【mmdetection系列】mmdetection之evaluate评测
1.configs

还是以yolox为例,配置有一项evaluation。用于配置评估是用什么评价指标评估。
https://github.com/open-mmlab/mmdetection/blob/master/configs/yolox/yolox_s_8x8_300e_coco.py#L151
max_epochs = 300
num_last_epochs = 15
interval = 10
evaluation = dict(
save_best='auto',
# The evaluation interval is 'interval' when running epoch is
# less than ‘max_epochs - num_last_epochs’.
# The evaluation interval is 1 when running epoch is greater than
# or equal to ‘max_epochs - num_last_epochs’.
interval=interval,
dynamic_intervals=[(max_epochs - num_last_epochs, 1)],
metric='bbox')其中这几个参数:
interval:指每多少epoch进行一次评测;
dynamic_intervals:指当运行epoch大于或等于“max_epochs-num_last_epochs”时,评估间隔为1。
metric:表示使用什么作为评价指标。
2.具体实现
主体函数,一般是写在自定义数据集的解析dataset类中的。有的会实现在基类中,还是以yolox这个配置文件中对应的数据集为例CocoDataset:
https://github.com/open-mmlab/mmdetection/blob/master/mmdet/datasets/coco.py#L592
def evaluate(self,
results,
metric='bbox',
logger=None,
jsonfile_prefix=None,
classwise=False,
proposal_nums=(100, 300, 1000),
iou_thrs=None,
metric_items=None):
"""Evaluation in COCO protocol.
Args:
results (list[list | tuple]): Testing results of the dataset.
metric (str | list[str]): Metrics to be evaluated. Options are
'bbox', 'segm', 'proposal', 'proposal_fast'.
logger (logging.Logger | str | None): Logger used for printing
related information during evaluation. Default: None.
jsonfile_prefix (str | None): The prefix of json files. It includes
the file path and the prefix of filename, e.g., "a/b/prefix".
If not specified, a temp file will be created. Default: None.
classwise (bool): Whether to evaluating the AP for each class.
proposal_nums (Sequence[int]): Proposal number used for evaluating
recalls, such as recall@100, recall@1000.
Default: (100, 300, 1000).
iou_thrs (Sequence[float], optional): IoU threshold used for
evaluating recalls/mAPs. If set to a list, the average of all
IoUs will also be computed. If not specified, [0.50, 0.55,
0.60, 0.65, 0.70, 0.75, 0.80, 0.85, 0.90, 0.95] will be used.
Default: None.
metric_items (list[str] | str, optional): Metric items that will
be returned. If not specified, ``['AR@100', 'AR@300',
'AR@1000', 'AR_s@1000', 'AR_m@1000', 'AR_l@1000' ]`` will be
used when ``metric=='proposal'``, ``['mAP', 'mAP_50', 'mAP_75',
'mAP_s', 'mAP_m', 'mAP_l']`` will be used when
``metric=='bbox' or metric=='segm'``.
Returns:
dict[str, float]: COCO style evaluation metric.
"""
metrics = metric if isinstance(metric, list) else [metric]
allowed_metrics = ['bbox', 'segm', 'proposal', 'proposal_fast']
for metric in metrics:
if metric not in allowed_metrics:
raise KeyError(f'metric {metric} is not supported')
coco_gt = self.coco
self.cat_ids = coco_gt.get_cat_ids(cat_names=self.CLASSES)
result_files, tmp_dir = self.format_results(results, jsonfile_prefix)
eval_results = self.evaluate_det_segm(results, result_files, coco_gt,
metrics, logger, classwise,
proposal_nums, iou_thrs,
metric_items)
if tmp_dir is not None:
tmp_dir.cleanup()
return eval_results发现是调用 self.evaluate_det_segm这个函数进行评测,发现其调用的是pycocotools进行测评的。
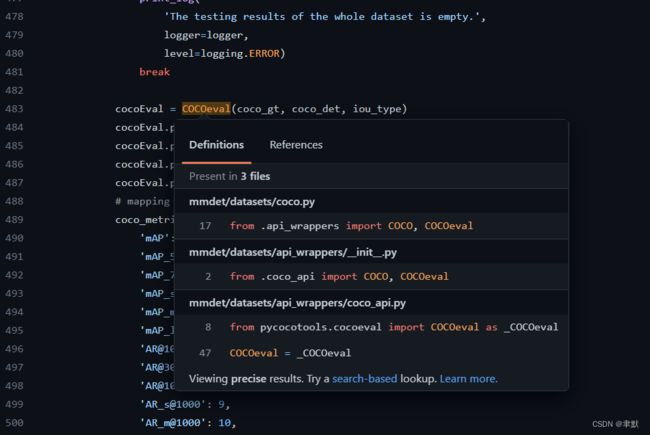
其实除此之外,我们还可以在这里写相应的评测指标:

3.调用
3.1 train.py
主要是在训练时,在评估间隔处进行评测,知道模型好坏。然后可以存性能指标较好的模型,用于后续的应用,也方便进行优化。
训练过程怎么调用evaluation的呢?
(1)训练先调用tools/train.py
https://github.com/open-mmlab/mmdetection/blob/master/tools/train.py#L233
train_detector(
model,
datasets,
cfg,
distributed=distributed,
validate=(not args.no_validate),
timestamp=timestamp,
meta=meta)
(2)该函数会调用mmdet/apis/train.py
https://github.com/open-mmlab/mmdetection/blob/master/mmdet/apis/train.py#L246
from mmcv.runner import (DistSamplerSeedHook, EpochBasedRunner,
Fp16OptimizerHook, OptimizerHook, build_runner,
get_dist_info)
runner = build_runner(
cfg.runner,
default_args=dict(
model=model,
optimizer=optimizer,
work_dir=cfg.work_dir,
logger=logger,
meta=meta))
runner.run(data_loaders, cfg.workflow)(3)看配置文件
https://github.com/open-mmlab/mmdetection/blob/master/configs/_base_/schedules/schedule_1x.py
runner = dict(type='EpochBasedRunner', max_epochs=12)使用的是EpochBasedRunner这个Runner。
(4)通过builder_runner构建
mmcv/builder.py at master · open-mmlab/mmcv · GitHub
def build_runner(cfg: dict, default_args: Optional[dict] = None):
runner_cfg = copy.deepcopy(cfg)
constructor_type = runner_cfg.pop('constructor',
'DefaultRunnerConstructor')
runner_constructor = build_runner_constructor(
dict(
type=constructor_type,
runner_cfg=runner_cfg,
default_args=default_args))
runner = runner_constructor()
return runner(5)调用
https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/epoch_based_runner.py#L136
这里会调用训练或测试,并调用hook。
https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/epoch_based_runner.py#L54
epoch_runner(data_loaders[i], **kwargs)
self.call_hook('after_train_iter')
如果hook中包含EvalHook,就会进行评测:
https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/evaluation.py#L268
def after_train_epoch(self, runner):
"""Called after every training epoch to evaluate the results."""
if self.by_epoch and self._should_evaluate(runner):
self._do_evaluate(runner)
def _do_evaluate(self, runner):
"""perform evaluation and save ckpt."""
results = self.test_fn(runner.model, self.dataloader)
runner.log_buffer.output['eval_iter_num'] = len(self.dataloader)
key_score = self.evaluate(runner, results)
# the key_score may be `None` so it needs to skip the action to save
# the best checkpoint
if self.save_best and key_score:
self._save_ckpt(runner, key_score)
def evaluate(self, runner, results):
"""Evaluate the results.
Args:
runner (:obj:`mmcv.Runner`): The underlined training runner.
results (list): Output results.
"""
eval_res = self.dataloader.dataset.evaluate(
results, logger=runner.logger, **self.eval_kwargs)
for name, val in eval_res.items():
runner.log_buffer.output[name] = val
runner.log_buffer.ready = True
if self.save_best is not None:
# If the performance of model is pool, the `eval_res` may be an
# empty dict and it will raise exception when `self.save_best` is
# not None. More details at
# https://github.com/open-mmlab/mmdetection/issues/6265.
if not eval_res:
warnings.warn(
'Since `eval_res` is an empty dict, the behavior to save '
'the best checkpoint will be skipped in this evaluation.')
return None
if self.key_indicator == 'auto':
# infer from eval_results
self._init_rule(self.rule, list(eval_res.keys())[0])
return eval_res[self.key_indicator]
return None
3.2 test.py
测试时,只需要加上一个参数--val,就可以了。
比如:
python ./tools.test.py ./your_config_file --val