一文读懂 kafka 的事务机制
1 前言
大家好,我是明哥!
KAFKA 作为开源分布式事件流平台,在大数据和微服务领域都有着广泛的应用场景,是实时流处理场景下消息队列事实上的标准。用一句话概括,KAFKA 是实时数仓的基石,是事件驱动架构的灵魂。
但是一些技术小伙伴,尤其是一些很早就开始使用 KAFKA 的技术小伙伴们,对 KAFKA 的发展趋势和一些新特性,并不太熟悉,在使用过程中也踩了不少坑。
有鉴于此,我们会通过一系列 KAFKA 相关博文,专门讲述 KAFKA 的这些新特性。
本文是该系列文章之一,讲述 KAFAK 的事务机制。
一文读懂kafka的幂等生产者
以下是正文。
2 技术大背景-大数据发展趋势
在前期的一篇博文中,我们讲述过大数据的发展趋势之一,就是大数据与数据库日益融合的趋势。
从技术视角看大数据行业的发展趋势
-
早期大数据粗放式发展时,为了快速推向市场,丢失了很多传统数据库领域里良好的一些特性,(如事务ACID,如记录级别的增删改,如秒级甚至毫秒级的延迟),由此欠下了很多技术债。
-
近些年随着技术的进一步成熟,大数据在不断朝着更精细化的方向发展,参考了很多传统数据库的理念和技术,补齐了很多早期的技术债,使得大数据组件越来越像存储与计算分离的数据库,也进而推出了数据据湖仓/湖仓一体的理念。
-
技术债之一,就是大数据参考数据库实现了对事务 acid 特性的支持。具体到框架层面,数据湖三剑客 DeltaLake/Hudi/Iceberg, 还有本文的 KAFKA 事务机制,都是这个范畴。
3 KAFKA 的事务是什么
- KAFKA 的事务机制,是 KAFKA 实现端到端有且仅有一次语义(end-to-end EOS)的基础;
- KAFKA 的事务机制,涉及到 transactional producer 和 transactional consumer, 两者配合使用,才能实现端到端有且仅有一次的语义(end-to-end EOS);
- 当然kakfa 的 producer 和 consumer 是解耦的,你也可以使用非 transactional 的 consumer 来消费 transactional producer 生产的消息,但此时就丢失了事务 ACID 的支持;
- 通过事务机制,KAFKA 可以实现对多个 topic 的多个 partition 的原子性的写入,即处于同一个事务内的所有消息,不管最终需要落地到哪个 topic 的哪个 partition, 最终结果都是要么全部写成功,要么全部写失败(Atomic multi-partition writes);
- KAFKA的事务机制,在底层依赖于幂等生产者,幂等生产者是 kafka 事务的必要不充分条件;
- 事实上,开启 kafka事务时,kafka 会自动开启幂等生产者。
4 KAFKA 内部是如何支持事务的
4.1 为支持事务机制,KAFKA 引入了两个新的组件:Transaction Coordinator 和 Transaction Log
为支持事务机制,KAFKA 引入了两个新的组件:Transaction Coordinator 和 Transaction Log,如下图所示:
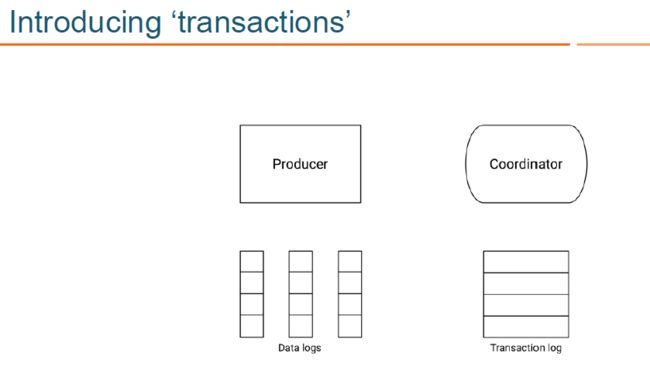
- transaction coordinator 是运行在每个 kafka broker 上的一个模块,是 kafka broker 进程承载的新功能之一(不是一个独立的新的进程);
- transaction log 是 kafka 的一个内部 topic(类似大家熟悉的 __consumer_offsets ,是一个内部 topic);
- transaction log 有多个分区,每个分区都有一个 leader,该 leade对应哪个 kafka broker,哪个 broker 上的 transaction coordinator 就负责对这些分区的写操作;
- 由于 transaction coordinator 是 kafka broker 内部的一个模块,而 transaction log 是 kakfa 的一个内部 topic, 所以 KAFKA 可以通过内部的复制协议和选举机制(replication protocol and leader election processes),来确保 transaction coordinator 的可用性和 transaction state 的持久性;
- transaction log topic 内部存储的只是事务的最新状态和其相关元数据信息,kafka producer 生产的原始消息,仍然是只存储在kafka producer指定的 topic 中。事务的状态有:“Ongoing,” “Prepare commit,” 和 “Completed” 。
- 实际上,每个 transactional.id 通过 hash 都对应到 了 transaction log 的一个分区,所以每个 transactional.id 都有且仅有一个 transaction coordinator 负责。
4.2 为支持事务机制,KAFKA 将日志文件格式进行了扩展,添加了控制消息 control batch
为支持事务机制,KAFKA 将底层日志文件的格式进行了扩展:
- 日志中除了普通的消息,还有一种消息专门用来标志事务的状态,它就是控制消息 control batch;
- 控制消息跟其他正常的消息一样,都被存储在日志中,但控制消息不会被返回给 consumer 客户端;
- 控制消息共有两种类型:commit 和 abort,分别用来表征事务已经成功提交或已经被成功终止;
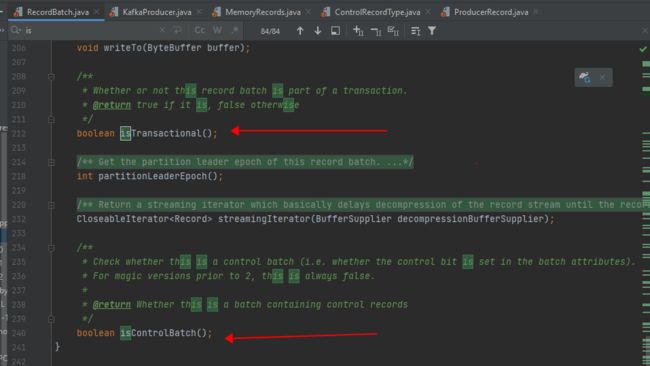
- RecordBatch 中 attributes 字段的第5位用来标志当前消息是否处于事务中,1代表消息处于事务中,0则反之;(A record batch is a container for records. )
- RecordBatch 中 attributes 字段的第6位用来标识当前消息是否是控制消息,1代表是控制消息,0则反之;
- 由于控制消息总是处于事务中,所以控制消息对应的RecordBatch 的 attributes 字段的第5位和第6位都被置为1;
参见源码:

4.3 在事务机制下,KAFKA 消息的读写流程
首先看下应用程序代码中 KAFKA transactional api 的调用顺序:

对应代码中的 KAFKA transactional api,其消息读写流程,示意图如下:
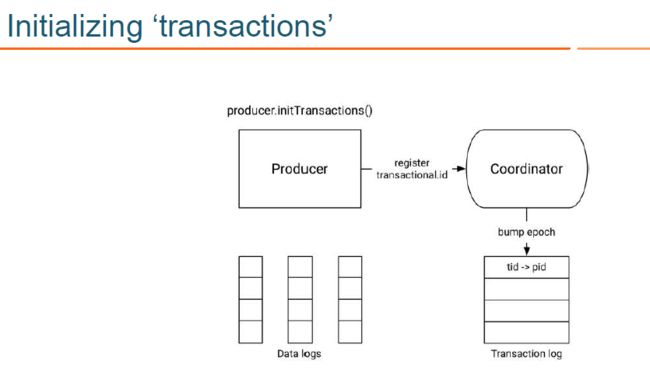
- KAFKA 生产者通过 initTransactions API 将 transactional.id 注册到 transactional coordinator:此时,此时 coordinator 会关闭所有有相同 transactional.id 且处于 pending 状态的事务,同时也会递增 epoch 来屏蔽僵尸生产者 (zombie producers). 该操作对每个 producer session 只执行一次.(producer.initTransaction())
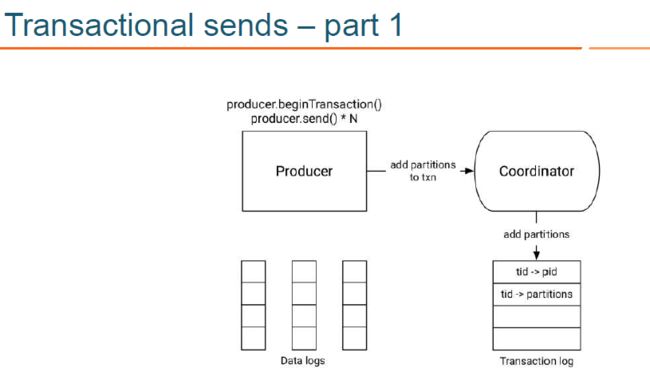

- KAFKA 生产者通过 beginTransaction API 开启事务,并通过 send API 发送消息到目标topic:此时消息对应的 partition 会首先被注册到 transactional coordinator,然后 producer 按照正常流程发送消息到目标 topic,且在发送消息时内部会通过校验屏蔽掉僵尸生产者(zombie producers are fenced out.(producer.beginTransaction();producer.send()*N;);


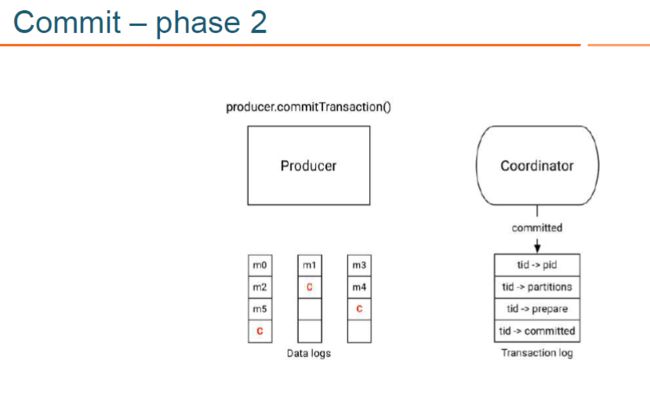
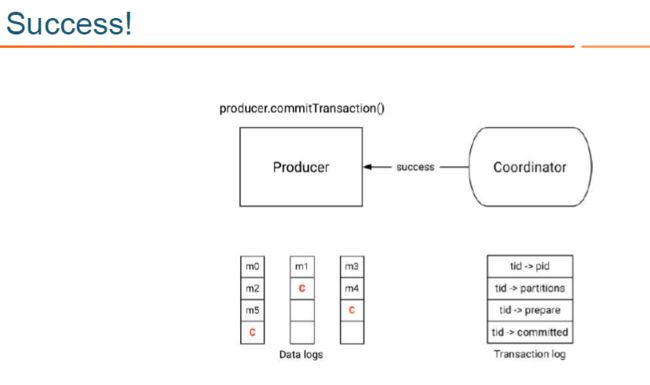
- KAFKA 生产者通过 commitTransaction API 提交事务或通过abortTransaction API回滚事务:此时会向 transactional coordinator 提交请求,开始两阶段提交协议 (producer.commitTransaction();producer.abortTransaction();
- 在两阶段提交协议的第一阶段,transactional coordinator 更新内存中的事务状态为 “prepare_commit”,并将该状态持久化到 transaction log 中;
- 在两阶段提交协议的第二阶段, coordinator 首先写 transaction marker 标记到目标 topic 的目标 partition,这里的 transaction marker,就是我们上文说的控制消息,控制消息共有两种类型:commit 和 abort,分别用来表征事务已经成功提交或已经被成功终止;
- 在两阶段提交协议的第二阶段, coordinator 在向目标 topic 的目标 partition 写完控制消息后,会更新事务状态为 “commited” 或 “abort”, 并将该状态持久化到 transaction log 中;
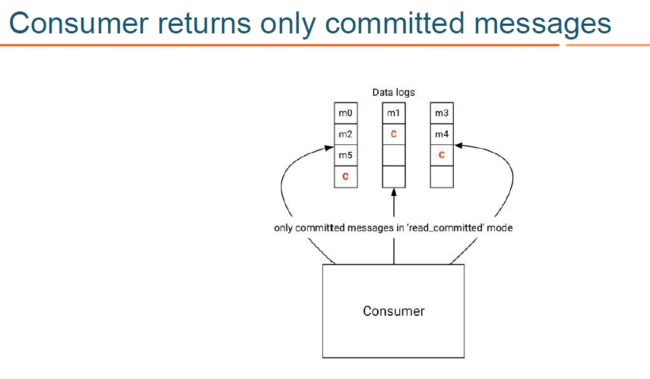
- KAFKA 消费者消费消息时可以指定具体的读隔离级别,当指定使用 read_committed 隔离级别时,在内部会使用存储在目标 topic-partition 中的 事务控制消息,来过滤掉没有提交的消息,包括回滚的消息和尚未提交的消息;
- 需要注意的是,过滤消息时,KAFKA consumer 不需要跟 transactional coordinator 进行 rpc 交互,因为 topic 中存储的消息,包括正常的数据消息和控制消息,包含了足够的元数据信息来支持消息过滤;
- KAFKA 消费者消费消息时也可以指定使用 read_uncommitted 隔离级别,此时目标 topic-partition 中的所有消息都会被返回,不会进行过滤。
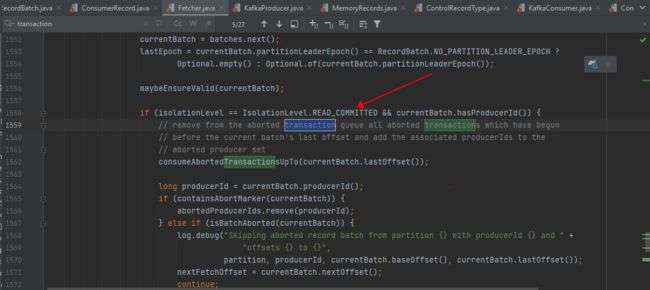
- 过滤消息的相关源码,可以参见 org.apache.kafka.clients.consumer.internals.Fetcher:
4.4 在事务机制下,KAFKA 对事务状态的容错
在事务机制下,KAFKA 在内部通过以下几点,实现了对事务状态的持久化存储,以及对 transaction coordinator 的容错:
- transaction coordinator 是运行在每个 kafka broker 上的一个模块,是 kafka broker 进程承载的新功能之一(不是一个独立的新的进程);
- transaction coordinator 将事务的状态保存在内存中,并持久化到 transaction log 中;
- transaction log 是 kakafa 的一个内部 topic(类似大家熟悉的 consumer_offsets ,是一个内部 topic);
- transaction log 有多个分区,每个分区都有一个 leader,该 leade对应哪个 kafka broker,则那个 broker上的 transaction coordinator 就负责对这些分区的写操作;
- transaction coordinator 是唯一负责读写 transaction log 的组件,如果某个 kafka broker 宕机的话,其负责的 transaction log 的 partitions 就没有了对应的 leader,此时会通过选举机制选举出一个新的 coordinator,该 coordinator 会从这些 transaction log partitions 在其它节点的副本中恢复状态数据;
- 正是由于 transaction log 是 kakfa 的一个内部 topic, 所以 KAFKA 可以通过内部的复制协议和选举机制(replication protocol and leader election processes),来确保对事务状态 transaction state 的持久化存储,以及对 transaction coordinator 的容错。
4.5 开启事务后,对 producer 和 consumer 的性能影响如何
-
开启事务后,producer 有些许写放大,这主要涉及到:
- 事务开始前, producer 需要将生产的消息的 partition 注册到 transaction coordinator, 这涉及到 rpt 调用;
- 事务结束时, transaction coordinator 需要注入 transaction marker 到消息对应的 Partition, 这也涉及到 rpt 调用;
- 事务进行过程中,transaction coordinator 需要将事务状态如 “prepare_commit” “complete_commit” 等持久化到 transaction log,这涉及到磁盘写;
- 但由于以上写操作的时间复杂度,更多是跟消息涉及到的分区个数相关,而不是跟消息的具体条数相关,且 KAFKA 通过 batch 机制尽量减小了 RPC 调用次数,所以对 Producer 的性能影响并不大;
- Confluent 官网有性能测试相关博文,其中讲到 “for a producer producing 1KB records at maximum throughput, committing messages every 100ms results in only a 3% degradation in throughput. Smaller messages or shorter transaction commit intervals would result in more severe degradation.“,即在他们的测试场景下,开启事务后性能只有3% 的下降;
-
开启事务后,对 consumer 的性能影响相对对 producer 的性能影响更小,consumer 仍然是轻量级高吞吐的,几乎没有性能影响:
- 这主要是因为,consumer 在 read_committed 模式下,只需要额外做一些消息的过滤,即过滤掉回滚了的事务的 message, 和 open 状态的事务的 message;
- 但过滤这些消息时,因为 topic 中存储的消息包括正常的数据消息和控制消息,这些消息包含了足够的元数据信息来支持消息过滤,所以KAFKA consumer 不需要跟 transactional coordinator 进行 rpc 交互;
- 同时,consumer 也不需要缓存读取的消息以等待事务的结束,而且由于底层仍然可以使用 zero-copy 机制来读取消息,所以相对于没有开启事务的 consumer,其性能几乎没有任何下降!
5 如何在应用程序中使用 KAFKA 事务
5.1 应用程序中使用 KAFKA 事务,涉及到 producer 和 consumer 的配置项的更改(当然 producer 和 consumer 的配置项的更改,可以更改配置文件也可以直接在代码中指定)。
- producer 配置项更改:
- enable.idempotence = true
- acks = “all”
- retries > 1 (preferably MAX_INT)
- transactional.id = ‘some unique id’
- consumer 配置项更改:
- 根据需要配置 isolation.level 为 “read_committed”, 或 “read_uncommitted”;
5.2 应用程序中使用 KAFKA 事务,涉及到应用程序代码调整,调用 transactional API
应用程序代码调整,调用 transactional API 大体顺序如下:

应用程序代码调整,示例伪代码(融合了Producer 和 Consumer)和关键步骤注释,如下:
KafkaProducer producer = createKafkaProducer(
“bootstrap.servers”, “localhost:9092”,
“transactional.id”, “my-transactional-id”); // the transactional.id is a must
/**After the producer.initTransactions() returns, any transactions started by another instance of a producer with the same transactional.id would have been closed and fenced off.
*/
producer.initTransactions();
/**
This specifies that the KafkaConsumer should only read non-transactional messages, or committed transactional messages from its input topics.
*/
KafkaConsumer consumer = createKafkaConsumer(
“bootstrap.servers”, “localhost:9092”,
“group.id”, “my-consumerGroup-id”,
"isolation.level", "read_committed");
consumer.subscribe(Collections.singleton(“inputTopic”));
/**
Consume some records, start a transaction, process the consumed records, write the processed records to the output topic, send the consumed offsets to the offsets topic, and finally commit the transaction. With the guarantees mentioned above, we know that the offsets and the output records will be committed as an atomic unit.
*/
while (true) {
ConsumerRecords records = consumer.poll(Long.MAX_VALUE);
producer.beginTransaction();
for (ConsumerRecord record : records)
producer.send(new ProducerRecord(“outputTopic”, record));
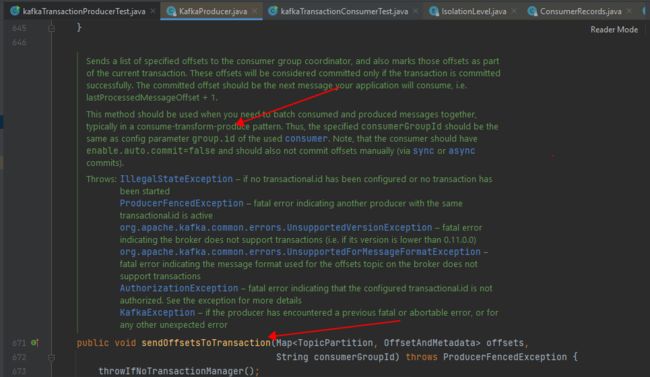
producer.sendOffsetsToTransaction(currentOffsets(consumer), my-consumerGroup-id); //This method should be used when you need to batch consumed and produced messages together, typically in a consume-transform-produce pattern.
producer.commitTransaction();
}
5.3 应用程序中使用 KAFKA 事务,如何选用一个全局一致的 transactional.id?
如上文所述,transactional.id 在 kafka 的事务机制中扮演了关键的角色,kafka 正是基于该参数来过滤掉僵尸生产者的 (fencing out zombies).
那么如何在跨 session 的众多 producer 中 (向同一个kafka集群中生产消息的 producer 有多个,这些 producer 还有可能会重启),选用一个全局一致的transactional.id,以互不影响呢?
大体的思路有两种:
- 一是通过一个统一的外部存储,来记录生产者使用的 transactional.id 和该生产者涉及到的topic-partition之间的映射关系;
- 二是通过某些静态编码机制来生成一个全局唯一的 transactional.id
在现实应用中,使用后者的更多些。比如 Kafka 生态的 Kafka Streams 使用的就是后者,FlinkKafkaProducer 使用的也是后者。
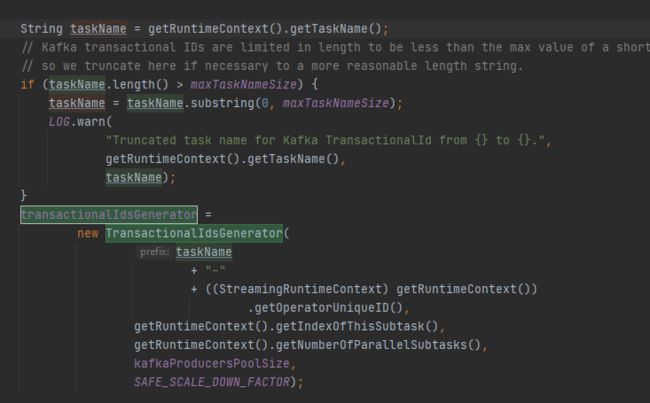
FlinkKafkaProducer 是根据 taskName+operatorUid+SubtaskIndex+Counter 来自动生成 transactional.id 的,如下源码所示:(FlinkKafkaProducer 是对 kafka transactional api 的更高级的封装和抽象,更易于使用,其底层融合了 Flink checkpoint 的两阶段提交协议和 Kafka transactional api 的两阶段提交协议,后续笔者会通过另一篇博客进行解读)。

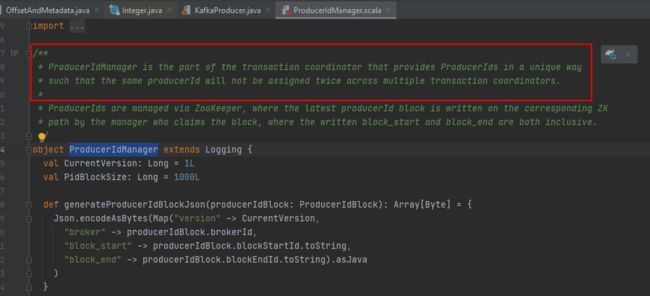
注意:使用 transactional API, 用户需要配置 transactional.id,但不需要配置 ProducerId,Kafka 内部会自动生成并维护一个全局唯一的 ProducerIds,如下源码所示:
6 知识总结
- KAFKA 的事务机制,是 KAFKA 实现端到端有且仅有一次语义(end-to-end EOS)的基础;
- KAFKA 的事务机制,涉及到 transactional producer 和 transactional consumer, 两者配合使用,才能实现端到端有且仅有一次的语义(end-to-end EOS);
- 通过事务机制,KAFKA 实现了对多个 topic 的多个 partition 的原子性的写入(Atomic multi-partition writes);
- KAFKA的事务机制,在底层依赖于幂等生产者,幂等生产者是 kafka 事务的必要不充分条件:用户可以根据需要,配置使用幂等生产者但不开启事务;也可以根据需要开启 kafka事务,此时kafka 会使用幂等生产者;
- 为支持事务机制,KAFKA 引入了两个新的组件: Transaction Coordinator 和 Transaction Log,其中 transaction coordinator 是运行在每个 kafka broker 上的一个模块,是 kafka broker 进程承载的新功能之一(不是一个独立的新的进程);而 transaction log 是 kakafa 的一个内部 topic;
- 为支持事务机制,kafka 将日志文件格式进行了扩展:日志中除了普通的消息,还有一种消息专门用来标志一个事务的结束,它就是控制消息 controlBatch,它有两种类型:commit和abort,分别用来表征事务已经成功提交或已经被成功终止。
- 开启了事务的生产者,生产的消息最终还是正常写到目标 topic 中,但同时也会通过 transaction coordinator 使用两阶段提交协议,将事务状态标记 transaction marker,也就是控制消息 controlBatch,写到目标 topic 中,控制消息共有两种类型 commit 和 abort,分别用来表征事务已经成功提交或已经被成功终止;
- 开启了事务的消费者,如果配置读隔离级别为 read-committed, 在内部会使用存储在目标 topic-partition 中的事务控制消息,来过滤掉没有提交的消息,包括回滚的消息和尚未提交的消息,从而确保只读到已提交的事务的 message;// 对于非事务生产者生产的消息,他们不处于事务中,使用 read-committed 隔离级别的开启了事务的消费者,可以正常读取这些消息;
- 开启了事务的消费者,过滤消息时,KAFKA consumer 不需要跟 transactional coordinator 进行 rpc 交互,因为 topic 中存储的消息,包括正常的数据消息和控制消息,包含了足够的元数据信息来支持消息过滤;
- 当然 kakfa 的 producer 和 consumer 是解耦的,你也可以使用非 transactional consumer 来消费 transactional producer 生产的消息,此时目标 topic-partition 中的所有消息都会被返回,不会进行过滤,此时也就丢失了事务 ACID 的支持;
更多细节,可以参考:KIP-98:Exactly Once Delivery and Transactional Messaging
!关注不迷路~ 各种福利、资源定期分享!欢迎小伙伴们扫码添加明哥微信,后台加群交流学习。
