容会涉及数据分析处理的技能,欢迎大家查阅ShowMeAI对应的教程和工具速查表,快学快用。
- 图解数据分析:从入门到精通系列教程
- 数据科学工具库速查表 | Pandas 速查表
- 数据科学工具库速查表 | Seaborn 速查表
我们先导入 NumPy 和 Pandas 并读取森林火灾的 MODIS 数据集
# 处理警告信息
import warnings
warnings.filterwarnings('ignore')
# 导入工具库
import numpy as np
import pandas as pd
df = pd.read_csv("modis_2021_India.csv")
# 查看数据
df.head()
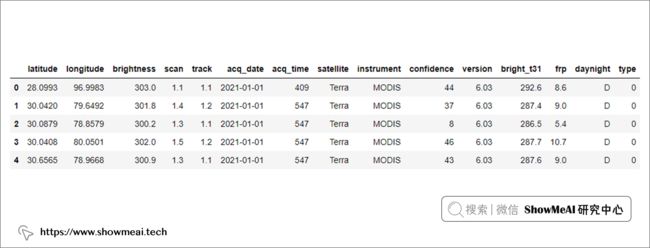
数据集特征字段解释
latitude= 纬度longitude= 经度brightness= 以开尔文测量的像素的明亮度scan= 扫描像素大小track= 轨道像素大小acq_date= 获取日期acq_time= 采集时间satellite= Acua 和 Terra 卫星作为 A 和 Tinstrument= MODISconfidence= 火灾概率,0-100之间(表示0-100%)version= 版本标识收集和数据处理源bright_t31= 通道 31 的火焰亮度温度,以开尔文为单位测量frp=以兆瓦为单位的火辐射功率daynight= D 和 N 作为白天和黑夜type= 0 作为假定植被,1 作为活火山,2 作为静态陆源 3 作为近海探测
我们把confidence视作目标变量。
# 查看数据维度
df.shape
##(111267, 15)
# 数据信息
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 111267 entries, 0 to 111266
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 latitude 111267 non-null float64
1 longitude 111267 non-null float64
2 brightness 111267 non-null float64
3 scan 111267 non-null float64
4 track 111267 non-null float64
5 acq_date 111267 non-null object
6 acq_time 111267 non-null int64
7 satellite 111267 non-null object
8 instrument 111267 non-null object
9 confidence 111267 non-null int64
10 version 111267 non-null float64
11 bright_t31 111267 non-null float64
12 frp 111267 non-null float64
13 daynight 111267 non-null object
14 type 111267 non-null int64
dtypes: float64(8), int64(3), object(4)
memory usage: 12.7+ MB
# 数据字段
df.columns
Index(['latitude', 'longitude', 'brightness', 'scan', 'track', 'acq_date',
'acq_time', 'satellite', 'instrument', 'confidence', 'version',
'bright_t31', 'frp', 'daynight', 'type'],
dtype='object')
# 数据缺失值情况
df.isnull().sum()
latitude 0
longitude 0
brightness 0
scan 0
track 0
acq_date 0
acq_time 0
satellite 0
instrument 0
confidence 0
version 0
bright_t31 0
frp 0
daynight 0
type 0
dtype: int64
# 数据统计描述
df.describe()

数据探索
# 连续值字段分布分析
我们对数据进行分析,并进行可视化,这里主要使用到 Matplotlib 和 Seaborn 工具库。
import matplotlib.pyplot as plt
import seaborn as sns
我们先对数值型数据进行分布分析,这里最直接的方法是对整个数据集使用 pairplot,它会在对角线位置对每个数值维度进行分布分析,在其他位置对两两特征对进行联合绘图。
sns.pairplot(df)
plt.show()

# 类别型字段分布分析
我们的数据集中还有一些类别型字段变量,我们为其中一些变量绘制箱线图查看数据分布特性。
plt.figure(figsize=(20, 12))
plt.subplot(2,2,1)
sns.boxplot(x = 'satellite', y = 'confidence', data = df)
plt.subplot(2,2,2)
sns.boxplot(x = 'daynight', y = 'confidence', data = df)
<AxesSubplot:xlabel='daynight', ylabel='confidence'>

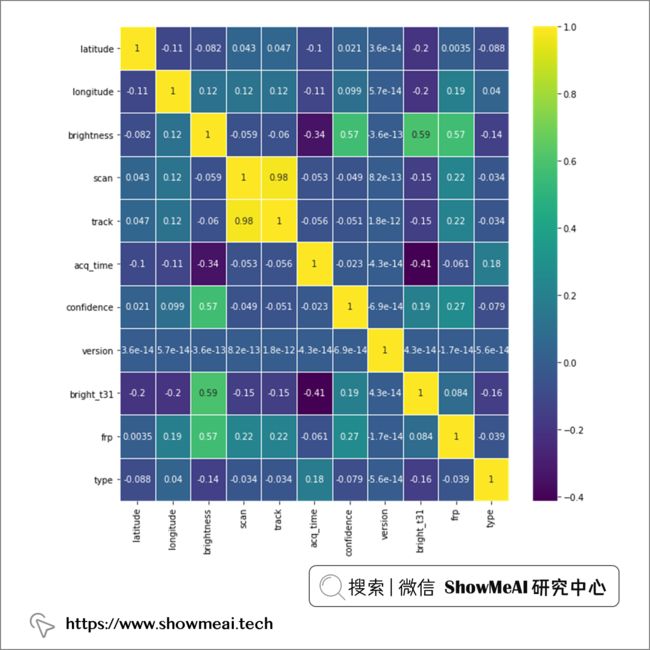
我们可以借助pandas的相关性计算和热力图呈现,对数据进行相关性分析(尤其是对于我们了解目标变量和特征的相关关系有帮助),如下:
plt.figure(figsize=(10, 10))
sns.heatmap(df.corr(),annot=True,cmap='viridis',linewidths=.5)
<AxesSubplot:>
sns.barplot(x='acq_date',y='frp',data=df)
<AxesSubplot:xlabel='acq_date', ylabel='frp'>

# 排序
df_topaffected=df.sort_values(by='frp',ascending=False)
df_topaffected.head(10)

数据清洗&处理
原始世界有各式各样的数据形态,包括文本、视频、图像等非结构化数据,也有包含各种缺失值、错误值等结构化数据。 在实际送给模型训练之前,我们会做一些数据清洗来提升数据的质量,具体的操作包括缺失值填充,清洗不相关的数据,对数据做幅度缩放与归一化等。
关于机器学习的数据预处理与清洗等,属于特征工程范畴,大家可以参考 ShowMeAI 整理的特征工程解读教程。
- 机器学习实战 | 机器学习特征工程全面解读
df = df.drop(['track'], axis = 1)
df = df.drop(['instrument', 'version'], axis = 1)
df['satellite'] = df['satellite'].map({'Terra':0,'Aqua':1})
df['daynight'] = df['daynight'].map({'D':0,'N':1})
df['month'] = df['acq_date'].apply(lambda x:int(x.split('-')[1]))
df = df.sample(frac=0.2)
df = df.reset_index().drop("index", axis=1)
df.head()

df.shape
#(22253, 13)
# 目标字段 & 特征字段
y = df['confidence']
firedf = df.drop(['confidence', 'acq_date'], axis = 1)
# 相关性
plt.figure(figsize=(10, 10))
sns.heatmap(firedf.corr(),annot=True,cmap='viridis',linewidths=.5)
<AxesSubplot:>

# 特征字段
firedf.head()
数据拆分
为了进行有效的建模和模型评估,我们将数据集分为训练集(70%的数据)和测试集(30%的数据)。
X = df[['latitude','longitude','month','brightness','scan','acq_time','bright_t31','daynight']]
y = df['frp']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
评估指标
我们以confidence为目标标签,有不同的建模方法,最直接的方式是把它视作连续值进行拟合预测。整个问题是一个回归建模问题,我们有如下的一些评估指标可以使用。
# 均方误差 (MSE)
MSE 可以从数据集的实际值和预测值的平均平方差进行数学计算

# 平均绝对误差 (MAE)
平均绝对误差可以在数学上计算为从数据预测的值与实际值的平均差

# 均方根误差 (RMSE)
数学上 RMSE 可以计算为预测值与数据实际值的平均平方差的平方根,或者我们可以说它是 MSE 的平方根值。

# R 平方分数
R 平方分数可以从下面给出的等式计算:

建模与预估
本部分涉及到的模型知识与建模操作方法,参见ShowMeAI以下部分教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
# 梯度提升回归树
我们使用梯度提升回归树 GBDT 来进行拟合, 在 Scikit-Learn 中可以直接调用GradientBoostingRegressor 类。关于 GBDT 的原理可以查看ShowMeAI文章 图解机器学习 | GBDT模型详解
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_absolute_error as mae
from sklearn.metrics import mean_squared_error as mse
from sklearn.metrics import r2_score
model1 = GradientBoostingRegressor(n_estimators = 100, learning_rate=0.1,
max_depth = 10, random_state = 0, loss = 'ls')
model1.fit(X_train, y_train)
y_pred = model1.predict(X_test)
print ('MSE =',mse(y_pred, y_test))
print ('RSME =',np.sqrt(mse(y_pred, y_test)))
print ('MAE =',mae(y_pred, y_test))
print ('R2_score =',r2_score(y_pred, y_test))
print("Performance ofGBR Model R^2 metric {:.5f}".format(model1.score(X_train,y_train)))
print("GBR Accuracy, {:.5f}%".format(model1.score(X_test,y_test)*100))
MSE = 449.63478569897046
RSME = 21.20459350468597
MAE = 3.2932809652939343
R2_score = 0.9227647882671393
Performance ofGBR Model R^2 metric 0.99982
GBR Accuracy, 92.86853%
# 决策树回归器
我们也可以使用决策树回归器进行建模,在 Scikit-Learn 中对应的功能在 DecisionTreeRegressor类中。 关于回归树模型的原理可以查看ShowMeAI文章 图解机器学习 | 回归树模型详解。
from sklearn.tree import DecisionTreeRegressor as dtr
reg = dtr(random_state = 42)
reg.fit(X_train,y_train)
Y_pred = reg.predict(X_test)
print("MSE = ",mse(Y_pred, y_test))
print ('RSME =',np.sqrt(mse(Y_pred, y_test)))
print("MAE =",mae(Y_pred,y_test))
print("R2 score =",r2_score(Y_pred,y_test))
print("Performance of Decision Tree Regressor Model R^2 metric {:.5f}".format(reg.score(X_train,y_train)))
print("Decision Tree Regressor Accuracy, {:.5f}%".format(reg.score(X_test,y_test)*100))
MSE = 362.66616536848414
RSME = 19.043795981066488
MAE = 4.693229478729778
R2 score = 0.9316181035003857
Performance of Decision Tree Regressor Model R^2 metric 1.00000
Decision Tree Regressor Accuracy, 94.24790%
我们借助雷达图来比较GBDT和回归树模型,对比它们在森林火灾预测场景下的效果。
categories = ['Training score', 'Testing score', 'RMSE', 'MAE','r2','_']
Decision_Tree_Regressor = [100,94.24, 19.4,4.69, 0.93,0]
Gradient_Boosting_Regressor = [99.97, 92.86, 21.20,3.29, 0.92,0]
label_loc = np.linspace(start=0, stop=2 * np.pi, num=len(Decision_Tree_Regressor))
plt.figure(figsize=(8, 8))
plt.subplot(polar=True)
plt.plot(label_loc, Decision_Tree_Regressor , label='Decision Tree Regression')
plt.plot(label_loc, Gradient_Boosting_Regressor, label='Gradient Boosting Regressor')
plt.title('Algorithms comparison for MODIS dataset', size=20)
lines, labels = plt.thetagrids(np.degrees(label_loc), labels=categories)
plt.legend()
plt.show()

参考资料
- 图解数据分析:从入门到精通系列教程:https://www.showmeai.tech/tutorials/33
- 数据科学工具库速查表 | Pandas 速查表:https://www.showmeai.tech/article-detail/101
- 数据科学工具库速查表 | Seaborn 速查表:https://www.showmeai.tech/article-detail/105
- 图解机器学习算法:从入门到精通系列教程:https://www.showmeai.tech/tutorials/34
- 图解机器学习 | GBDT模型详解:https://www.showmeai.tech/article-detail/193
- 图解机器学习 | 回归树模型详解:https://www.showmeai.tech/article-detail/192
- 机器学习实战:手把手教你玩转机器学习系列:https://www.showmeai.tech/tutorials/41
- 机器学习实战 | 机器学习特征工程全面解读:https://www.showmeai.tech/article-detail/208)
