知识图谱表示 | TransE原理简介与代码解读
表示学习-TransE
原理介绍
核心理念
在平面直角坐标系中,向量表示三元组知识 ( h , r , t ) (h,r,t) (h,r,t)。其中 h h h表示的是头实体的向量表示; r r r表示的是关系的向量表示; t t t指代的是尾实体的向量表示,如果三元组 ( h , r , t ) (h,r,t) (h,r,t)在向量空间中满足下图关系:
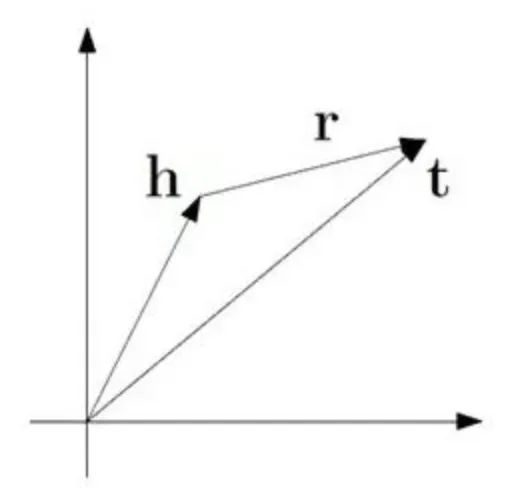
当我们通过如上图的形式表示三元组时,可以从两个方面对已有知识图谱中的知识做处理:
- 使用词向量对知识图谱已经有的三元组进行表示;
- 对可能潜在的三元组关系进行预测,即在使用词向量表示当前知识图谱的基础上,预测潜在的三元组;
主要流程
TransE的主要方法流程为:
知识图谱(KG)中现存的关系构成关系集,实体构成实体集,模型抽取两个集合来构成三元组。
按照 h + r ≈ t h+r\approx t h+r≈t规则做向量运算。
如果近似达到要求,则可以在两个实体间建立联系来补充完善知识图谱,通过这样的方法挖掘、发现实体间的关系,扩大知识网络,实现连接预测。
得分函数
表示学习中,得分函数是比较重要的一部分,TransE的得分函数为:
f ( h , r , t ) = ∣ ∣ h + r − t ∣ ∣ L 1 / L 2 f(h,r,t) = ||h+r-t||_{L1/L2} f(h,r,t)=∣∣h+r−t∣∣L1/L2
代码实现
本实验使用的OpenKE库来实现,这里对OpenKE中TransE代码进行解读。
OpenKE包clone
git clone -b OpenKE-PyTorch https://github.com/thunlp/OpenKE
通过git下载OpenKE的github仓库。
TransE代码解读
TransE以及其他多种知识表示模型的模型结构都是存储在 OpenKE/openke/module/model 路径下。
TransE initialize部分
该部分是根据TransE算法,初始化知识图谱的实体集和关系集。

对应代码为:
def __init__(self, ent_tot, rel_tot, dim = 100, p_norm = 1, norm_flag = True, margin = None, epsilon = None):
super(TransE, self).__init__(ent_tot, rel_tot)
# 初始化一些基本参数
self.dim = dim # 深度
self.margin = margin # 边缘
self.epsilon = epsilon
self.norm_flag = norm_flag #正则化标签
self.p_norm = p_norm
# 初始化实体和关系的embedding参数
self.ent_embeddings = nn.Embedding(self.ent_tot, self.dim)
self.rel_embeddings = nn.Embedding(self.rel_tot, self.dim)
# 如果margin/epsilon为None,则随机初始化为权重值,否则根据算法更新实体、关系的embedding
if margin == None or epsilon == None:
nn.init.xavier_uniform_(self.ent_embeddings.weight.data)
nn.init.xavier_uniform_(self.rel_embeddings.weight.data)
else:
self.embedding_range = nn.Parameter(
torch.Tensor([(self.margin + self.epsilon) / self.dim]), requires_grad=False
)
nn.init.uniform_(
tensor = self.ent_embeddings.weight.data,
a = -self.embedding_range.item(),
b = self.embedding_range.item()
)
nn.init.uniform_(
tensor = self.rel_embeddings.weight.data,
a= -self.embedding_range.item(),
b= self.embedding_range.item()
)
if margin != None:
self.margin = nn.Parameter(torch.Tensor([margin]))
self.margin.requires_grad = False
self.margin_flag = True
else:
self.margin_flag = False
TransE 评分函数
OpenKE代码实现的评分函数,在论文上基础上实现了L1/L2范式的一个选择在里面。
def _calc(self, h, t, r, mode):
# 如果norm_flag为True,则计算机h、r、t的L2范数
if self.norm_flag:
h = F.normalize(h, 2, -1)
r = F.normalize(r, 2, -1)
t = F.normalize(t, 2, -1)
# 如果mode不是正则化mode,则将向量复原
if mode != 'normal':
h = h.view(-1, r.shape[0], h.shape[-1])
t = t.view(-1, r.shape[0], t.shape[-1])
r = r.view(-1, r.shape[0], r.shape[-1])
# 根据是不是首次进入batch,不懂得score计算
if mode == 'head_batch':
score = h + (r - t)
else:
score = (h + r) - t
# 按需求维度将score展开
score = torch.norm(score, self.p_norm, -1).flatten()
return score
TransE训练步骤
TransE的反向传播流程主要是:获取embedding、计算评分函数、返回分数。
def forward(self, data):
# 获取当前batch的数据三元组
batch_h = data['batch_h']
batch_t = data['batch_t']
batch_r = data['batch_r']
mode = data['mode']
# 就batch转化为矩阵以便计算
h = self.ent_embeddings(batch_h)
t = self.ent_embeddings(batch_t)
r = self.rel_embeddings(batch_r)
# 计算评分函数
score = self._calc(h ,t, r, mode)
if self.margin_flag:
return self.margin - score
else:
return score
TransE预测
预测就是调用forward函数实现,并计算分数返回结果。
def predict(self, data):
score = self.forward(data)
if self.margin_flag:
score = self.margin - score
return score.cpu().data.numpy()
else:
return score.cpu().data.numpy()
参考博客与文献
[1] https://angxiao.blog.csdn.net/article/details/122223457
[2] https://zhuanlan.zhihu.com/p/508508180
[3] https://blog.csdn.net/minggelin1997/article/details/109024359
/article/details/122223457
[2] https://zhuanlan.zhihu.com/p/508508180
[3] https://blog.csdn.net/minggelin1997/article/details/109024359
[4] TransE paper